1.ElasticSearch相关概念
1.为ElasticSearch设置跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
2.什么是ElasticSearch
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
3.Elasticsearch类比传统关系型数据库
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
4.ElasticSearch的核心概念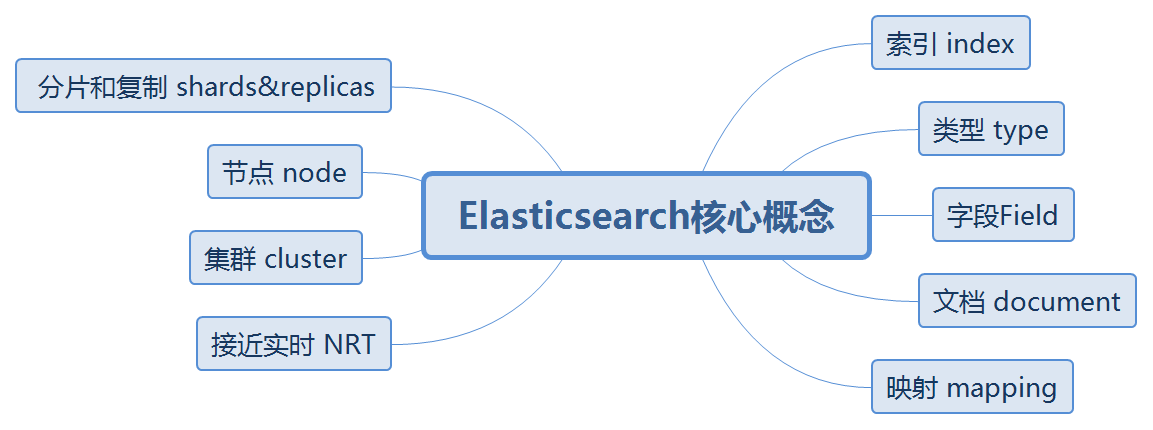
4.1 什么是索引
一个索引就是一个拥有几分相似特征的文档的集合。
比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
在一个集群中,可以定义任意多的索引。
4.2 什么是类型
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。
通常,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。
在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
4.3 什么是字段
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4.3 什么是映射
mapping是处理数据的方式和规则方面做一些限制
如某个字段的数据类型、默认值、分析器、是否被索引等等,
这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,
并且需要思考如何建立映射才能对性能更好。
4.4 什么是文档
一个文档是一个可被索引的基础信息单元。
比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。
文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
4.5 什么是接近实时
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
4.6 什么是集群
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
4.7 什么是节点
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。
这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。
而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
4.8 什么是分片和复制
一个索引可以存储超出单个结点硬件限制的大量数据。
比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;
或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了
这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。
为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。
因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。
一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),
这样的话每个索引总共就有10个分片。
1.ElasticSearch相关概念的更多相关文章
- ElasticSearch相关概念与客户端操作
一.Elasticsearch概述 Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document).然而它不仅仅是存储,还会索引(i ...
- Elasticsearch相关概念了解
mysql ⇒数据库databases ⇒表tables ⇒ 行rows ⇒ 列columns es ⇒索引indices ⇒ 类型types ...
- Elasticsearch基础知识分享
1. Elasticsearch背景介绍 Elasticsearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elast ...
- Elasticsearch 集群和索引健康状态及常见错误说明
之前在IDC机房线上环境部署了一套ELK日志集中分析系统, 这里简单总结下ELK中Elasticsearch健康状态相关问题, Elasticsearch的索引状态和集群状态传达着不同的意思. 一. ...
- 分布式爬虫之elasticsearch基础1
一:搜索引擎elasticsearch介绍 Elasticsearch 是一个全文搜索引擎,可以快速地储存.搜索和分析海量数据. 二:应用场景 海量数据分析引擎 站内搜索引擎 数据仓库 三:安装 我们 ...
- ELK学习笔记之ElasticSearch简介
0x00 什么是Elasticsearch Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定.可靠.快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的 ...
- 如何在python中使用Elasticsearch
什么是 Elasticsearch 想查数据就免不了搜索,搜索就离不开搜索引擎,百度.谷歌都是一个非常庞大复杂的搜索引擎,他们几乎索引了互联网上开放的所有网页和数据.然而对于我们自己的业务数据来说 ...
- MacOS下ElasticSearch学习(第一天)
ElasticSearch第一天 学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"elasticsearch&q ...
- Elastic Stack-Elasticsearch介绍
一.前言 前篇写了好像没有多少人去看,但是还是要继续,我猜想可能是很多人接触的这块比较少吧,Elasticsearch这块有很多要说的,开始吧. 二.数据库.Elasticsearch选择 ...
随机推荐
- (五)MySQL函数
5.1 常用函数 5.2 聚合函数(常用) 函数名称 描述 COUNT() 计数 SUM() 求和 AVG() 平均值 MAX() 最大值 MIN() 最小值 .... .... 想查询一 ...
- 菜鸡的Java笔记 国际化程序实现原理
国际化程序实现原理 Lnternationalization 1. Locale 类的使用 2.国家化程序的实现,资源读取 所谓的国际化的程序 ...
- [bzoj5418]屠龙勇士
很显然,每一步所选的剑和怪物都是确定的,可以先求出来(不用写平衡树,直接用multiset即可,注意删除要删指针,以下假设第i次攻击用ki攻击的剑,攻击第i只怪) 首先判断无解,即如果存在ai使得g ...
- 2020第十三届全国大学生信息安全竞赛创新实践能力赛rceme writerup
审计代码 传入参数a,进入parserIfLabel函数 发现参数a的模板,a的格式要匹配pattern,如{if:payload}{end if} 可知ifstr是a中匹配的第一组的值,即paylo ...
- C/C++ Qt 选择夹TabWidget组件应用
在Qt中通过使用选择夹组件可以实现在一个页面中集成多种功能,我们以TabWidget选择夹组件为例,实现在单个页面中集成多个功能,并给每一个子夹增加对应的Ico图标. 如果我们使用选择夹组件,必须提前 ...
- 从零开始学Kotlin第四课
面向对象: //妹子 性格 声音 class Girl(var chactor:String,var voice:String) fun main(args: Array<String>) ...
- 【AWS】使用X-Ray做AWS云上全链路追踪监控系统
功能 AWS X-Ray 是一项服务,收集应用程序所请求的相关数据,并提供用于查看.筛选和获取数据洞察力的工具,以确定问题和发现优化的机会. 对于任何被跟踪的对您应用程序的请求,不仅可以查看请求和响应 ...
- Codeforces 1188B - Count Pairs(思维题)
Codeforces 题面传送门 & 洛谷题面传送门 虽说是一个 D1B,但还是想了我足足 20min,所以还是写篇题解罢( 首先注意到这个式子里涉及两个参数,如果我们选择固定一个并动态维护另 ...
- 洛谷 P5332 - [JSOI2019]精准预测(2-SAT+bitset+分块处理)
洛谷题面传送门 七月份(7.31)做的题了,题解到现在才补,不愧是 tzc 首先不难发现题目中涉及的变量都是布尔型变量,因此可以考虑 2-SAT,具体来说,我们将每个人在每个时刻的可能的状态表示出来. ...
- 洛谷 P4426 - [HNOI/AHOI2018]毒瘤(虚树+dp)
题面传送门 神仙虚树题. 首先考虑最 trival 的情况:\(m=n-1\),也就是一棵树的情况.这个我相信刚学树形 \(dp\) 的都能够秒掉罢(确信).直接设 \(dp_{i,0/1}\) 在表 ...