hadoop+hive+spark搭建(二)
上传hive软件包到任意节点
一、安装hive软件
解压缩hive软件包到/usr/local/hadoop/目录下

重命名hive文件夹

在/etc/profile文件中添加环境变量
export HIVE_HOME=/usr/local/hadoop/hive
export PATH=$HIVE_HOME/bin:$PATH
运行命令source /etc/profile
使用mysql作为数据库时需要安装mysql
在mysql中创建hive用户,数据库等
退出mysql
拷贝mysql-connector-java.jar到hive目录下lib/中
二、修改配置文件
修改hive目录中conf/hive-default.xml.template文件为conf/hive-site.xml
在conf目录中修改配置文件hive-site.xml
(使用默认数据库)
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/iotmp</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hive/iotmp</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
三、运行hive
输入命令格式化数据库
默认数据库 schematool -initSchema -dbType derby
mysql数据库 schematool -initSchema -dbType mysql
启动hive
输入命令hive
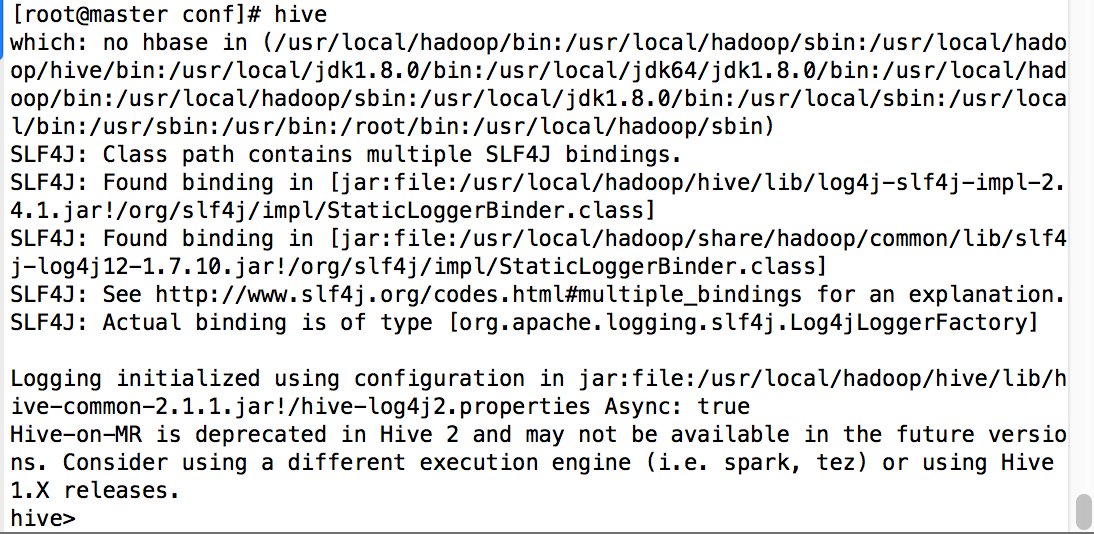
hive安装完毕
hadoop+hive+spark搭建(二)的更多相关文章
- hadoop+hive+spark搭建(一)
1.准备三台虚拟机 2.hadoop+hive+spark+java软件包 传送门:Hadoop官网 Hive官网 Spark官网 一.修改主机名,hosts文件 主机名修改 hostnam ...
- hadoop+hive+spark搭建(三)
一.spark安装 因为之前安装过hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- hadoop和spark搭建记录
因玩票需要,使用三台搭建spark(192.168.1.10,192.168.1.11,192.168.1.12),又因spark构建在hadoop之上,那么就需要先搭建hadoop.历经一个两个下午 ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 分别使用Hadoop和Spark实现二次排序
零.序(注意本部分与标题无太大关系,可直接调至第一部分) 既然没用为啥会有序?原因不想再开一篇文章,来抒发点什么感想或者计划了,就在这里写点好了: 前些日子买了几本书,打算学习和研究大数据方面的知识, ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
- 配置Hadoop,hive,spark,hbase ————待整理
五一一天在家搭建好了集群,要上班了来不及整理,待下周周末有时间好好整理整理一个完整的搭建hadoop生态圈的集群的系列 若出现license information(license not accep ...
- Hadoop集群搭建(二)~centos6.8的安装
这篇记录在创建好的虚拟机中安装centos6.8 1,在虚拟机界面-选择编辑虚拟机设置 2,CD/DVD,选择使用ISO映像文件,找到安装包的位置,确定 3,回到虚拟机的界面,开启此虚拟机 4,安装 ...
随机推荐
- 剑指 offer代码解析——面试题39推断平衡二叉树
题目:输入一颗二叉树的根结点.推断该树是不是平衡二叉树. 假设某二叉树中随意结点的左右子树的高度相差不超过1,那么它就是一棵平衡二叉树. 分析:所谓平衡二叉树就是要确保每一个结点的左子树与右子树的高度 ...
- 数学之美?编程之美?数学 + 编程= unbelievable 美!
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:Rusu 导语 相信大家跟我一样,偶尔会疑惑:曾经年少的时候学习过的那么多的复杂的数学函数,牛逼的化学方程式,各种物理原理.公式,到底有 ...
- IDEA定位到类的代码区域(查看类的源码)
经常需要查看某一个类中的成员变量和方法,那么怎么进入到这个类的源码区域呢?在IDEA中只需要使用快捷键: ctrl+shift+t 就可以快速定位到这个类的源码.
- nginx配置(windows配置)
以下是我的项目用到的一份配置文件#user nobody;worker_processes 4; #进程数,一般cpu是几核就写多少#error_log logs/error.log;#erro ...
- MyBatis 批量操作、集合遍历-foreach
在使用mybatis操作数据库时,经常会使用到批量插入.IN条件查询的情况,这时就难免要使用到foreach元素.下面一段话摘自mybatis官网: foreach 元素的功能是非常强大的,它允许你指 ...
- JavaScript定时器:setTimeout()和setInterval()
1 超时调用setTimeout() 顾名思义,超时调用的意思就是在一段实际之后调用(在执行代码之前要等待多少毫秒) setTimeout()他可以接收两个参数: 1 要执行的代码或函数 2 毫秒(在 ...
- 统计函数:MAX,MIN,SUM,AVG,COUNT
- 网口划VLAN
do sho run int g0/28 int g0/18 sw mo acc sw acc vlan 220 span portfa exit do wr exit
- Oracle数据库部分迁至闪存存储方案
Oracle数据库部分迁至闪存存储方案 1.实施需求 2.确认迁移表空间信息 3.确认redo信息 4.确认undo信息 5.表空间迁移到闪存 6.redo迁移到闪存 7.undo迁移到闪存 8.备库 ...
- 控制input 输入框的placeholder
/*webkit placeholder居右*/ ::-webkit-input-placeholder { color: #e7e7e7; text-indent: .3rem; font-size ...