【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
广东职业技术学院 欧浩源
1、引言
网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL、MongoDB和Redis等。对于爬取返回为JSON格式的数据,选择NoSQL非关系型数据库的MongoDB来存储会容易很多。在本文中,首先介绍MongoDB数据库的安装与启动,然后讲述该数据库的基本操作,接着用Python语句操作该数据库,最后将“豆瓣电影TOP250”爬虫搜集的数据存到到该数据库中,由浅入深,从理论到实践,全面掌握MongoDB数据库的基本应用。
2、什么是MongoDB数据库?
MongoDB是一款由C++语言编写,基于分布式文件存储的NoSQL数据库,具有免费、操作简单、面向文档存储、自动分片、可扩展性高、查询功能强大等特点,旨在为Web应用提供可扩展的高性能数据存储解决方案。MongoDB将数据存储为一个文档,数据结构由键值对(key--value)组成。MongoDB的文档类似于JSON对象,如果你不懂JSON对象的话,也可以理解为Python中的字典。
3、MongoDB的下载与安装
【1】进入官方网站:www.mongodb.com,进入download页面,选择“community sever”标签,下载windows的msi版本。
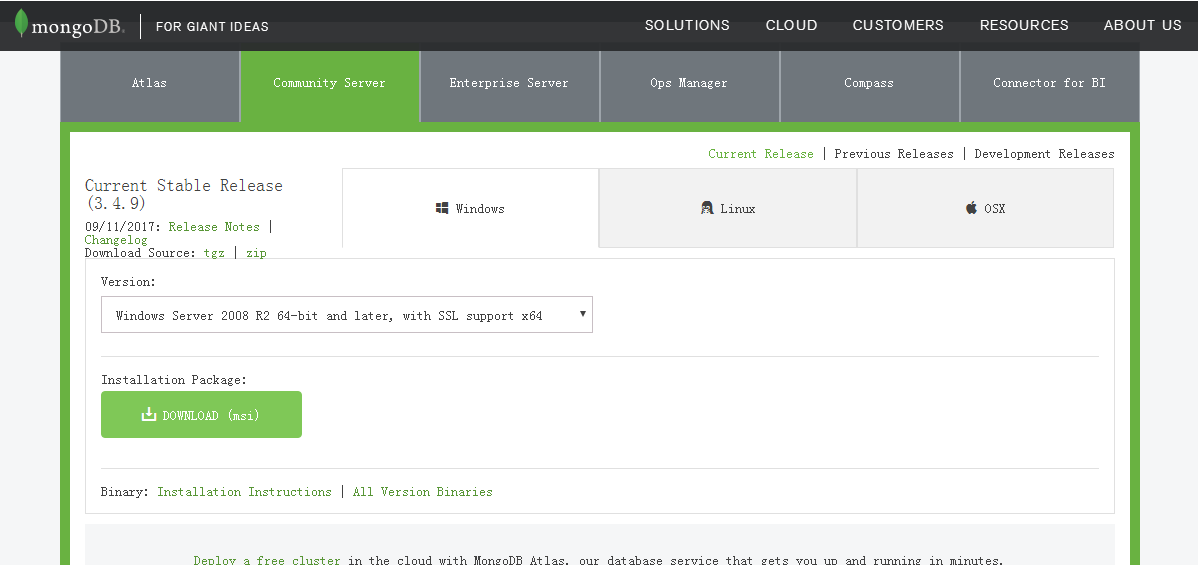
【2】双击下载后的安装程序,选择“Complete”安装完整版本。这个过程非常简单,除了“下一步”就是最后的“完成”。完成后,程序默认安装在“C:\Program Files\MongoDB中”。
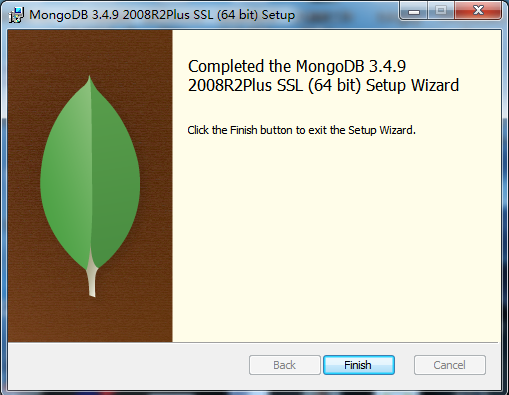
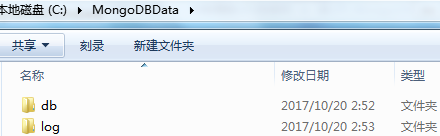
【3】在C盘创建两个文件夹,分别为:"C:\MongoDBData\db"和"C:\MongoDBData\log",作为数据和日志的文件夹。db文件夹存放MongoDB的数据库,log文件夹存放数据库的操作记录。在log文件夹中创建一个日志文件mongodb.log。
【4】创建MongoDB的数据库文件。以管理员身份打开cmd控制台,将当前路径切换到MongoDB的安装目录的bin目录下,即“C:\Program Files\MongoDB\Server\3.4\bin”。在路径下输入“mongod.exe --dbpath c:\MongoDBData\db”。该命令将MongoDB的数据库文件创建到已经建好的db文件夹中。如果创建成功,可以看到具体的信息。
