使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机
Lakehouse最早由Databricks公司提出,其可作为低成本、直接访问云存储并提供传统DBMS管系统性能和ACID事务、版本、审计、索引、缓存、查询优化的数据管理系统,Lakehouse结合数据湖和数据仓库的优点:包括数据湖的低成本存储和开放数据格式访问,数据仓库强大的管理和优化能力。Delta Lake,Apache Hudi和Apache Iceberg是三种构建Lakehouse的技术。
与此同时,Pulsar提供了一系列特性:包括分层存储、流式卸载、列式卸载等,让其成为一个可以统一批和事件流的存储层。特别是分层存储的特性,然Pulsar成为一个轻量级数据湖,但是Pulsar还是缺乏一些性能优化,比如索引,数据版本(在传统DBMS管理系统中非常常见),引入列式卸载程序的目的是为了缩小性能差距,但是还不够。
本提议尝试将Apache Pulsar作为Lakehouse,该提案仅提供顶层设计,详细设计和实现在后面的子提议中解决;
2. 分析
本部分将分析构建Lakehouse需要的关键特性,然后分析Pulsar是否满足要求以及识别还有哪些差距。
Lakehouse有如下关键特性:
- 事务支持:企业级Lakehouse中很多数据pipeliine会并发读写数据,支持ACID事务可以保证并发读写的一致性,特别是使用SQL;Delta Lake,Iceberg,Hudi三个数据湖框架都基于低成本的对象存储实现了事务层,都支持事务。Pulsar在2.7.0版本后引入了事务支持,并且支持跨topic的事务;
