Lucene 搜索的初步探究
搜索应用程序和 Lucene 之间的关系
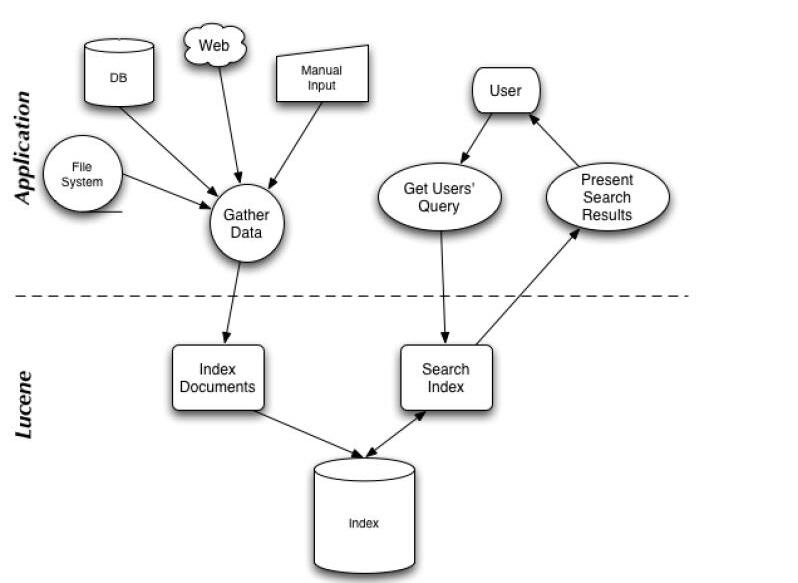
一般的搜索引擎都会采用这样的
Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词 / 短语表,对于这个表中的每个词 / 短语,都有一个链表描述了有哪些文档包含了这个词 / 短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。
反向索引
Lucene 软件包的介绍
org.apache.lucene.document
封装要索引的文档所需要的类,比如 Document, Field。 文档一document对象在程序程序中运行
org.apache.lucene.analysis
对文档进行分词,因为文档在建立索引之前必须要进行分词
org.apache.lucene.index
创建索引以及对创建好的索引进行更新
IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的
org.apache.lucene.search
建立好的索引上进行搜索所需要的类
IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。
Lucene建立索引和搜索的几个流程
建立索引
1 document 指文档可以死HTML,文本等。并且document是由多个Field对象组成的,可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
2 Field Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
3 Analyzer 对文档进行分词
4 IndexWriter IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。
5 Directory 代表了Lucene 的索引的存储的位置 , 有两个实现,第一个是 FSDirectory, 存储在文件系统中的索引 。 RAMDirectory, 存储在内存当中的索引。
搜索文档
之前建立好的索引文档,现在我们可以进行对文档进行搜索
1 Query 是抽象类,有多个继承实现 TermQuery, BooleanQuery, PrefixQuery. 。这些类可以将用户输入的字符串封装成Lucene能够识别的Query
2 Term Term 是搜索的基本单位 基本的语法是
Term term = new Term(“fieldName”,”queryWord”);
fieldName 是指要在文档的那个field上查找,queryWord表示要查询的关键词
3 TermQuery TermQuery是抽象的query的一个之类,
TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个 Term 对象。
4 IndexSearcher 在建立好的索引上进行搜索,
5 Hits Hits 是用来保存搜索的结果的。
建立索引的过程和代码
package LuceneTest.LuceneTest;
import java.io.File;
import java.io.FileReader;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 建立索引的类
* @author Ni Shengwu
*
*/
public class Indexer {
private IndexWriter writer; //写索引实例
//构造方法,实例化IndexWriter
public Indexer(String indexDir) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
IndexWriterConfig config = new IndexWriterConfig(analyzer); //将标准分词器配到写索引的配置中
writer = new IndexWriter(dir, config); //实例化写索引对象
}
//关闭写索引
public void close() throws Exception {
writer.close();
}
//索引指定目录下的所有文件
public int indexAll(String dataDir) throws Exception {
File[] files = new File(dataDir).listFiles(); //获取该路径下的所有文件
for(File file : files) {
indexFile(file); //调用下面的indexFile方法,对每个文件进行索引
}
return writer.numDocs(); //返回索引的文件数
}
//索引指定的文件
private void indexFile(File file) throws Exception {
System.out.println("索引文件的路径:" + file.getCanonicalPath());
Document doc = getDocument(file); //获取该文件的document
writer.addDocument(doc); //调用下面的getDocument方法,将doc添加到索引中
}
//获取文档,文档里再设置每个字段,就类似于数据库中的一行记录
private Document getDocument(File file) throws Exception{
Document doc = new Document();
//添加字段
doc.add(new TextField("contents", new FileReader(file))); //添加内容
doc.add(new TextField("fileName", file.getName(), Store.YES)); //添加文件名,并把这个字段存到索引文件里
doc.add(new TextField("fullPath", file.getCanonicalPath(), Store.YES)); //添加文件路径
return doc;
}
public static void main(String[] args) {
String indexDir = "D:\\lucene\\index"; //将索引保存到的路径
String dataDir = "D:\\lucene\\data"; //需要索引的文件数据存放的目录
Indexer indexer = null;
int indexedNum = 0;
long startTime = System.currentTimeMillis(); //记录索引开始时间
try {
indexer = new Indexer(indexDir);
indexedNum = indexer.indexAll(dataDir);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
indexer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis(); //记录索引结束时间
System.out.println("索引耗时" + (endTime-startTime) + "毫秒");
System.out.println("共索引了" + indexedNum + "个文件");
