机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法
非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括:
- 市场划分(Market Segmentation)
- 社交网络分析(Social Network Analysis)
- 管理计算机集群(Organize Computer Clusters)
- 天文学数据分析(Astronomical Data Analysis)
K-Means算法属于非监督式学习的一种,算法的输入是:训练数据集$\{x^{(1)},x^{(2)},\ldots, x^{(m)}\}$(其中$x^{(i)}\in R^{n}$)和聚类数量$K$(将数据划分为$K$类);算法输出是$K$个聚类中心$\mu_1, \mu_2, \ldots, \mu_K$和每个数据点$x^{(i)}$所在的分类。
K-Means算法步骤
- 随机初始化$K$个聚类中心(cluster centroid) $\mu_1, \mu_2, \ldots, \mu_K$
- Cluster Assignment: 对于每个数据点$x^{(i)}$,寻找离它最近的聚类中心,将其归入该类;即$c^{(i)}=\min\limits_k||x^{(i)}-\mu_k||^2$,其中$c^{(i)}$表示$x^{(i)}$所在的类
- Move Centroid: 更新聚类中心$u_k$的值为所有属于类$k$的数据点的平均值
- 重复2、3步直到收敛或者达到最大迭代次数
 图1 K-Means算法示例
图1 K-Means算法示例
K-Means算法的优化目标
用$\mu_{c^{(i)}}$表示第$i$个数据点$x^{(i)}$所在类的中心,则K-Means优化的代价函数为$$J(c^{(1)},\ldots,c^{(m)},\mu_1,\ldots,\mu_K)=\frac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}-\mu_{c^{(i)}}||^2$$希望找到最优参数使得该函数最小化,即$$\min\limits_{\substack{c^{(1)},\ldots,c^{(m)} \\ \mu_1,\ldots,\mu_K}}J(c^{(1)},\ldots,c^{(m)},\mu_1,\ldots,\mu_K)$$
需要注意的问题
- 随机初始化:常用的初始化方法是,从训练数据点中随机选择$K$($K < m$)个数据点,作为初始的聚类中心$\mu_1, \mu_2, \ldots, \mu_K$
- 局部最优:算法聚类的性能与初始聚类中心的选择有关,为避免陷入局部最优(如图2所示),应该运行多次(50次)取使得$J$最小的结果
- $K$值选择:Elbow方法,绘制$J$随$K$的变化曲线,选择下降速度突然变慢的转折点作为K值;对于转折不明显的曲线,可根据K-Means算法后续的目标进行选择。
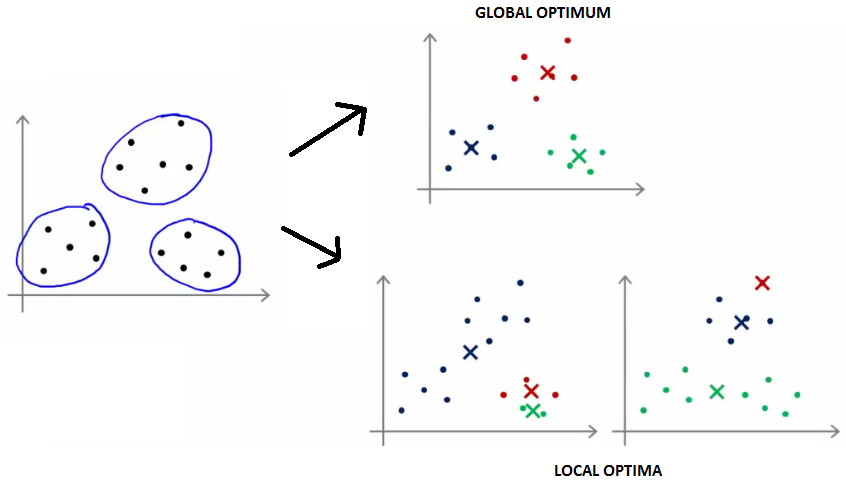
图2 K-Means算法的全局最优解和局部最优解
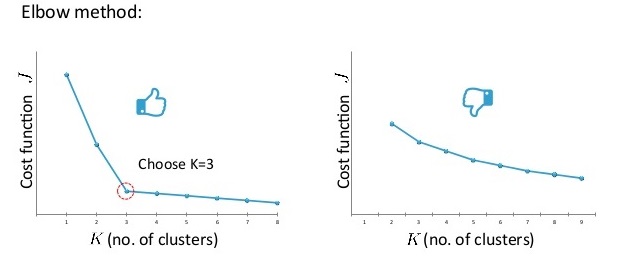 图3 用Elbow方法选择K值的情况(左)和Elbow法不适用的情况(右)
图3 用Elbow方法选择K值的情况(左)和Elbow法不适用的情况(右)
PCA降维算法
动机
数据压缩:将高维数据(n维)压缩为低维数据(k维)
数据可视化:将数据压缩到2维/3维方便可视化
PCA问题形式化
如果需要将二维数据点,压缩为一维数据点,我们需要找到一个方向,使得数据点到这个方向上投射时的误差最小(即点到该直线的距离最小);更一般地,如果需要将$n$维的数据点压缩到$k$维,我们需要找到$k$个新的方向$u^{(1)}, u^{(2)}, \ldots, u^{(k)}$使得数据点投射到每个方向$u^{(i)}$时的误差最小。
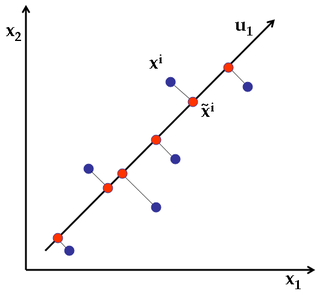
图4 PCA实例,将2维数据点压缩为1维数据点,找到新的方向$u_1$,使得投射误差(图中的垂线距离如$x^i$到${\widetilde x}^i$)最小