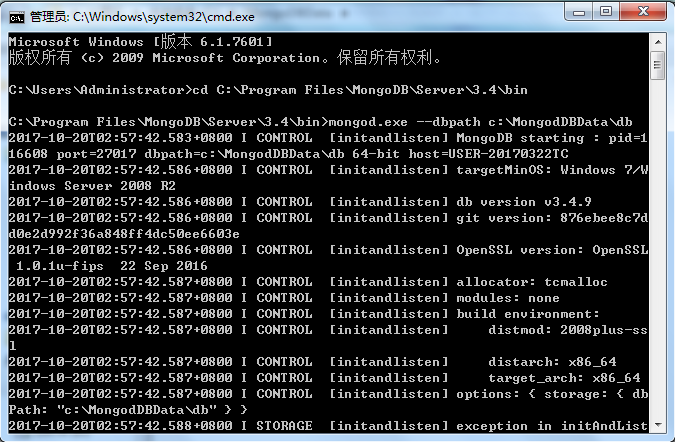
【5】MongoDB主要的启动方式有两种:以程序的方式打开和以Windows服务的方式打开。在实际使用中,用Windows服务的方式打开会比较方便。首先以管理员的身份运行cmd控制台,并且把当前目录切换到MongoDB安装目录的bin目录下,然后输入:
mongod.exe --logpath "C:\MongoDBData\log\mongodb.log" --logappend --dbpath "c:\MongoDBData\db" --serviceName "MongoDB" --install
通过这个指令安装Windows服务运行模式,其中“MongoDB”为服务器名称。然后通过输入“net start MongoDB”指令,启动MongoDB。
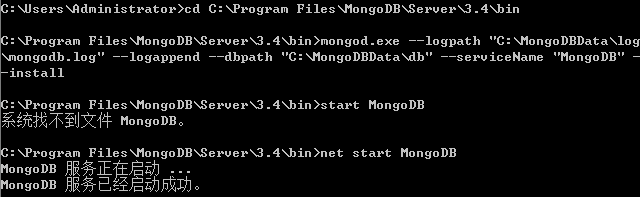
如果看到上述的信息,则表示MongoDB已经成功启动了。如果你打开计算机管理系统的服务模块,能清楚看到MongoDB已经启动了。
到这里,关于MongoDB的下载、安装、配置、启动已经全部完成,接下来就可以自由的使用了。在下一次打开电脑的时候,并不需要再次输入配置和启动命令,直接进入MongoDB安装目录下的bin文件夹,双击“Mongo.exe”即可打开数据库的交互窗口,即Mongo Shell。
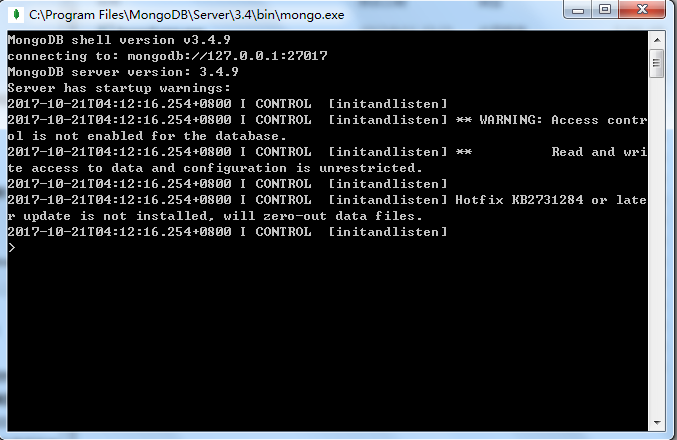
为了测试MongoDB是否打开成功,可在提示符下输入“show dbs”查看所有的数据库。如果成功的话,你能看到以下的返回信息。
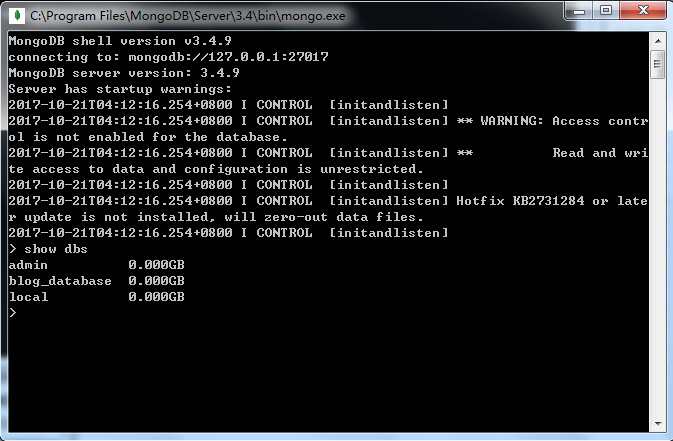
5、MongoDB的基本操作
【1】查看当前数据库名称:db
【2】查看所有数据库名称:show dbs
【3】切换数据库:use 数据库名称
如果数据不存在,则则指向数据库,但不创建,直到插入数据或创建集合时,数据库才被创建。默认的数据库为test。如果你没有创建新的数据库,集合将存放在test数据库中。
【4】删除当前数据库:db.dropDatabase()
删除当前指向的数据库,如果数据库不存在,则什么也不做。
