sql server 索引阐述系列三 表的堆组织
一. 概述
这一节来详细介绍堆组织,通过讲解堆的结构,堆与非聚集索引的关系,堆的应用场景,堆与聚集索引的存储空间占用,堆的页拆分现象,最后堆的使用建议 ,这几个维度来描述堆组织。在sqlserver里,表有二种组织方式,在表上没有创建聚集索引时,表就是堆组织, 有聚集索引就是B树组织。无论哪种组织方式,都可以在表上建多个非聚集索引。表的组织方式也称为HOBT。
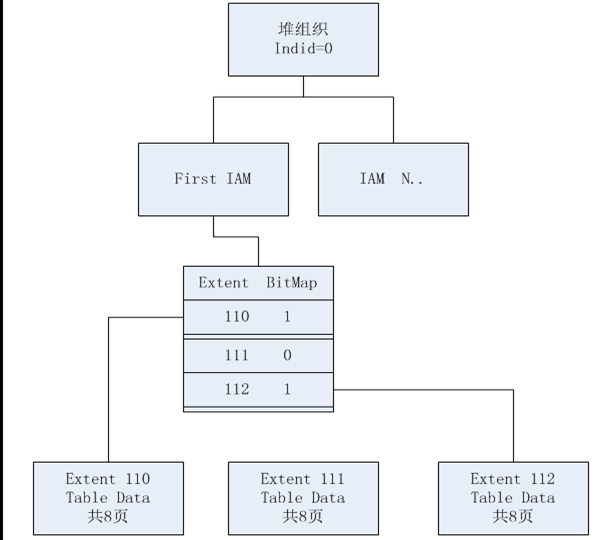
之所以称为堆,是因为它的数据不按任何顺序进行组织,而是按分区组对数据进行组织。 在一个堆中。用于保存数据之间的关系的唯一结构是索引分配映射(IAM , index allocation map)的位图页,上一章节中有说过页文件类型。
IAM位图页有指向数据页的指针,如果一个IAM不足以覆盖所有页,将维护一个IAM页的链,在查询数据时,先使用IAM页来遍历分配单元的数据。
堆结构在数据插入没有更改时是有存储顺序的,但一改动如修改删除,结构就会发生变化, 因为没有特定的顺序来维护数据, 所以在新增表中的行时,可以保存到任何数据页上。
Sql server内部使用文件页(PFS, Page Free Space)可用空间页,PFS位图来跟踪数据页中的可用空间, 以便可以快速找到有足够空间能容纳新行的页面,如果没有则分配一个新数据页面。
1.1 堆组织结构
在堆组织中对于一个select查询,首先查询IAM页,然后根据IAM页提供的信息,遍历每个区,把区内符合条件下的数据页返回,在堆中查询从上到下依次是Heap-->IAM-->区-->数据页。如下图所示:
1.2 堆上的非聚集索引
非聚集索引也可以结构化为一颗B树,与聚集索引类似,唯一区别就是非聚集索引的叶子层只包含索引键列和指向数据行的指针(行定位符)。如果是在堆上建立非聚集索引,则指针指向堆结构中的数据行
在堆中非聚集索引都有一个相对应的partition, 在这个partition下都有一个连接指向Root page根,在叶子层有会一个连接(文件号,页号,行号)指向真正的数据,真正的数据还是以堆结构存放的。在堆上建立的非聚集索引查询从上到下依次是Heap-->Root根-->root index中间层-->叶节点(文件号,页号,行号)-->数据页。如下图所示:

二. 堆应用场景
堆最常用的现象就是使用临时表,一般都很少会主动加clustered primary关键词,很多时间临时对象的应用也没有必要使用聚集索引。但如果临时表在会话里需要使用多次条件查询,排序 等操作,聚集索引则少一部分开销。下面演示下:
--创建临时表堆
CREATE TABLE #tempWithHeap([SID] INT, model VARCHAR(50))
--插入数据
INSERT INTO #tempWithHeap
SELECT [sid],model FROM dbo.Product WHERE UpByMemberID=3000
--查询
SELECT Product.* FROM Product
JOIN #tempWithHeap
ON #tempWithHeap.[SID] = dbo.Product.[SID]
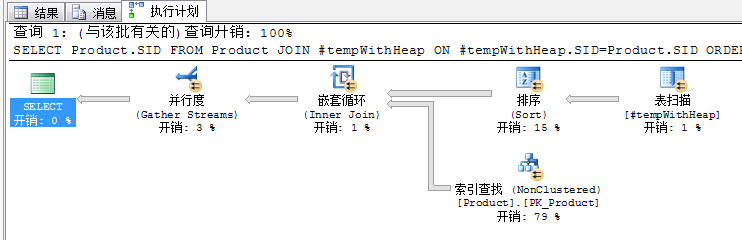
下图在执行计划里能看到临时表是表扫描方式

