FSAF:嵌入anchor-free分支来指导acnhor-based算法训练 | CVPR2019
FSAF深入地分析FPN层在训练时的选择问题,以超简单的anchor-free分支形式嵌入原网络,几乎对速度没有影响,可更准确的选择最优的FPN层,带来不错的精度提升
来源:晓飞的算法工程笔记 公众号
论文: Feature Selective Anchor-Free Module for Single-Shot Object Detection

Introduction
目标检测的首要问题就是尺寸变化,许多算法使用FPN以及anchor box来解决此问题。在正样本判断上面,一般先根据目标的尺寸决定预测用的FPN层,越大的目标则使用更高的FPN层,然后根据目标与anchor box的IoU进一步判断,但这样的设计会带来两个限制:拍脑袋式的特征选择以及基于IoU的anchor采样。
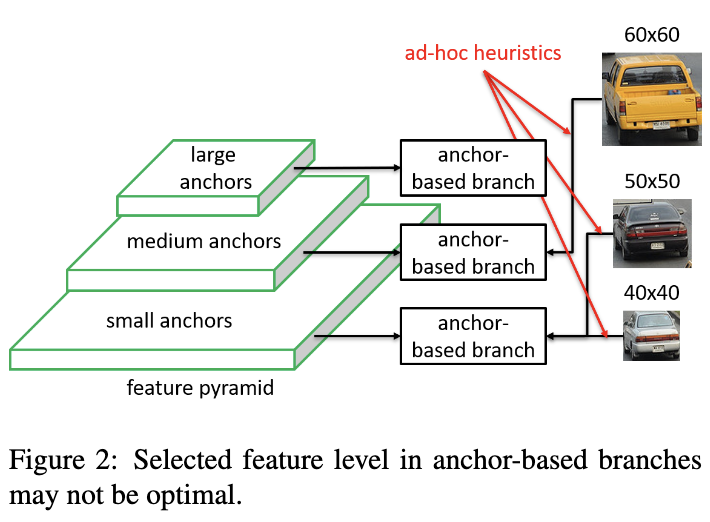
如图2所示,60x60选择中间的anchor,而50x50以及40x40的则选择最小的anchor,anchor的选择都是人们根据经验制定的规则,这在某些场景下可能不是最优的选择。
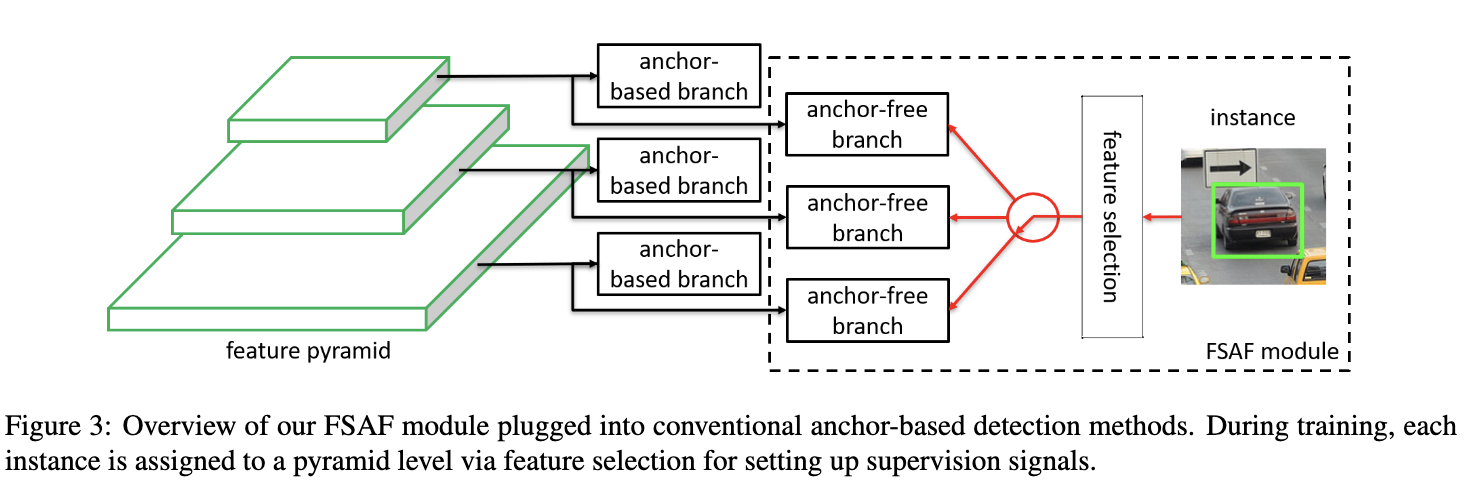