【5】创建集合:db.createCollection(name ,option)
不限制集合大小,如:db.createCollection("student")
限制集合大小,如:db.createCollection("student",{capped:true,size:10})
【6】查看当前数据库的集合:show collections
【7】删除集合:db.集合名称.drop()
例1:查看当前的数据库,并切换到“spider01”数据,然后在该数据库中创建集合“student”,最后查看当前数据库中的集合。
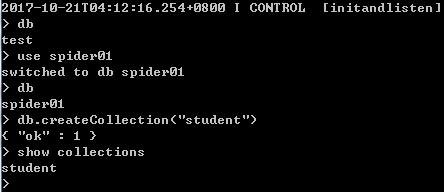
【8】插入数据:db.集合名称.insert(document)
如:db.stu.insert({name:"Marry", age:21})
【9】保存数据:db.集合名称.save(document)
【10】全文档数据更新:
db.集合名称.update(
<query>,
<update>,
{multi : <boolean>}
)
第1个参数:查询条件,即要修改那些数据。
第2个参数:更新内容,即改为什么数据。
第3个参数:可选,是否多行更新,默认为false,更新一行。
【11】指定属性更新:
语法如上,通过操作符$set,指定更新的属性。
【12】删除数据:
db.集合名称.update(
<query>,
{justone : <boolean>}
)
第1个参数:查询条件,要删除的数据。
第2个参数:默认为false,删除多条数据。
【13】简单查询:db.集合名称.find({条件文档})
【14】返回第一个查询结果:db.集合名称.findOne({条件文档})
【15】将结果格式化输出:db.集合名称.find({条件文档}).pretty()
【16】查询集合的记录总数:db.集合名称.find().count()
例2:向“student”集合中插入三条数据,通过简单查询显示该集合的数据。
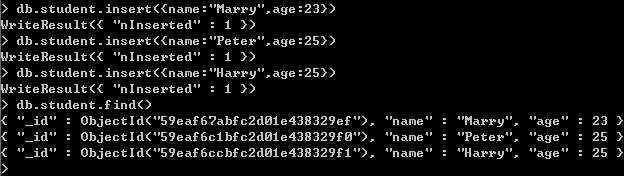
例3:将“name”为“Peter”的文档删除,将“name”为“Marry”的“age”改为65,通过查询,将查询结果格式化输出,最后将所有文档删除,在通过简单查询确认。
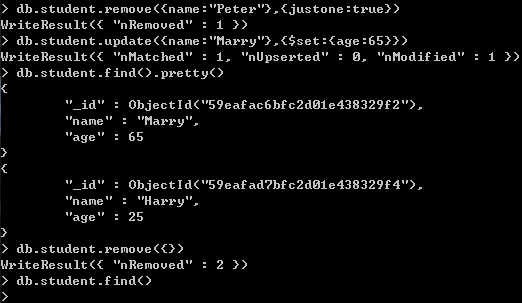
【17】退出MongoDB数据库:quit()
6、PyMongo库的安装与引入