--创建临时表聚集
CREATE TABLE #tempWithCLUSTERED([SID] INT PRIMARY KEY CLUSTERED, model VARCHAR(50))
--插入
INSERT INTO #tempWithCLUSTERED
SELECT [sid],model FROM dbo.Product WHERE UpByMemberID=3000
--查询
SELECT Product.* FROM Product
JOIN #tempWithCLUSTERED
ON #tempWithCLUSTERED.[SID] = dbo.Product.[SID]
下图在执行计划里能看到临时表是聚集索引扫描方式
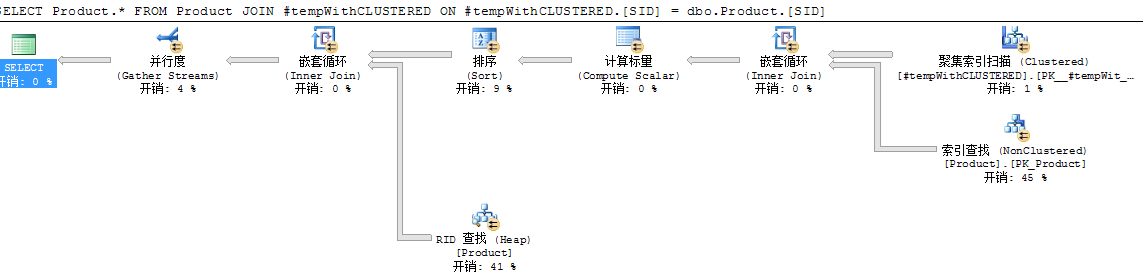
下面来演示堆和索引在排序下不同的执行计划
--临时表堆上排序
SELECT Product.SID FROM Product JOIN #tempWithHeap
ON #tempWithHeap.SID=Product.SID
ORDER BY #tempWithHeap.SID
在下图执行计划中排序显示开销15%
--临时表聚集索引上排序
SELECT Product.SID FROM Product JOIN #tempWithCLUSTERED
ON #tempWithCLUSTERED.SID=Product.SID
ORDER BY #tempWithCLUSTERED.SID
在下图执行计划中排序开销没有
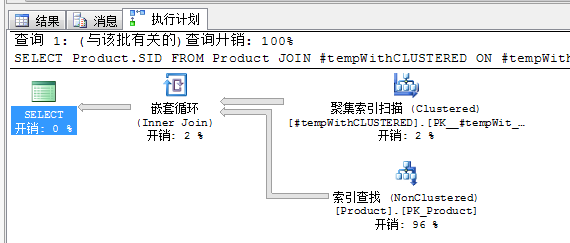
三.堆上的页拆分
堆上的页拆分叫Forwarded records,是指更新数据后,原有页面空间大小已经无法存放该数据,sql server 会把这个数据移到堆中的新数据页里,并在新旧页中分别添加一个指针,标识这个数据在新旧页中的位置,从旧页指向新页的指针叫Forwarded records pointer 存放于旧页中, 从新页指向旧页的指针叫作back pointer 存放于新页中。
下面来演示下页拆分现象
--这里定义一个堆表,使用变长字段2500
CREATE TABLE HeapForwardedRecords
(
ID INT IDENTITY(1,1),
DATA VARCHAR(2500)
)
--插入数据,这里data字段插入2000,插入24条
INSERT INTO HeapForwardedRecords(data)
SELECT TOP 24 REPLICATE('X',2000) FROM sys.objects --查看碎片信息
select OBJECT_NAME(object_id),object_id,
index_type_desc,page_count,record_count,
forwarded_record_count
from sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('HeapForwardedRecords') ,null,null,'Detailed')
下图显示:共6页,24条数据,页拆分0条。 (一行数据2000字节,一页存储4行, 24行共6页)