为了解决上述的问题,论文提出了简单且高效的特征选择方法FSAF(feature selective anchor-free),能够在每轮训练中选择最优的层进行优化。如图3所示,FSAF为FPN每层添加anchor-free分支,包含分类与回归,在训练时,根据anchor-free分支的预测结果选择最合适的FPN层用于训练,最终的网络输出可同时综合FSAF的anchor-free分支结果以及原网络的预测结果。
Network Architecture
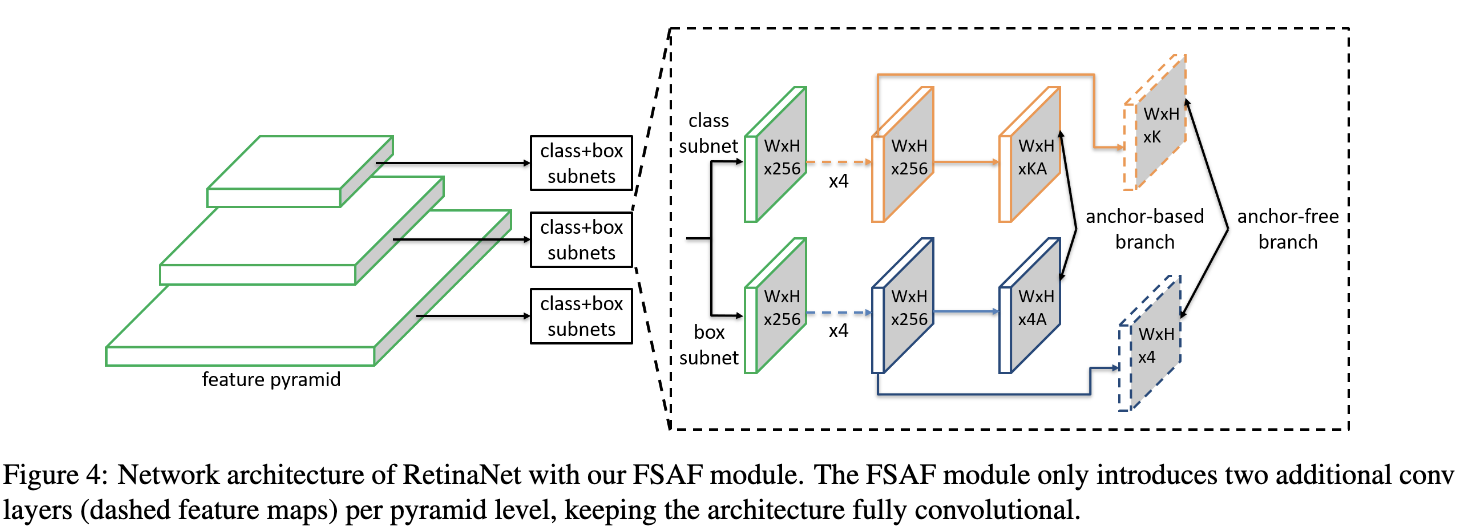
FSAF的网络结果非常简单,如图4所示。在原有的网络结构上,FSAF为FPN每层引入两个额外的卷积层,分别用于预测anchor-free的分类以及回归结果。这样,在共用特征的情况下,anchor-free和anchor-based的方法可进行联合预测。
Ground-truth and Loss
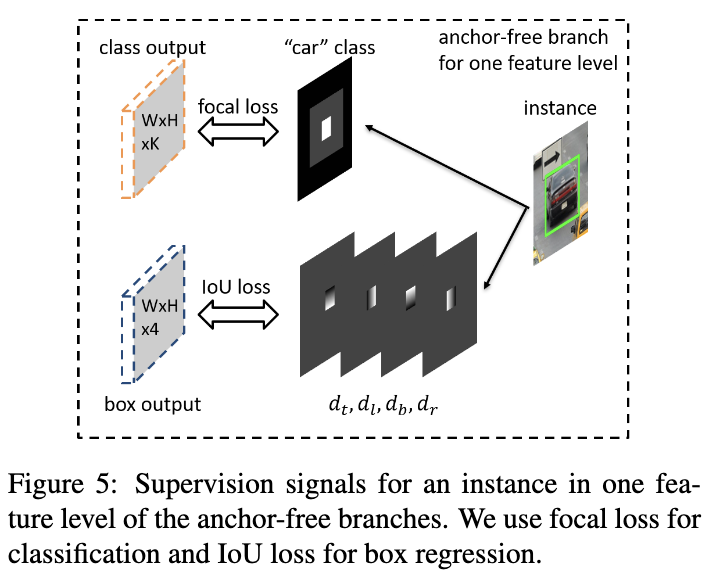
对于目标$b=[x,y,w,h]$,在训练时可映射到任意的FPN层$P_l$,映射区域为$bl_p=[xl_p, y^l_p, w^l_p, hl_p]$。一般而言,$bl_p=b/2l$。