- Schema约束和治理:Lakehouse需要支持Schema的约束和演进,支持数仓型Schema范式,如星型/雪花型Schema,另外系统应该能够推理数据完整性,并且应该具有健壮的治理和审核机制,上述三个系统都有该能力。Pulsar有内置的Schema注册服务,它满足Schema约束和治理的基本要求,但是可能仍有一些地方需要改进。
- BI支持:Lakehouses可以直接在源数据上使用BI工具,这样可以减少陈旧性,提高新鲜度,减少等待时间,并降低必须同时在数据湖和仓库中操作两个数据副本的成本。三个数据湖框架与Apache Spark的集成非常好,同时可以允许Redshift,Presto/Athena查询源数据,Hudi社区也已经完成了对多引擎如Flink的支持。Pulsar暴露了分层存储中的段以供直接访问,这样可以与流行的数据处理引擎紧密集成。 但是Pulsar中的分层存储本身在服务BI工作负载方面仍然存在性能差距,我们将在该提案中解决这些差距。
- 存储与计算分离:这意味着存储和计算使用单独的集群,因此这些系统可以单独水平无限扩容。三个框均支持存储与计算分离。Pulsar使用了存储与计算分离的多层体系结构部署。
- 开放性:使用开放和标准化的数据格式,如Parquet,并且它们提供了API,因此各种工具和引擎(包括机器学习和Python / R库)可以"直接"有效地访问数据,三个框架支持Parquet格式,Iceberg还支持ORC格式,对于ORC格式Hudi社区正在支持中。Pulsar还不支持任何开放格式,列存卸载支持Parquet格式。
- 支持从非结构化数据到结构化数据的多种数据类型:Lakehouse可用于存储,优化,分析和访问许多新数据应用程序所需的数据类型,包括图像,视频,音频,半结构化数据和文本。尚不清楚Delta,Iceberg,Hudi如何支持这一点。Pulsar支持各种类型数据。