按装PyMongo库就可以使用Python语言操作MongoDB数据库了。其安装方式非常简单:
pip install pymongo
安装完成后,从pymongo中引入MongoClient:
from pymongo import MongoClient
然后,就可以使用Python对MongoDB数据进行各种操作了。
7、PyMongo库的基本操作
操作MongoDB数据库之前,首先需要连接MongoDB客户端,然后连接数据库,如果该数据库不存在,就会创建一个数据库;接着选择数据集合,如果该集合不存在,也会创建一个;然后才能进行数据操作。
例4:连接MongoDB客户端,然后连接数据库“spider01”,选择数据集合"student"。
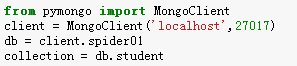
【1】插入单条记录:insert_one()
例5:向"student"集合中插入一条学生记录。
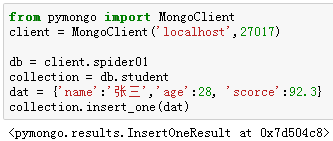
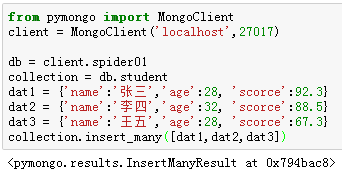
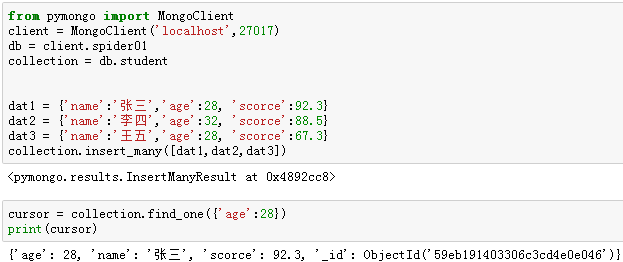
【2】插入多条记录:insert_many()
在该方法中,要插入的记录以列表的形式进行传递。
例6:向"student"集合中插入三条学生记录。
【3】查找单条记录:find_one()
例7:查询"student"集合中,age为28的记录中的第一条。
【4】查找多条记录:find_many()
例8:查询"student"集合中,age为28的所有记录。
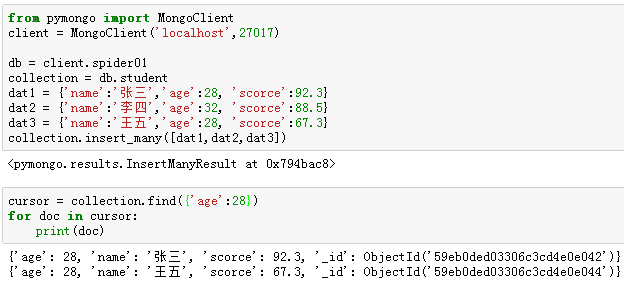
【5】查询所有记录:find()
例9:查询"student"集合的所有记录。
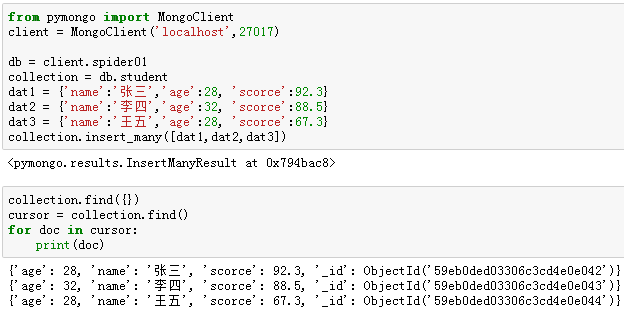
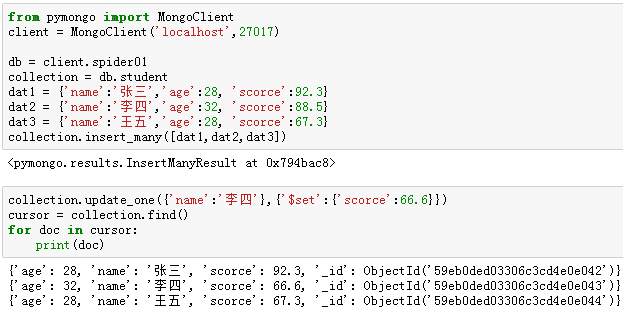
【6】更新单条记录:update_one()
例10:将"student"集合中,name为“李四”的记录的“scorce”的值修改为66.6。
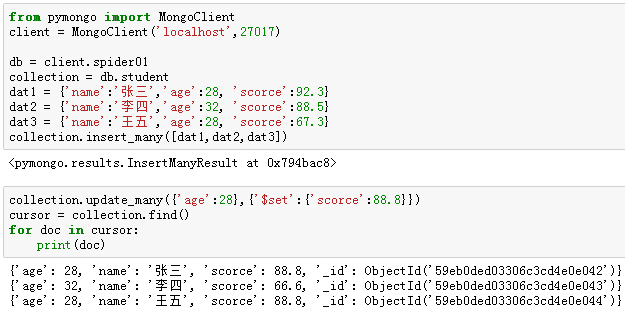
【7】更新多条记录:update_many()
例11:将"student"集合中,age为28的记录的“scorce”的值修改为88.8。
【8】删除单条记录:delete_one()