定义有效边界$bl_e=[x^l_e, y^l_e, w^l_e, hl_e]$和忽略边界$bl_i=[x^l_i, y^l_i, w^l_i, h^l_i]$,可用于定义特征图中的正样本区域、忽略区域以及负样本区域。有效边界和忽略边界均与映射结果成等比关系,比例分别为$\epsilon_e=0.2$和$\epsilon_i=0.5$,最终的分类损失为所有正负样本的损失值之和除以正样本点数。
Classification Output
分类结果包含$K$维,目标主要设定对应维度,样本定义分以下3种情况:
- 有效边界内的区域为正样本点。
- 忽略边界到有效边界的区域不参与训练。
- 忽略边界映射到相邻的特征金字塔层中,映射的边界内的区域不参与训练
- 其余区域为负样本点。
分类的训练采用focal loss,$\alpha=0.25$,$\gamma=2.0$,完整的分类损失取所有正负区域的损失值之和除以有效区域点数。
Box Regression Output
回归结果输出为分类无关的4个偏移值维度,仅回归有效区域内的点。对于有效区域位置$(i,j)$,将映射目标表示为$dl_{i,j}=[dl_{t_{i,j}}, d^l_{l_{i,j}}, d^l_{b_{i,j}}, dl_{r_{i,j}}]$,分别为当前位置到$bl_p$的边界的距离,对应的该位置上的4维向量为$d^l_{i,j}/S$,$S=4.0$为归一化常量。回归的训练采用IoU损失,完整的anchor-free分支的损失取所有有效区域的损失值的均值。