- 支持各种工作负载:包括数据科学,机器学习以及SQL和分析。 可能需要多种工具来支持所有这些工作负载,但它们都依赖于同一数据存储库。三个框架与Spark紧密结合,Spark提供了广泛的工具选择。Pulsar也与Spark有着紧密结合。
- 端到端流:实时报告是许多企业的常态,对流的支持消除了对专门用于服务实时数据应用程序的单独系统的需求,Delta Lake和Hudi通过变更日志提供了流功能。 但这不是真正的“流”。Pulsar是一个真正的流系统。
可以看到Pulsar满足构建Lakehouse的所有条件。然而现在的分层存储有很大的性能差距,例如:
- Pulsar并不以开放和标准的格式存储数据,如Parquet;
- Pulsar不会为卸载的数据部署任何索引机制;
- Plusar不支持高效的Upserts;
这里旨在解决Pulsar存储层的性能问题,使Pulsar能作为Lakehouse。
3. 当前方案
图1展示了当前Pulsar流的存储布局。
- Pulsar在ZooKeeper中存储了段(segment)元数据;
- 最新的段存储在Apache BookKeeper中(更快地存储层)
- 旧的段从Apache BookKeeper卸载到分层存储(便宜的存储层)。 卸载的段的元数据仍保留在Zookeeper中,引用的是分层存储中卸载的对象。
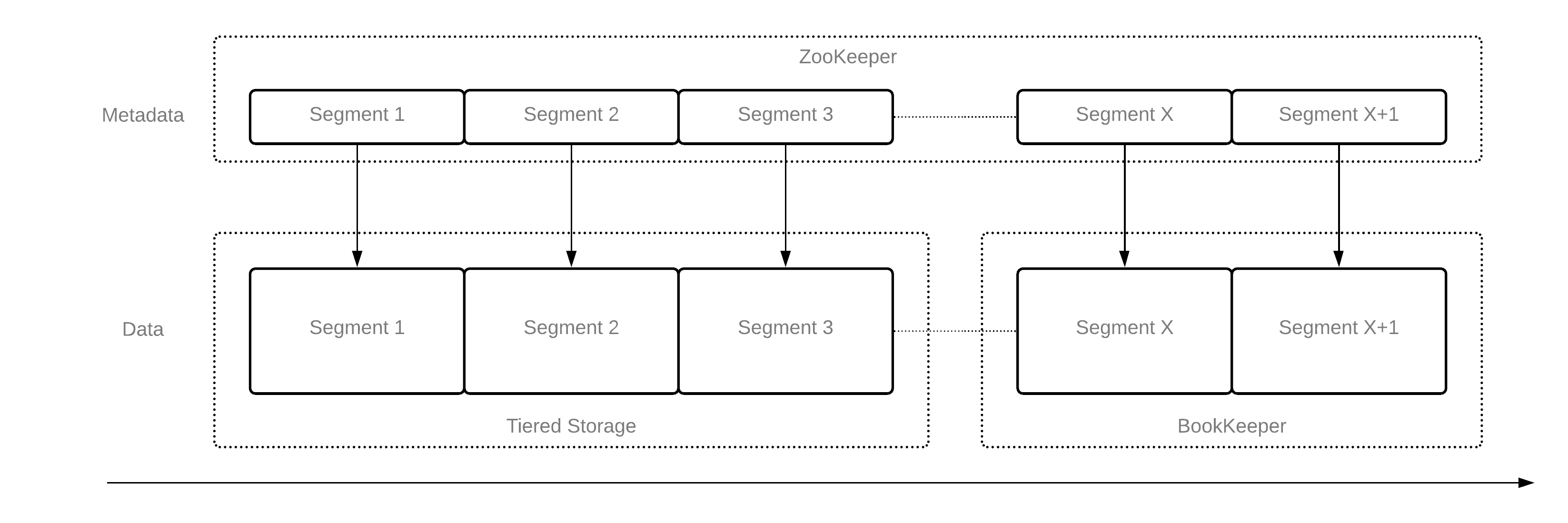
当前的方案有一些缺点:
- 它不使用任何开放式存储格式来存储卸载的数据。 这意味着很难与更广泛的生态系统整合。
