unittest+ddt_实现数据驱动测试(7)
我们设计测试用例时,会出现测试步骤一样,只是其中的测试数据有变化的情况,比如测试登录时的账号密码。这个时候,如果我们依然使用一条case一个方法的话,会出现大量的代码冗余,而且效率也会大大降低。此时,ddt模块就能帮助我们解决这个问题。
ddt(data-driven test),顾名思义,数据驱动测试。这个模块是第三方库,需要我们自己下载。或者直接在命令行输入pip install ddt。
ddt用法
先看一个简单的演示:
import unittest
import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值
def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致
print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表
@ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数
def test_case_2(self, v1, v2):
print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2}, {"v3": 3, "v4": 4}) # 迭代的参数值类型可以为字典,字典的key值需要与形参的名称一致
@ddt.unpack
def test_case_3(self, v3, v4):
print(f"v3:{v3} v4:{v4}") if __name__ == '__main__':
unittest.main()
演示结果:
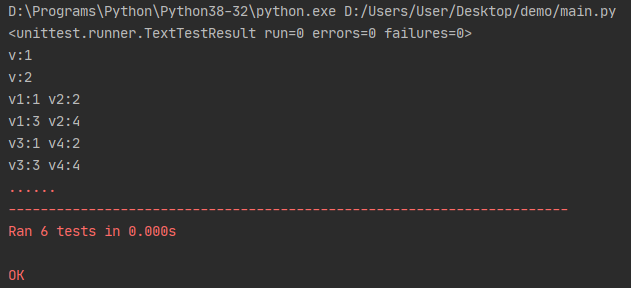
ddt缺陷
按照上面的方法将ddt运用到实际项目中,就能实现数据驱动的功能了。但是,用dir(Demo)查看类的属性时,发现找不到 test_case_1,*2,*3的方法名称,而是出现下图类似的名称。

这是因为ddt为了防止方法名冲突,自动修改了方法名称。名称改变后,表面看起来也没影响用例的执行,这是因为我们使用的是自动搜索用例的方法执行的用例,如果使用addTest这种指定用例的方法就会报错:ValueError: no such test method in <class '__main__.Demo'>: test_case_1
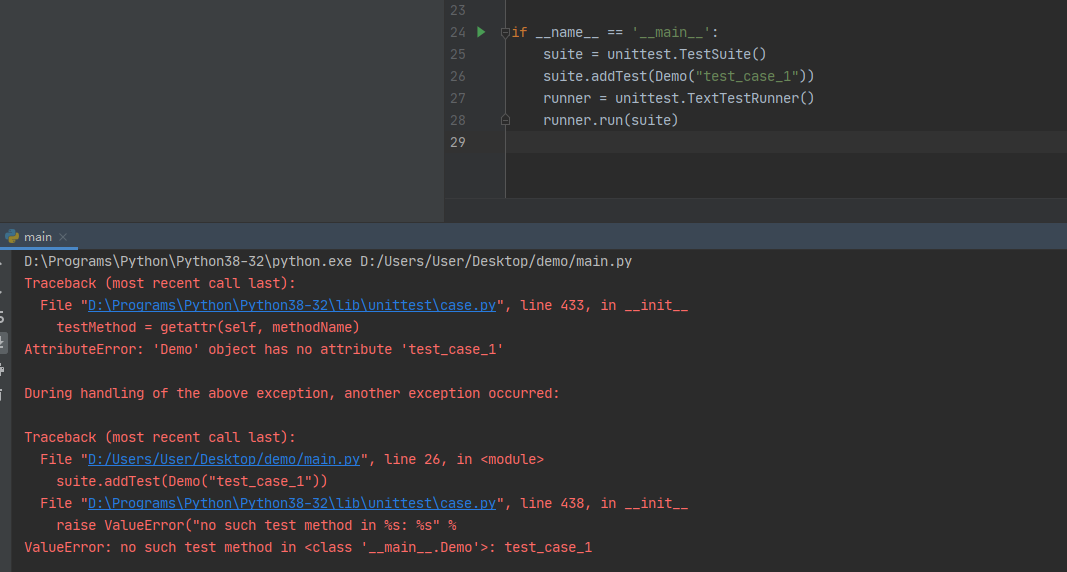
如果我们不实用指定用例的方法那是不是就没有问题了呢?执行上确实没问题,但如果我们使用了自动生成报告的模块(比如:BeautifulReport),生成的报告中,用例名称显示的是修改后的名称。

修复ddt缺陷
添加指定用例的方法看起来是无解的,因为使用数据驱动迭代的过程中,ddt必然会修改被装饰方法的方法名称,那怎么办呢?既然是ddt在解析用例过程中修改的方法名称,那么我们在解析过程中自定义用例名。
综合考虑各数据类型的特性后,决定不修改ddt对元组和列表类型数据的处理方式,只在字典类型的数据中添加指定用例名称的方法。
通读ddt源码,发现ddt是在 mk_test_name() 函数中定义的用例名称,具体代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
# Add zeros before index to keep order
index = "{0:0{1}}".format(index + 1, index_len) if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