Online Feature Selection
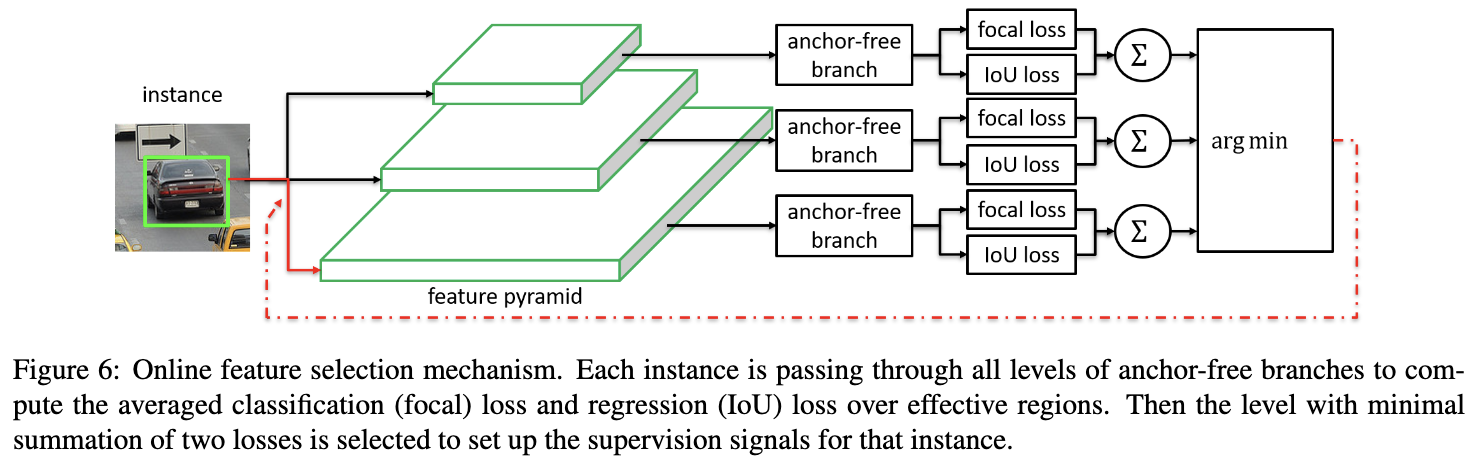
anchor-free的设计允许我们使用任意的FPN层$P_l$进行训练,为了找到最优的FPN层,FSAF模块需要计算FPN每层对目标的预测效果。对于分类与回归,分别计算各层有效区域的focal loss损失以及IoU loss损失:
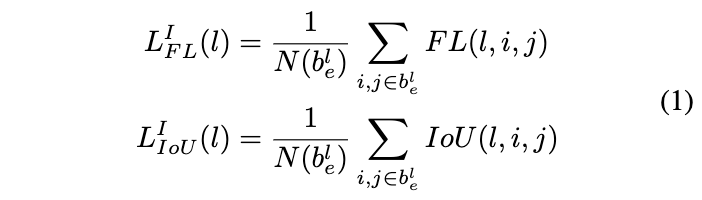
在得到各层的结果后,取损失值最小的层作为当轮训练的FPN层:
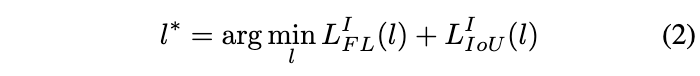
Joint Inference and Training
Inference
由于FSAF对原网络的改动很少,在推理时,稍微过滤下anchor-free和anchor-based分支的结果,然后合并进行NMS。
Optimization
完整的损失函数综合anchor-based分支以及anchor-free分支,$L=L{ab}+\lambda(L{af_{cls}}+L^{af_{reg}})$
Experiments

各种结构以及FPN层选择方法的对比实验。

精度与推理速度对比。