}
}
建立一个搜索的过程
package LuceneTest.LuceneTest;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir)); //获取要查询的路径,也就是索引所在的位置
IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(); //标准分词器,会自动去掉空格啊,is a the等单词
QueryParser parser = new QueryParser("contents", analyzer); //查询解析器
Query query = parser.parse(q); //通过解析要查询的String,获取查询对象
long startTime = System.currentTimeMillis(); //记录索引开始时间
TopDocs docs = searcher.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中
long endTime = System.currentTimeMillis(); //记录索引结束时间
System.out.println("匹配" + q + "共耗时" + (endTime-startTime) + "毫秒");
System.out.println("查询到" + docs.totalHits + "条记录");
for(ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果
Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档
System.out.println(doc.get("fullPath")); //fullPath是刚刚建立索引的时候我们定义的一个字段
}
reader.close();
}
public static void main(String[] args) {
String indexDir = "D:\\lucene\\index";
String q = "import"; //查询这个字符串
try {
search(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
}Lucene 搜索的初步探究的更多相关文章
- Lucene搜索方式大合集
package junit; import java.io.File; import java.io.IOException; import java.text.ParseException; imp ...
- lucene 搜索demo
package com.ljq.utils; import java.io.File; import java.util.ArrayList; import java.util.List; impor ...
- lucene搜索方式(query类型)
Lucene有多种搜索方式,可以根据需要选择不同的方式. 1.词条搜索(单个关键字查找) 主要对象是TermQuery 调用方式如下: Term term=new Term(字段名,搜索关键字);Qu ...
- Lucene学习笔记: 五,Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结之七:Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene核心--构建Lucene搜索(上篇,理论篇)
2.1构建Lucene搜索 2.1.1 Lucene内容模型 一个文档(document)就是Lucene建立索引和搜索的原子单元,它由一个或者多个字段(field)组成,字段才是Lucene的真实内 ...
- 初步探究java中程序退出、GC垃圾回收时,socket tcp连接的行为
初步探究java中程序退出.GC垃圾回收时,socket tcp连接的行为 今天在项目开发中需要用到socket tcp连接相关(作为tcp客户端),在思考中发觉需要理清socket主动.被动关闭时发 ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- Asp.NetCore初步探究
1, 新建一个空的AspNetCore项目,默认Program下的代码如下: public static void Main(string[] args) { BuildWebHost(args ...
随机推荐
- Struts2学习笔记(十)——自定义拦截器
Struts2拦截器是基于AOP思想实现的,而AOP的实现是基于动态代理.Struts2拦截器会在访问某个Action之前或者之后进行拦截,并且Struts2拦截器是可插拔的:Struts2拦截器栈就 ...
- ArrayList和CopyOnWriteArrayList
这篇文章的目的如下: 了解一下ArrayList的增删改查实现原理 看看为什么说ArrayList查询快而增删慢? CopyOnWriteArrayList为什么并发安全且性能比Vector好 1. ...
- Navicat for MySQL11--使用经验
Navicat for MySQL11--使用经验.. --------- /-------------------导出SQL:右键表--转储SQL文件--结构和数据---(Finished - Su ...
- HTML5无插件多媒体Media——音频audio与视频video
文件日志地址 http://blog.csdn.net/q1056843325/article/details/60336226 音频与视频现在已经变得越来越流行 各个网站为了保证跨浏览器的兼容性 ...
- java web开发时的绝对路径与相对路径
相对路径 不以/开头的路径为相对路径,使用相对路径时的路径为当前访问的文件的父目录,即如果现在访问文件的路径为http://localhost:8080/项目名/目录/文件,那么使用相对路径时路径前缀 ...
- Android笔记: ListView基本用法-ArrayAdapter
ListView实现过程: 新建适配器->添加数据源到适配器->视图加载适配器 数据适配器: 把复杂的数据(数组.链表.数据库.集合等)填充在制定的试图界面上. 两种常用数据适配器 Arr ...
- Servlet知识点
如果请求采用Get方式,则重写doGet()方法,如果请求采用Post方式,则重写doPost()方法. 下面是重写doGet()方法的servlet例子. servlet继承如下类: 整体结构: 在 ...
- js中数组对象根据内容查找符合的第一个对象
今天在写一个混合开发版的app,其中一个功能是扫描快递单号,客户要求不能扫描重复的快递单号!所有就验证查出. 首先实现思路就是: 1.定义一个全局数组变量:var nubList = []; 2.进入 ...
- Hue集成Hadoop和Hive
一.环境准备 1.下载Hue:https://dl.dropboxusercontent.com/u/730827/hue/releases/3.12.0/hue-3.12.0.tgz 2.安装依赖 ...
- caffe cifar10试跑问题总结
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px "Helvetica Neue"; color: #454545 } p. ...