- 它将所有元数据信息保留在ZooKeeper中,这可能会限制可伸缩性。
4. 新的Lakehouse存储方案
新方案建议在分层存储中使用Lakehouse存储卸载的数据。该提案建议使用Apache Hudi作为Lakehouse存储,原因如下:
- 云提供商在Apache Hudi上提供了很好的支持。
- Apache Hudi已经作为顶级项目毕业。
- Apache Hudi同时支持Spark和Flink多引擎。同时在中国有一个相当活跃的社区。
4.1 新的存储布局
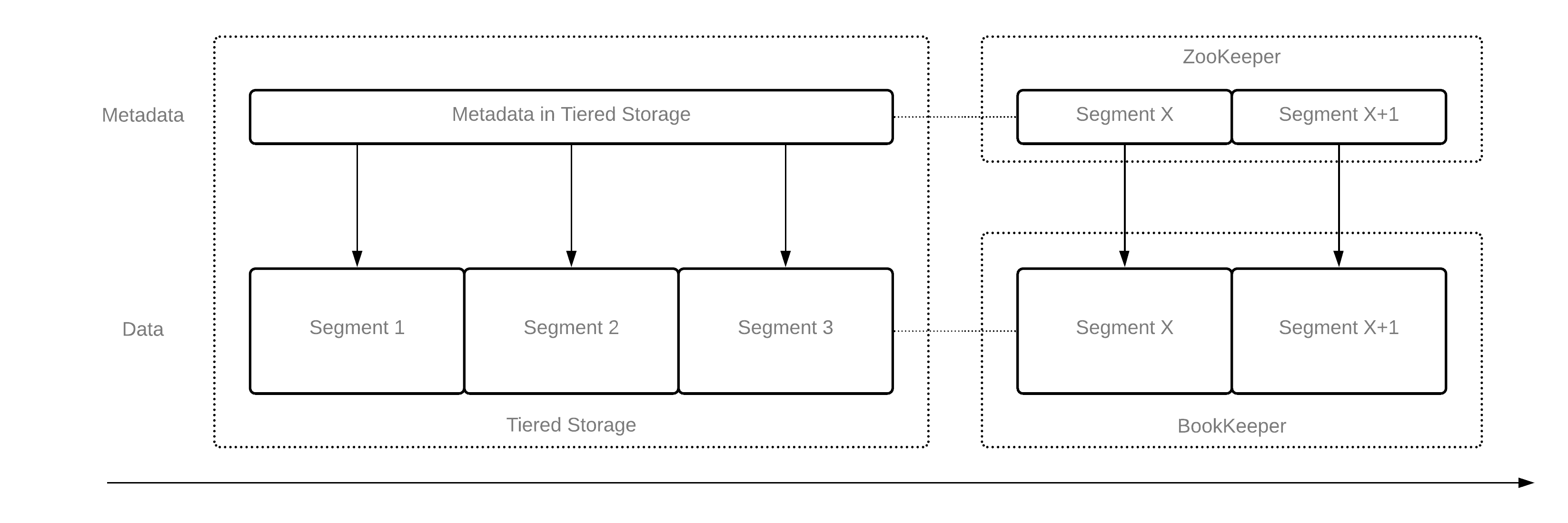
图2展示了Pulsar topic新的布局。
- 最新片段(未卸载片段)的元数据存储在ZooKeeper中。
- 最新片段(未卸载片段)的数据存储在BookKeeper中。
- 卸载段的元数据和数据直接存储在分层存储中。 因为它是仅追加流。 我们不必使用像Apache Hudi这样的Lakehouse存储库。 但是如果我们也将元数据存储在分层存储中,则使用Lakehouse存储库来确保ACID更有意义。
4.2 支持高效Upserts
Pulsar不直接支持upsert。它通过主题(topic)压缩支持upsert。 但是当前的主题压缩方法既不可扩展,也不高效。
- 主题压缩在代理内(broker)完成。 它无法支持大量数据的插入,特别是在数据集很大的情况下。
- 主题压缩不支持将数据存储在分层存储中。
为了支持高效且可扩展的Upsert,该提案建议使用Apache Hudi将压缩后的数据存储在分层存储中。 图3展示了使用Apache Hudi支持主题压缩中的有效upserts的方法。
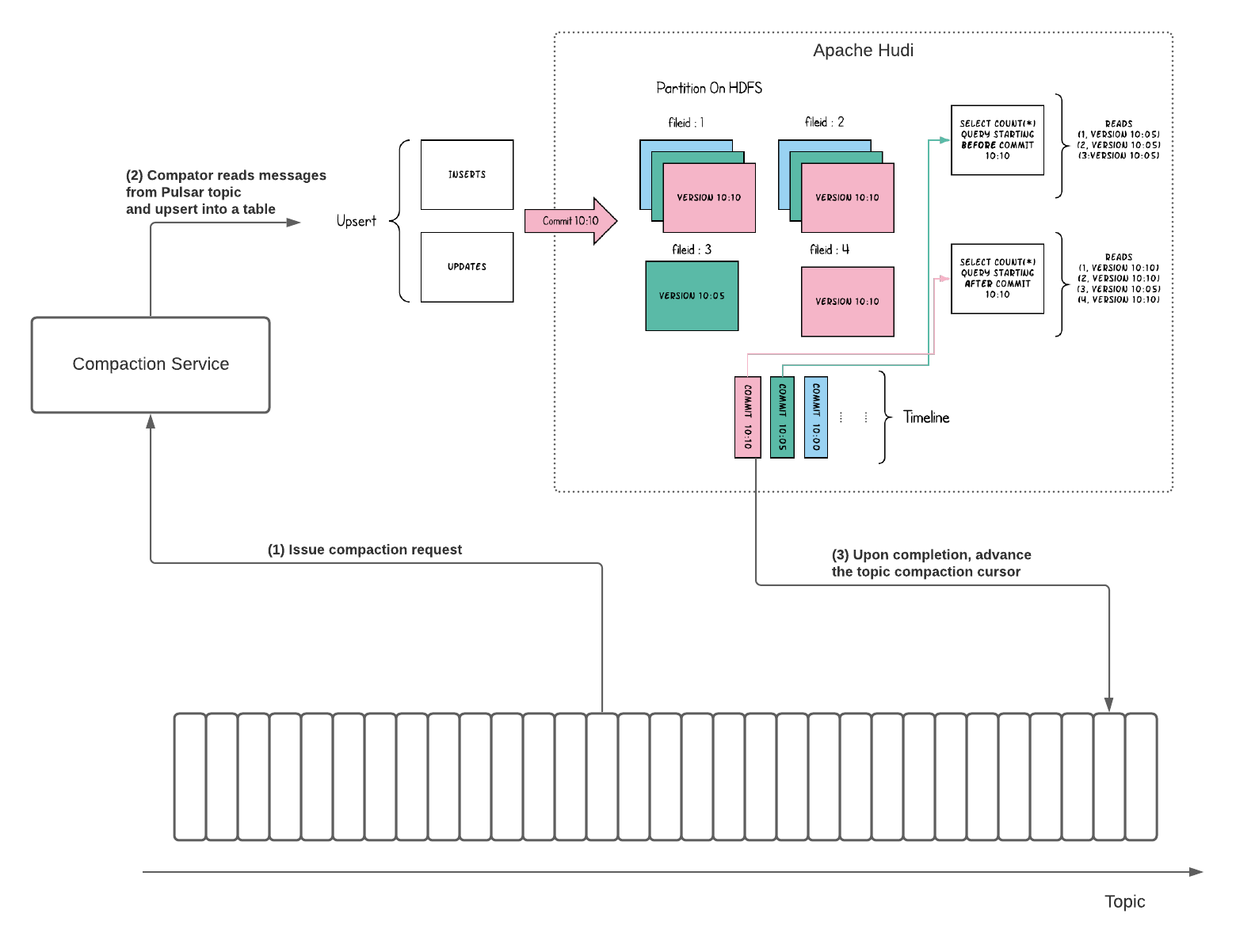