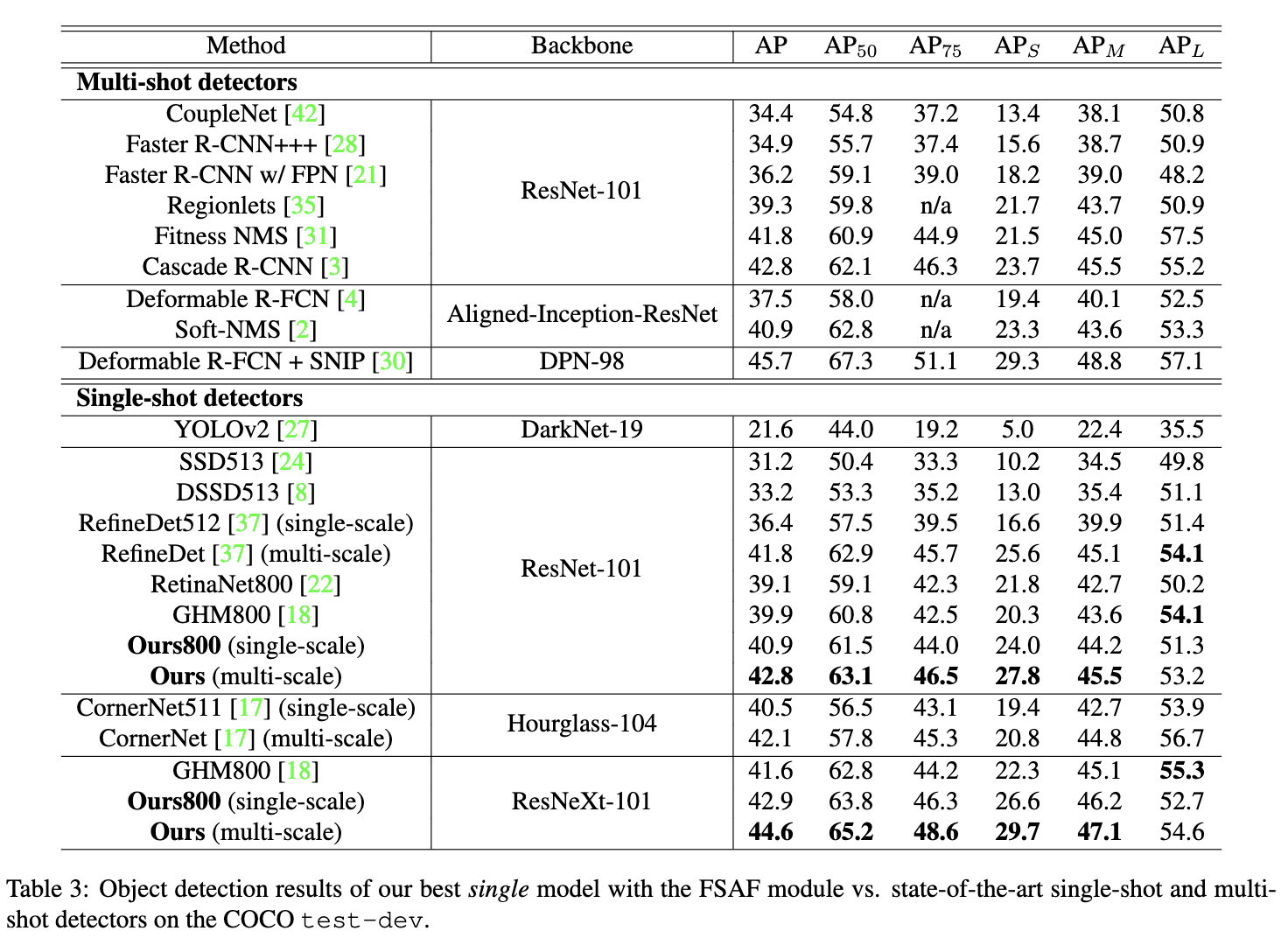
与SOTA方法对比。
Conclusion
FSAF深入地分析FPN层在训练时的选择问题,以超简单的anchor-free分支形式嵌入原网络,几乎对速度没有影响,可更准确的选择最优的FPN层,带来不错的精度提升。需要注意的是,虽然抛弃以往硬性的选择方法,但实际上依然存在一些人为的设定,比如有效区域的定义,所以该方法还不是最完美的。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

FSAF:嵌入anchor-free分支来指导acnhor-based算法训练 | CVPR2019的更多相关文章
- 版本分支管理标准 - Trunk Based Development 主干开发模型
之前分享过<版本分支管理标准 - Git Flow>,不过在实际使用过程中, 因为其有一定的复杂度,使用起来较为繁琐,所以一些人员较少的团队并不会使用这个方案. 在这基础上,一些新的分支管 ...
- 目标检测中的anchor-based 和anchor free
目标检测中的anchor-based 和anchor free 1. anchor-free 和 anchor-based 区别 深度学习目标检测通常都被建模成对一些候选区域进行分类和回归的问题.在 ...