注意:PCA和线性回归的区别,PCA是保证投射的误差(图5右的黄线)最小,而线性回归是保证沿$y$方向的误差(图5左的黄线)最小.
 图5 线性回归和PCA优化目标的区别
图5 线性回归和PCA优化目标的区别
PCA算法步骤
1. 数据预处理:mean normalization:$\mu_j = \frac{1}{m}\sum\limits_{i=1}^{m}x_j^{(i)}, x_j^{(i)}=x_j-\mu_j$;feature scaling:(可选,不同特征范围差距过大时需要) , $x_j^{(i)}=\frac{x^{(i)}-\mu_j}{\sigma_j}$
2. 计算协方差矩阵(Convariance Matrix) $$\Sigma=\frac{1}{m}\sum\limits_{i=1}^{m}x^{(i)}(x^{(i)})^T \quad \text{or} \quad \Sigma = \frac{1}{m}X^TX$$
3. 计算协方差矩阵$\Sigma$的特征向量 [U, S, V] = svd(Sigma)
4. 选择U矩阵的前k个列向量作为k个主元方向,形成矩阵$U_{reduce}$
5. 对于每个原始数据点$x$($x\in R^n$),其降维后的数据点$z$($z \in R^k$)为 $z=U_{reduce}^T x$
应用PCA
重构数据:对于降维后k维数据点z,将其恢复n维后的近似点为 $x_{apporx}(\approx x)=U_{reduce}z$
选择k值
- 平均投射误差(Average square projection error):$\frac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}-x^{(i)}_{approx}||^2$
- total variation: $\frac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}||^2$
- 选择最小的k值使得 $\frac{\frac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}-x^{(i)}_{approx}||^2}{\frac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}||^2} \leq 0.01(0.05)$,也可以使用SVD分解后的S矩阵进行选择 $1-\frac{\sum\limits_{i=1}^{k}S_{ii}}{\sum\limits_{i=1}^{n}S_{ii}}\leq 0.01(0.05)$
应用PCA的建议
- 用于加速监督式学习:(1) 对于带标签的数据,去掉标签后进行PCA数据降维,(2)使用降维后的数据进行模型训练,(3) 对于新的数据点,先PCA降维得到降维后数据,带入模型获得预测值。注:应仅用训练集数据进行PCA降维获取映射$x^{(i)}\rightarrow z^{(i)}$,然后将该映射(PCA选择的主元矩阵$U_{reduce}$)应用到验证集和测试集
- 不要用PCA阻止过拟合,用regularization。
- 在使用PCA之前,先用原始数据进行模型训练,如果不行,再考虑使用PCA;而不要上来直接使用PCA。
参考文献
[1] Andrew Ng Coursera 公开课第八周
[2] 漫谈Clustering:k-means. http://blog.pluskid.org/?p=17
[3] k-means clustering in a GIF. http://www.statsblogs.com/2014/02/18/k-means-clustering-in-a-gif/
[4] Wikipedia: Principal component analysis. https://en.wikipedia.org/wiki/Principal_component_analysis
[5] Explained Visually: Principal component analysis http://setosa.io/ev/principal-component-analysis/