例12:将"student"集合中,name为"李四"的记录删除。

【9】删除多条记录:delete_many()
例13:将"student"集合的所有记录删除。

熟练掌握了数据库的增、删、查、改的基本操作之后,再去学习和提升就不会存在太大的障碍了。实际上使用pymongo库来操作数据库是非常简单的,将来碰到更加复杂的需求,在网络上查一下官方文档或者技术博客,应该都能很快的顺利解决。
7、MongoDB的爬虫应用
在【网络爬虫入门01】中,应用Requests和BeautifulSoup技术实现了从“豆瓣电影TOP250”中将电影名称、豆瓣评分和相关链接爬取下来,并保存到文本文件中的网络爬虫。在这里我们对其进行升级一下,把爬取下来的目标数据存储到MongoDB数据库中,其实现的思路很简单:
<1> 引入pymogo库。
<2>连接服务器和数据库。
<3>选择数据集合进行增、删、查、改操作。
从实现代码来看,把爬取到的数据存储到数据库只需要一行代码。这个网络爬虫跟MongoDB数据库相关的代码,也就下面几句:
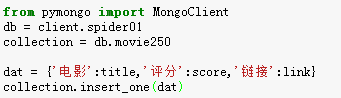
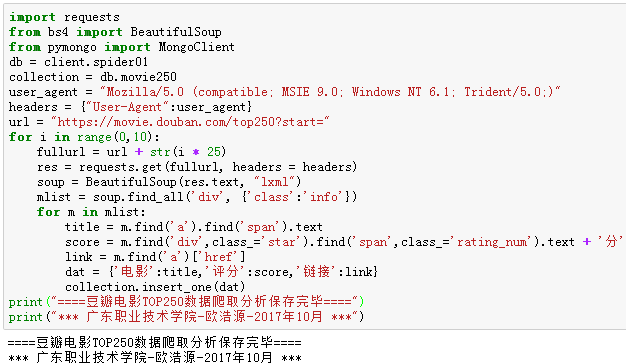
整个网络爬虫的实现代码如下:
到底爬虫获取的数据有没有存储到数据库中指定的集合中呢?我们可以打开mongo.exe的交互终端进行查看。

如果你觉得上面通过交互终端进行数据查询很不方便,你也可以利用Python语句编写代码,查询集合中“评分”为“9.5分”的记录。其实现代码也相当的简洁:

如果要将上述代码放到爬虫里面,在程序将数据向数据库存储完毕之后,再读出其中“评分”为“9.5分”的记录作为验证。整个代码可以这样实现:

8、小结
在大数据处理时代中,MongoDB的地位将会非常突出,关键它学起来也不难,如果结合Python语句进行开发应用,其效率是非常高的。在网络爬虫的应用中,对于关联度很低、结构很松散的数据,特别是一些JSON格式的数据,使用MongoDB来存储数据那是再完美不过了。
9、附件:源码
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
db = client.spider01
collection = db.movie250
user_agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;)"