我们只要在这部分代码中增加对字典类型的数据处理即可,增加蓝色区域代码如下:
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
# Add zeros before index to keep order
index = "{0:0{1}}".format(index + 1, index_len)
if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
if isinstance(value, dict):
test_name = value.get("case_name")
if test_name is not None:
return test_name
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
修改代码后,自定义用例名称的用法是在数据中定义case_name的key,值就为用例名称。
代码演示如下:
import unittest
import ddt @ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data(1, 2) # 迭代的参数值
def test_case_1(self, v): # 迭代的参数个数需要与方法中的形参个数一致
print(f"v:{v}") @ddt.data((1, 2), [3, 4]) # 迭代的参数值类型可以为元组或列表
@ddt.unpack # 当迭代的参数为多维数组时,需要使用该装饰器来解析参数
def test_case_2(self, v1, v2):
print(f"v1:{v1} v2:{v2}") @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称
@ddt.unpack
def test_case_3(self, v3, v4, case_name):
print(f"v3:{v3} v4:{v4}")
执行结果如下
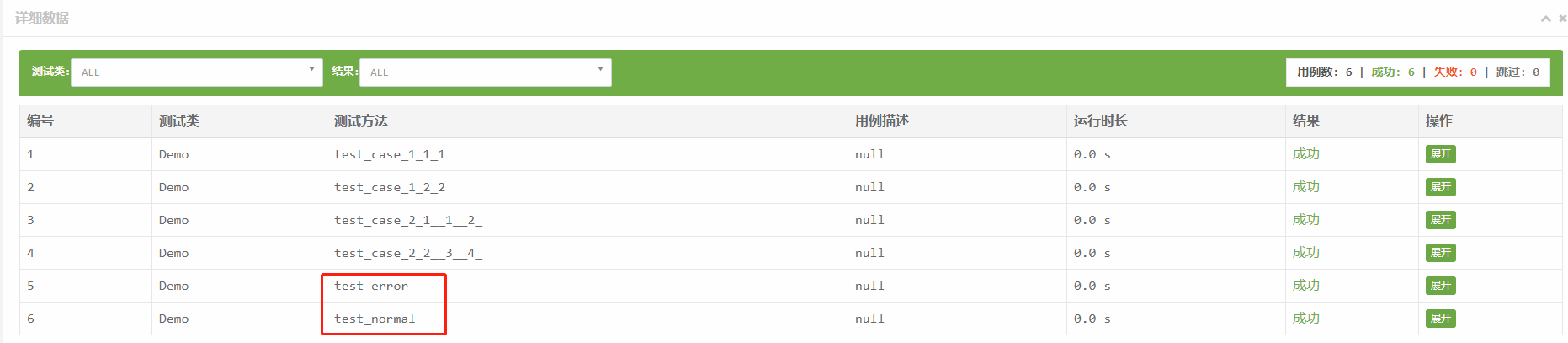
需要注意两点:
- 自定义的用例名称不能相同,虽然不会报错,但是只会执行一个用例。
- 自定义的用例名称也必须是test开头。
使用这种方法,也能解决addTest添加不了用例的问题,有兴趣自己可以试试,就不在演示了。
ddt的数据可在用例描述中参数化显示
ddt对用例描述使用format方法进行了初始化
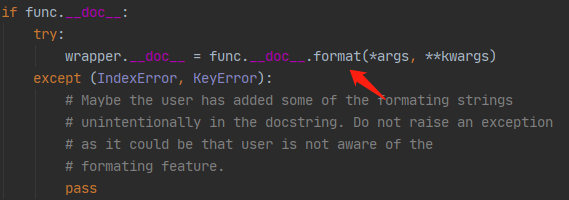
因此在用例描述中,增加参数值的显示
@ddt.ddt # 解析Demo中使用了ddt装饰器的方法
class Demo(unittest.TestCase): @ddt.data({"v3": 1, "v4": 2, "case_name": "test_normal"}, {"v3": 3, "v4": 4, "case_name": "test_error"}) # 在数据中定义case_name的key,值就为用例名称
@ddt.unpack
def test_case(self, v3, v4, case_name):
"""参数值为v3:{v3},v4:{v4}"""
print(f"v3:{v3} v4:{v4}")
执行结果

unittest+ddt_实现数据驱动测试(7)的更多相关文章
- Python3|ddt|unittest|浅议数据驱动测试
目录 1.DDT简介 2.data装饰器 3.unpack装饰器 4.file_data装饰器 5.总结 1.DDT简介 Data-Driven Tests(DDT)即数据驱动测试.它允许您通过不同的 ...
