1.ElasticSearch相关概念
1.为ElasticSearch设置跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
2.什么是ElasticSearch
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
3.Elasticsearch类比传统关系型数据库
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
4.ElasticSearch的核心概念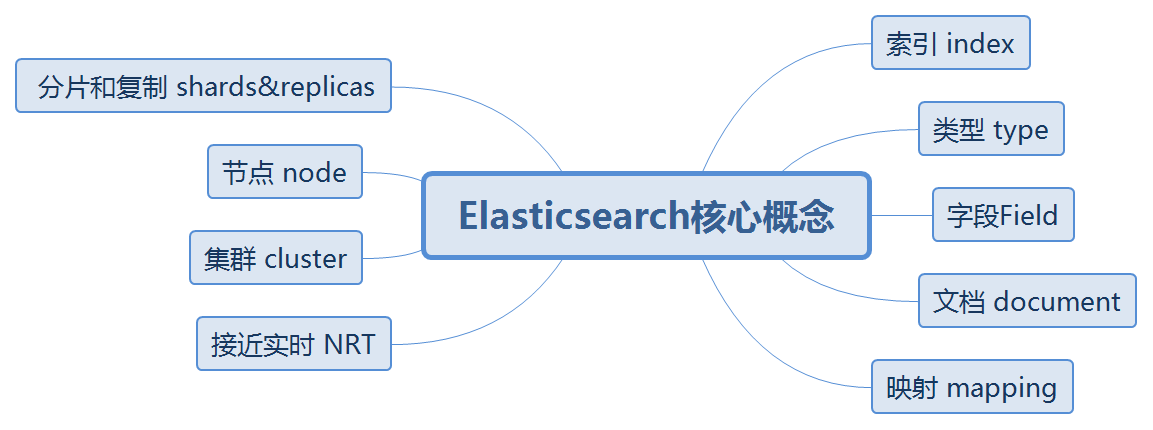
4.1 什么是索引
一个索引就是一个拥有几分相似特征的文档的集合。
比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
在一个集群中,可以定义任意多的索引。
4.2 什么是类型
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。
通常,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。
在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
4.3 什么是字段
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4.3 什么是映射
mapping是处理数据的方式和规则方面做一些限制
如某个字段的数据类型、默认值、分析器、是否被索引等等,
这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,
并且需要思考如何建立映射才能对性能更好。
4.4 什么是文档
一个文档是一个可被索引的基础信息单元。
比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。
文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
4.5 什么是接近实时
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
4.6 什么是集群
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
4.7 什么是节点
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。
这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。
而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
4.8 什么是分片和复制
一个索引可以存储超出单个结点硬件限制的大量数据。
比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;
或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了
这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。
为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。
因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。
一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),
这样的话每个索引总共就有10个分片。
1.ElasticSearch相关概念的更多相关文章
- ElasticSearch相关概念与客户端操作
一.Elasticsearch概述 Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document).然而它不仅仅是存储,还会索引(i ...
- Elasticsearch相关概念了解
mysql ⇒数据库databases ⇒表tables ⇒ 行rows ⇒ 列columns es ⇒索引indices ⇒ 类型types ...
- Elasticsearch基础知识分享
1. Elasticsearch背景介绍 Elasticsearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elast ...
- Elasticsearch 集群和索引健康状态及常见错误说明
之前在IDC机房线上环境部署了一套ELK日志集中分析系统, 这里简单总结下ELK中Elasticsearch健康状态相关问题, Elasticsearch的索引状态和集群状态传达着不同的意思. 一. ...
- 分布式爬虫之elasticsearch基础1
一:搜索引擎elasticsearch介绍 Elasticsearch 是一个全文搜索引擎,可以快速地储存.搜索和分析海量数据. 二:应用场景 海量数据分析引擎 站内搜索引擎 数据仓库 三:安装 我们 ...
- ELK学习笔记之ElasticSearch简介
0x00 什么是Elasticsearch Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定.可靠.快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的 ...
- 如何在python中使用Elasticsearch
什么是 Elasticsearch 想查数据就免不了搜索,搜索就离不开搜索引擎,百度.谷歌都是一个非常庞大复杂的搜索引擎,他们几乎索引了互联网上开放的所有网页和数据.然而对于我们自己的业务数据来说 ...
- MacOS下ElasticSearch学习(第一天)
ElasticSearch第一天 学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"elasticsearch&q ...
- Elastic Stack-Elasticsearch介绍
一.前言 前篇写了好像没有多少人去看,但是还是要继续,我猜想可能是很多人接触的这块比较少吧,Elasticsearch这块有很多要说的,开始吧. 二.数据库.Elasticsearch选择 ...
随机推荐
- Sentry 官方 JavaScript SDK 简介与调试指南
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- 面试官问我Redis集群,我真的是
面试官:聊下Redis的分片集群,先聊 Redis Cluster好咯? 面试官:Redis Cluser是Redis 3.x才有的官方集群方案,这块你了解多少? 候选者:嗯,要不还是从基础讲起呗? ...
- 应用程序池自动停止,事件查看器报错6D000780
20210913 今天中午网站突然报错,后台程序无法访问,503错误. 调查发现"应用程序池"被关闭,但是手动开启后不久,又被关闭. 本地调试没问题,所以一开始怀疑是服务器或者Ng ...
- 咸阳市大数据管理局使用Rainbond作为智慧城市底座的实践
使用 Rainbond 作为智慧城市底座之后,给我们带来了成倍的运维效率提升. -- 咸阳市大数据管理局 熊礼智 咸阳市大数据管理局负责全市信息共享工作的组织领导,协调解决与政府信息共享有关的重大问题 ...
- Linux远程软件
Xhell6:Linux的终端模拟软件 1>安装并破解:解压.破解(运行两个.bat文件).启动(点击Xshell.exe文件) 2>连接远端Linux系统: 创建会话:点击连接,在常规框 ...
- 【POJ1961 Period】【KMP】
题面 一个字符串的前缀是从第一个字符开始的连续若干个字符,例如"abaab"共有5个前缀,分别是a, ab, aba, abaa, abaab. 我们希望知道一个N位字符串S的前缀 ...
- spring-boot spring-MVC自动配置
Spring MVC auto-configuration Spring Boot 自动配置好了SpringMVC 以下是SpringBoot对SpringMVC的默认配置:==(WebMvcAuto ...
- R包MetaboAnalystR安装指南(Linux环境非root)
前言 这是代谢组学数据分析的一个R包,包括用于代谢组学数据分析.可视化和功能注释等众多功能.最近有同事在集群中搭建蛋白和代谢流程,安装这个包出现了问题,于是我折腾了一上午. 这个包的介绍在:https ...
- R语言因子排序
画图的时候,排序是个很重要的技巧,比如有时候会看下基因组每条染色体上的SNP的标记数量,这个时候直接做条形图是一种比较直观的方法,下面我们结合实际例子来看下: 在R环境下之际构建一个数据框,一列染色体 ...
- centos下Spin Version 6.3.2及ispin安装(2014.9.17)
centos下Spin Version 6.3.2及ispin安装(2014.9.17) 前言:windos下首先安装虚拟机,再安装linux系统(centos版) 一.本帖来源于官网http://s ...