headers = {"User-Agent":user_agent}
url = "https://movie.douban.com/top250?start="
for i in range(0,10):
fullurl = url + str(i * 25)
res = requests.get(fullurl, headers = headers)
soup = BeautifulSoup(res.text, "lxml")
mlist = soup.find_all('div', {'class':'info'})
for m in mlist:
title = m.find('a').find('span').text
score = m.find('div',class_='star').find('span',class_='rating_num').text + '分'
link = m.find('a')['href']
dat = {'电影':title,'评分':score,'链接':link}
collection.insert_one(dat)
print("====豆瓣电影TOP250数据爬取分析保存完毕====")
cursor = collection.find({'评分':'9.5分'})
for doc in cursor:
print(doc)
print("*** 广东职业技术学院-欧浩源-2017年10月 ***")
【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用的更多相关文章
- 分布式文件存储数据库 MongoDB
MongoDB 简介 Mongo 并非芒果(Mango)的意思,而是源于 Humongous(巨大的:庞大的)一词. MongoDB 是一个基于分布式文件存储的 NoSQL 数据库.由 C++ 语言编 ...
- .Net平台下,分布式文件存储的实现
遇到的问题 对于Web程序,使用一台服务器的时候,客户端上传的文件一般也都是存储在这台服务器上.但在集群环境中就行不通了,如果每个服务器都存储自己接受到的文件,就乱套了,数据库中明明有这个附件的记录, ...
- 分布式文件存储:FastDFS简单使用与原理分析
引言 FastDFS 属于分布式存储范畴,分布式文件系统 FastDFS 非常适合中小型项目,在我接手维护公司图片服务的时候开始接触到它,本篇文章目的是总结一下 FastDFS 的知识点. 用了 2 ...