该想法是实现主题压缩服务。主题压缩服务可以作为单独的服务(即Pulsar函数)运行以压缩主题。
- 代理向压缩服务发出主题压缩请求。
- 压缩服务接收压缩请求,并读取消息并将其向上插入到Hudi表中。
- 完成upsert之后,将主题压缩游标前进到它压缩的最后一条消息。
主题压缩游标将引用位置的元数据存储在存储Hudi表的分层存储中。
4.3 将Hudi表当做Pulsar Topic
Hudi会在不同的即时时间维护对表执行的所有操作的时间轴,这有助于提供表的即时视图,同时还有效地支持按_arrival_顺序进行数据检索。Hudi支持从表中增量拉取变更。我们可以支持通过Hudi表备份的_ReadOnly_主题。这允许应用程序从Pulsar代理流式传输Hudi表的变更。图4展示了这个想法。
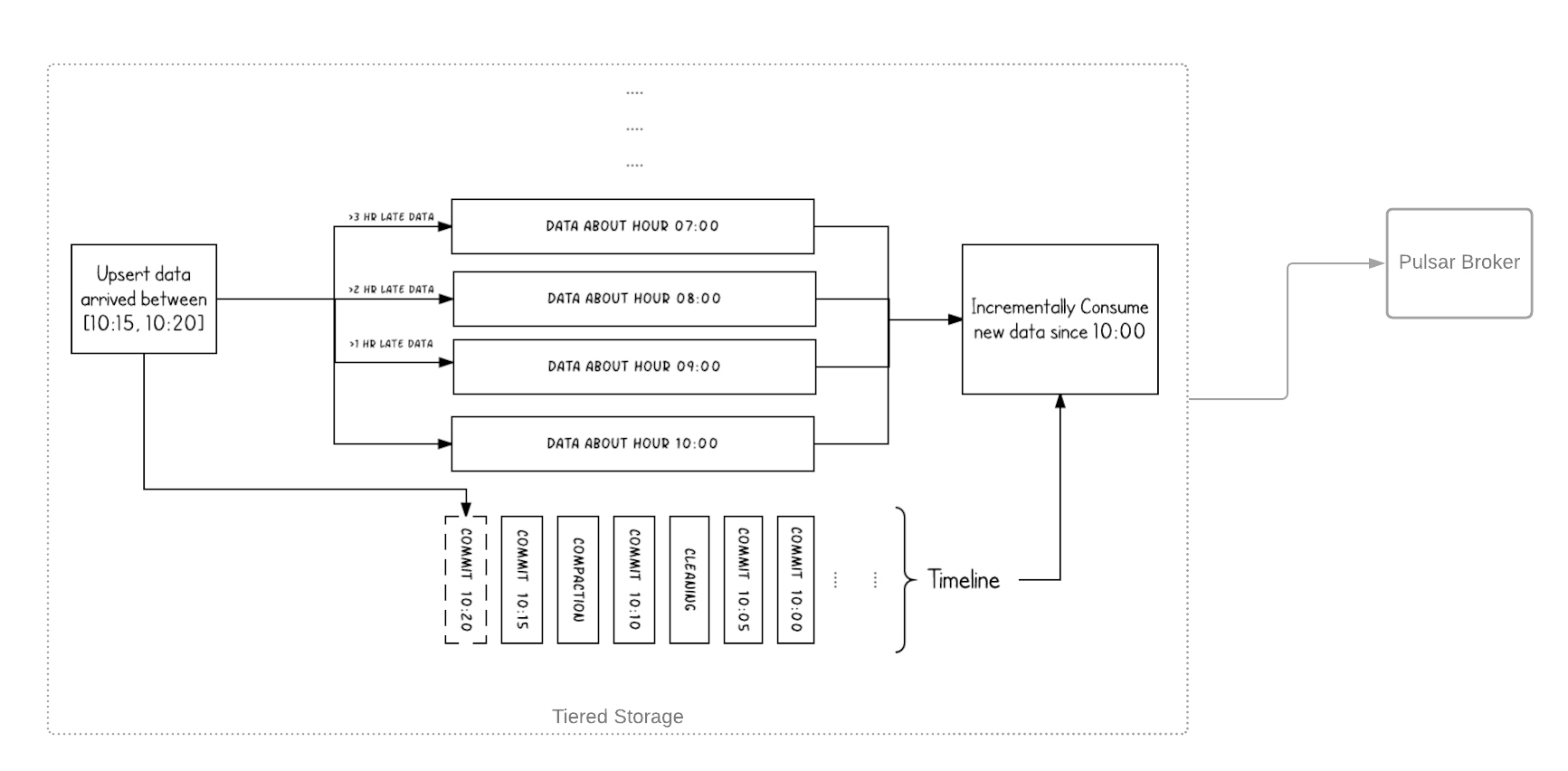
4.4 可扩展的元数据管理
当我们开始将所有数据存储在分层存储中时,该提案建议不存储卸载或压缩数据的元数据,而只依赖分层存储来存储卸载或压缩数据的元数据。
该提案提议在以下目录布局中组织卸载和压缩的数据。
- <tenant>/
- <namespace>/
- <topics>/
- segments/ <= Use Hudi to store the list of segments to guarantee ACID
- segment_<segment-id>
- ...
- cursors/
- <cursor A>/ <= Use Hudi to store the compacted table for cursor A.
- <cursor B>/ <= ...