- python Unittest+excel+ddt数据驱动测试
#!user/bin/env python # coding=utf- # @Author : Dang # @Time : // : # @Email : @qq.com # @File : # @ ...
- 如何快速掌握DDT数据驱动测试?
1.前言 (网盗概念^-^)相同的测试脚本使用不同的测试数据来执行,测试数据和测试行为完全分离, 这样的测试脚本设计模式称为数据驱动.(网盗结束)当我们测试某个网站的登录功能时,我们往往会使用不同的用 ...
- Python Selenium 之数据驱动测试
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据.可以将测 ...
- Python+Selenium笔记(十二):数据驱动测试
(一) 前言 通过使用数据驱动测试,实现对输入值和预期结果的参数化.(例如:输入数据和预期结果可以直接读取Excel文档的数据) (二) ddt 使用ddt执行数据驱动测试,ddt库可以将测试 ...
- python - 数据驱动测试 - ddt
# -*- coding:utf-8 -*- ''' @project: jiaxy @author: Jimmy @file: study_ddt.py @ide: PyCharm Communit ...
- Python Selenium 之数据驱动测试的实现
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据.可以将测 ...
- 【python接口自动化】- DDT数据驱动测试
简单介绍 DDT(Date Driver Test),所谓数据驱动测试,简单来说就是由数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变.通过使用数据驱动测试的方法,可以在需要验证多组数据 ...
- 【python】以souhu邮箱为例学习DDT数据驱动测试
前言 DDT(Data-Driven Tests)是针对 unittest 单元测试框架设计的扩展库.允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例.通俗理解为相同的测试脚本使用不 ...
随机推荐
- Appium获取toast消息遇到的问题(一)
一.运行错误 Android获取toast,需要在参数里设置automationName:Uiautomator2 1 # 设置设备的信息 2 desired_caps = { 3 'platform ...
- Apache Hudi 与 Hive 集成手册
1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份HDFS数据,可以通过Spark,Flink 组件或者Hudi客户端将Hudi表的数据映射为Hive外部表,基于该外部表, Hive可以方 ...
- 为什么在集合中不能使用int关键字作为类型
解释: 1.Int是基本数据类型,Integer是Int的引用类型,定义集合的时候不能使用基本数据类型,需要使用对应的引用类型 2.int是基本数据类型,Integer是他的包装类,包装类主要用在类型 ...
- QPS和TPS的区别于理解
TPS: (每秒事务处理量(TransactionPerSecond)) 一个表达系统处理能力的性能指标,每秒处理的消息数(Transaction Per Second),每秒事务处理量 - 性能测试 ...
- 分布式事务之TCC事务模型
一.引言 在上篇文章<老生常谈--利用消息队列处理分布式事务>一文中留了一个坑,今天来填坑.如下图所示 如果服务A和服务B之间是同步调用,比如服务C需要按流程调服务A和服务B,服务A和服务 ...
- Explain的详细使用
官方文档 https://dev.mysql.com/doc/refman/5.7/en/explain-output.html explain俩种类型 explain extended 会在 exp ...
- [BUUCTF]PWN12——[BJDCTF 2nd]r2t3
[BUUCTF]PWN12--[BJDCTF 2nd]r2t3 题目网址:https://buuoj.cn/challenges#[BJDCTF%202nd]r2t3 步骤: 例行检查,32位,开启了 ...
- 数据库函数(Excel函数集团)
此处文章均为本妖原创,供下载.学习.探讨! 文章下载源是Office365国内版1Driver,如有链接问题请联系我. 请勿用于商业! 谢谢 下载地址:https://officecommunity- ...
- 什么是甘特图(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 名词解释:"甘特图(Gantt Chart)是一种图形化的项目活动及其他相关系统进度情况的水平方向的条状图.&q ...
- 🏆【CI/CD技术专题】「Docker实战系列」(1)本地进行生成镜像以及标签Tag推送到DockerHub
背景介绍 Docker镜像构建成功后,只要有docker环境就可以使用,但必须将镜像推送到Docker Hub上去.创建的镜像最好要符合Docker Hub的tag要求,因为在Docker Hub注册 ...