- MongoDB ----基于分布式文件存储的数据库
参考: http://www.cnblogs.com/huangxincheng/category/355399.html http://www.cnblogs.com/daizhj/category ...
- 分布式文档存储数据库 MongoDB
MongoDB 详细介绍 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bjson格式,因此可以 ...
- 分布式文件存储FastDFS(七)FastDFS配置文件具体解释
配置FastDFS时.改动配置文件是非常重要的一个步骤,理解配置文件里每一项的意义更加重要,所以我參考了大神的帖子,整理了配置文件的解释.原帖例如以下:http://bbs.chinaunix.net ...
- mogilefs分布式文件存储
MogileFS是一个开源的分布式文件存储系统,由LiveJournal旗下的Danga Interactive公司开发.Danga团队开发了包括 Memcached.MogileFS.Perlbal ...
- (转) 分布式文件存储FastDFS(七)FastDFS配置文件详解
http://blog.csdn.net/xingjiarong/article/details/50752586 配置FastDFS时,修改配置文件是很重要的一个步骤,理解配置文件中每一项的意义更加 ...
- Centos7部署分布式文件存储(Fastdfs)
目录 FastDFS介绍 楼主目标:前可H5撩妹,后可Linux搞运维 环境:Centos7 软件: 软件链接: 安装前所有准备,上传软件到Centos7上的/opt的目录下 安装依赖软件和类库(安装 ...
随机推荐
- 201521123051《Java程序设计》第八周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 1.2 选做:收集你认为有用的代码片段 集合与泛型综合示例 import java.util.ArrayLis ...
- 201521123053《Java程序设计》第八周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 2. 书面作业 1.List中指定元素的删除(题目4-1) 1.1 实验总结 答:先贴上主要代码: priva ...
- ArrayList和LinkedList区别及性能测试
ArrayList和LinkedList是Java Lis接口的2个实现.它们的区别如下表所示: 底层结构 强项 弱项 ArrayList 数组 随机访问get和set 插入删除 LinkedList ...
- 再起航,我的学习笔记之JavaScript设计模式22(访问者模式)
访问者模式 概念介绍 访问者模式(Visitor): 针对于对象结构中的元素,定义在不改变该对象的前提下访问结构中元素的新方法 解决低版本IE兼容性 我们来看下面这段代码,这段代码,我们封装了一个绑定 ...
- apache: eclipse的tomcatPluginV插件下载
Sysdeo Eclipse Tomcat Launcher plugin Plugin features Support and contributions Download Installatio ...
- MongoDB中的映射,限制记录和记录拼排序 文档的插入查询更新删除操作
映射 在 MongoDB 中,映射(Projection)指的是只选择文档中的必要数据,而非全部数据.如果文档有 5 个字段,而你只需要显示 3 个,则只需选择 3 个字段即可. find() 方法 ...
- 【个人笔记】《知了堂》前端mySql基础
指定列之后添加: ALTER TABLE 表名 ADD 添加的新列名 INT AFTER 指定列之后 第一个位置: ALTER TABLE 表名 ADD 添加的新列名 varchar(20) AFTE ...
- mybatis typehandler
建立TypeHandler 我们知道java有java的数据类型,数据库有数据库的数据类型,那么我们在往数据库中插入数据的时候是如何把java类型当做数据库类型插入数据库,在从数据库读取数据的时候又是 ...
- Just Finish it up UVA - 11093
Just Finish it up Time Limit: 3000MS Memory Limit: Unknown 64bit IO Format: %lld & %llu [Sub ...
- Request.QueryString("id")与Request("id")区别
Request从几个集合取数据是有顺序的,从前到后的顺序依次是 QueryString,Form,最后是ServerVariables.Request对象按照这样的顺序依次搜索这几个集合中的变量,如果 ...