- TensorFlow NMT的词嵌入(Word Embeddings)
本文转载自:http://blog.stupidme.me/2018/08/05/tensorflow-nmt-word-embeddings/,本站转载出于传递更多信息之目的,版权归原作者或者来源机 ...
- 【57】目标检测之Anchor Boxes
Anchor Boxes 到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念. 我们还是先吃一颗栗子 ...
- 知识图谱顶会论文(SIGIR-2022) MorsE:归纳知识图嵌入的元知识迁移
MorsE:归纳知识图嵌入的元知识迁移 论文题目: Meta-Knowledge Transfer for Inductive Knowledge Graph Embedding 论文地址: http ...
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- FAQ: Machine Learning: What and How
What: 就是将统计学算法作为理论,计算机作为工具,解决问题.statistic Algorithm. How: 如何成为菜鸟一枚? http://www.quora.com/How-can-a-b ...
- 论文阅读笔记四十:Deformable ConvNets v2: More Deformable, Better Results(CVPR2018)
论文源址:https://arxiv.org/abs/1811.11168 摘要 可变形卷积的一个亮点是对于不同几何变化的物体具有适应性.但也存在一些问题,虽然相比传统的卷积网络,其神经网络的空间形状 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
随机推荐
- VUE3 之 全局组件与局部组件
1. 概述 老话说的好:忍耐是一种策略,同时也是一种性格磨炼. 言归正传,今天我们来聊聊 VUE 的全局组件与局部组件. 2. 全局组件 2.1 不使用组件的写法 <body> < ...
- Git使用:版本回退
在Git中,我们可以用 git log命令查看我们修改的历史记录 C:\Users\Administrator\Documents\GitHub\learngit [master]> git l ...
- [源码分析] Facebook如何训练超大模型---(1)
[源码分析] Facebook如何训练超大模型---(1) 目录 [源码分析] Facebook如何训练超大模型---(1) 0x00 摘要 0x01 简介 1.1 FAIR & FSDP 1 ...
- Java高效开发-远程debug
1.前言 "这怎么回事?在本地还好好,放到服务器就不行了.这该怎么排查,日志也看不出来啥呀",日常开发中经常会出现这种问题,这时候就可以尝试idea远程debug的模式试试 2.使 ...
- Solon Web 开发,十四、与Spring、Jsr330的常用注解对比
Solon Web 开发 一.开始 二.开发知识准备 三.打包与运行 四.请求上下文 五.数据访问.事务与缓存应用 六.过滤器.处理.拦截器 七.视图模板与Mvc注解 八.校验.及定制与扩展 九.跨域 ...
- java基础编程练习题
1.題目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一 对兔子,假如兔子都不死,问每个月的兔子总数为多少? 1 2 3 4 5 6 7 1 1 2 3 ...
- 3D建模服务提供更高效、专业的能力,“筑”力开发者
3D建模服务(3D Modeling Kit)是HMS Core在图形图像领域又一技术开放.3D建模产品的定位就是要做快速.简洁.低成本的3D制作能力,并陆续开放给有3D模型.动画游戏制作等能力诉求的 ...
- 不难懂-----redux
一.flux的缺陷 因为dispatcher和Store可以有多个互相管理起来特别麻烦 二.什么是redux 其实redux就是Flux的一种进阶实现.它是一个应用数据流框架,主要作用应用状态的管理 ...
- json模块 os模块 文件加密
目录 一:random随机模块 二:os模块 三:文件处理选择任意视频 四:sys模块 五:实现文件执行加密操作 六:json 序列化模块 七:json序列化 反序列化 八:json 文件写读方式 九 ...
- Linux inode节点使用率过大处理办法
当发现某个分区下的inode使用率过大时,需要找到该分区下的某些目录里有哪些文件可以清理. 查找某个目录下一个月或两个月之前的文件,然后删除# find . -type f -mtime +30 |w ...