机器学习公开课笔记(8):k-means聚类和PCA降维的更多相关文章
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 -- Mixtures of Gaussians and the EM algorithm
网易公开课,第12,13课 notes,7a, 7b,8 从这章开始,介绍无监督的算法 对于无监督,当然首先想到k means, 最典型也最简单,有需要直接看7a的讲义 Mixtures of G ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- 机器学习公开课笔记(5):神经网络(Neural Network)——学习
这一章可能是Andrew Ng讲得最不清楚的一章,为什么这么说呢?这一章主要讲后向传播(Backpropagration, BP)算法,Ng花了一大半的时间在讲如何计算误差项$\delta$,如何计算 ...
- 机器学习公开课笔记(4):神经网络(Neural Network)——表示
动机(Motivation) 对于非线性分类问题,如果用多元线性回归进行分类,需要构造许多高次项,导致特征特多学习参数过多,从而复杂度太高. 神经网络(Neural Network) 一个简单的神经网 ...
随机推荐
- 关于python中PIL的安装
python 的PIL安装是一件很蛋痛的事, 如果你要在python 中使用图型程序那怕只是将个图片从二进制流中存盘(例如使用Scrapy 爬网存图),那么都会使用到 PIL 这库,而这个库是出名的难 ...
- nodejs学习之文件上传
最近要做个图片上传的需求,因为服务端春节请假回家还没来,所以就我自己先折腾了一下,大概做出来个效果,后台就用了nodejs,刚开始做的时候想网上找一下资料,发现大部分资料都是用node-formida ...
- js中的DOM操作(2)
1.表格的更加与删除 <!DOCTYPE html> <html> <head> <title>表格操作</title> <style ...
- EntityFramework_MVC4中EF5 新手入门教程之四 ---4.在EF中创建更复杂的数据模型
在以前的教程你曾与一个简单的数据模型,由三个实体组成.在本教程中,您将添加更多的实体和关系,并通过指定格式. 验证和数据库映射规则,您将自定义数据模型.你会看到自定义的数据模型的两种方式: 通过添加属 ...
- java线程技术6_线程的挂起和唤醒[转]
转自:http://blog.chinaunix.net/uid-122937-id-215913.html 1. 线程的挂起和唤醒 挂起实际上是让线程进入“非可执行”状态下,在这个状态下C ...
- 详解js中的闭包
前言 在js中,闭包是一个很重要又相当不容易完全理解的要点,网上关于讲解闭包的文章非常多,但是并不是非常容易读懂,在这里以<javascript高级程序设计>里面的理论为基础.用拆分的方式 ...
- javascript-XMLHttpRequest
JS方法: var xmlhttp;//一定注意是写在外面的全局变量,我调了一个上午才发现. function verify(){ //使用dom方式获取文本框中的值 var userName=doc ...
- Java-TreeSet
如下: package 集合类.Set类; /** * Set不允许重复数据 */ /** * TreeSet 是用来进行集合排序的,请注意他和LinkedHashSet的区别. TreeSet是按照 ...
- webservice配置
服务端配置:第一步:引用jar包commons-httpclient.jarcommons-logging.jarjdom-10.jarwsdl4j-1.6.1.jarxbean-spring-2.8 ...
- 51NOD 1400 序列分解
传送门:1400 序列分解序列分解 基准时间限制:1s 空间限制:131072 KBKB131072 KB 1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题1 秒 空间限制:13 ...