5. 引用
[1] Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
[2] What is a Lakehouse? https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
[3] Diving Deep into the inner workings of the Lakehouse and Delta Lake. https://databricks.com/blog/2020/09/10/diving-deep-into-the-inner-workings-of-the-lakehouse-and-delta-lake.html
使用Apache Pulsar + Hudi构建Lakehouse方案了解下?的更多相关文章
- Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造.在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehou ...
- 个推基于 Apache Pulsar 的优先级队列方案
作者:个推平台研发工程师 祥子 一.业务背景在个推的推送场景中,消息队列在整个系统中占有非常重要的位置.当 APP 有推送需求的时候, 会向个推发送一条推送命令,接到推送需求后,我们会把APP要求推送 ...
- Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践
腾讯 Angel PowerFL 联邦学习平台 联邦学习作为新一代人工智能基础技术,通过解决数据隐私与数据孤岛问题,重塑金融.医疗.城市安防等领域. 腾讯 Angel PowerFL 联邦学习平台构建 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- Apache Pulsar Summit Asia 2020 正式启动,演讲议题征集中!
Apache Pulsar Summit 是 Apache Pulsar 社区年度盛会,它将分布在世界各地的 Apache Pulsar 项目 Contributor.Commiter 和各企业 CT ...
- [Apache Pulsar] 企业级分布式消息系统-Pulsar快速上手
Pulsar快速上手 前言 如果你还不了解Pulsar消息系统,可以先看上一篇文章 企业级分布式消息系统-Pulsar入门基础 Pulsar客户端支持多个语言,包括Java,Go,Pytho和C++, ...
- 分布式消息队列Apache Pulsar
Pulsar简介 Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化.Plusar已经在Yahoo的生产环境使用了三年多, ...
- Apache 顶级项目 Apache Pulsar 成长回顾
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
随机推荐
- SpringBoot - yml写法
1 #区分大小写 2 server: 3 port: 8081 4 path: hello 5 6 #字面量:普通的值(数字,字符串,布尔): 7 #字符串:双引号 - 不转义 单引号 - 转义 8 ...
- 多线程之Lock接口
之前写了一下synchronized关键字的一点东西,那么除了synchronized可以加锁外,JUC(java.util.concurrent)提供的Lock接口也可以实现加锁解锁的功能. 看完本 ...
- https如何使用python+flask来实现
摘要:一般http中存在请求信息明文传输,容易被窃听截取:数据的完整性未校验,容易被篡改:没有验证对方身份,存在冒充危险.面对这些问题,怎么破? 一.为什么要用https 一般http中存在如下问题: ...
- 829. Consecutive Numbers Sum
Given a positive integer N, how many ways can we write it as a sum of consecutive positive integers? ...
- 12- winmerge讲解
WinMerge是一款运行于Windows系统下的免费开源的文件比较/合并的工具,使用它可以非常方便的比较多个文档内容设置是文件夹与文件夹之间的差异.适合程序员或者经常撰写文稿的朋友使用.
- 【手打】coredns单台使用
目录: coredns介绍 coredns安装 corendns配置 coredns介绍 CoreDNS 其实就是一个 DNS 服务,而 DNS 作为一种常见的服务发现手段,所以很多开源项目以及工程师 ...
- POJ 2762 单连通图
题意: 给你一个有向图,问你这个图是不是单连通图,单连通就是任意两点之间至少存在一条可达路径. 思路: 先强连通所点,重新建图,此时的图不存在环,然后我们在看看是否存在一条路径可以 ...
- POJ3160强连通+spfa最长路(不错)
题意: 给你一个有向图,每个点上有一个权值,可正可负,然后给你一些链接关系,让你找到一个起点,从起点开始走,走过的边可以在走,但是拿过权值的点就不能再拿了,问最多能拿到多少权值? 思路: ...
- Wordpress主题编辑器漏洞复现
Wordpress是全球流行的博客网站,全球有上百万人使用它来搭建博客.他使用PHP脚本和Mysql数据库来搭建网站. 那么,如果当我们在渗透测试过程中获得到了别人Wordpress的账号和密码之后, ...
- pandas(10):数据增删改
目录 一.对索引进行操作 1 操作索引值df.rename() 二.指定数据替换.修改df.replace() 三.特殊值--缺失值处理 四.新增行列 1 直接赋值添加新列 2 df.assign() ...