下面将data字段存储的2000字节,修改为2500字节,每页4行更新二行,原来一页存储4行(4*2000<8060),现更新后就是(2*2000 +2*2500)>8060字节,原页就只能存储三行,这时堆上的页就会拆分。
--更新数据,12行受影响
UPDATE HeapForwardedRecords SET DATA=REPLICATE('X',2500)
WHERE ID%2=0
再次查看碎片信息,发现原来6页存储变为了9页, forwarded_record_count是指页拆分次数(是指向另一个数据位置的指针的记录数,在更新过程中,如果在原始位置存储的空间不足,将会出现此状态) 如下图:

总结:通过sys.dm_db_index_physical_stats 我们可以查询到碎片信息,page count的页数越多,内存消耗就越多。 要整理碎片可以重建聚集索引。若要减少堆的区碎片,请对表创建聚集索引,然后删除该索引。更多碎片信息查看 https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms188917(v=sql.105)
如下图:forwarded_record_count为0了

四.堆存储结构对空间使用的影响
4.1 等量数据的存储方式,使用DBCC SHOWCONFIG来查看
下面演示表结构相同情况下在堆组织和聚集索引组织二种方式, 存储等量数据,来查看空间的占用。
--堆表
CREATE TABLE [dbo].[ProductWithDeap](
[SID] [int] IDENTITY(1,1) NOT NULL,
[Model] [nvarchar](100) NULL,
[Brand] [nvarchar](100) NULL,
[UpdateTime] [datetime] NULL,
[UpByMemberID] [int] NULL,
[UpByMemberName] [nvarchar](200) NULL)
ON [PRIMARY]
--插入表堆数据(60703 行)
INSERT INTO ProductWithDeap(Model,Brand,UpdateTime,UpByMemberID,UpByMemberName)
SELECT Model,Brand,UpdateTime,UpByMemberID,UpByMemberName FROM dbo.Product
WHERE UpByMemberID=3000
--聚集索引
CREATE TABLE [dbo].[ProductWithClustered](
[SID] [int] IDENTITY(1,1) NOT NULL,
[Model] [nvarchar](100) NOT NULL,
[Brand] [nvarchar](100) NULL,
[UpdateTime] [datetime] NULL,
[UpByMemberID] [int] NULL,
[UpByMemberName] [nvarchar](200) NULL,
CONSTRAINT [PK_ProductWithClustered] PRIMARY KEY CLUSTERED
(
[SID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
)
--插入表聚集数据(60703 行)
INSERT INTO ProductWithClustered(Model,Brand,UpdateTime,UpByMemberID,UpByMemberName)
SELECT Model,Brand,UpdateTime,UpByMemberID,UpByMemberName FROM dbo.Product
WHERE UpByMemberID=3000

| 存储方式 | 使用页面数量 | 使用区数量 |
| 堆组织 | 517 | 69 |
| 聚集索引 | 518 | 66 |
4.2 删除数据后,对空间的释放情况
delete from ProductWithDeap
delete from ProductWithclustered

| 存储方式 | 剩余空间数量 | 剩余区数量 |
| 堆组织 | 50 | 11 |
| 聚集索引 | 1 | 1 |
使用delete后我们发现,建立堆组织的空间不会马上释放掉,聚集索引能很好的释放空间,但也存在1页未释放,如果完全释放使用truncate table。
总结:当我们考虑表是用堆组织还是用聚集索引时,通过上面的演示我们知道,聚集索引的叶子层就是数据本身,并不会因为建立聚集索引而消耗过多的空间(注意非聚集索引会占用空间,不管是建立在堆组织上还是聚集索引上),而且能够更好的管理数据和空间的释放。除非特殊情况(后面有选择堆的理由)
五.堆的使用建议
5.1堆需要考虑点
过多的产生forwarded records 来维护堆表,产生额外的io操作。
5.2 堆选择理由
高频率的增删操作。
键值经常改变,特别在索引上的位置改变。
插入大量数据列到表中。
主键值并不自增或者唯一。
sql server 索引阐述系列三 表的堆组织的更多相关文章
- sql server 索引阐述系列四 表的B-Tree组织
一.概述 说到B-tree组织,就是指索引,它可以提供了对数据的快速访问.索引使数据以一种特定的方式组织起来,使查询操作具有最佳性能.当数据表量变得越来越大,索引就变得十分明显,可以利用索引查找快速满 ...
- sql server 索引阐述系列一索引概述
一. 索引概述 关于介绍索引,有一种“文章太守,挥毫万字,一饮千钟”的豪迈感觉,因为索引需要讲的知识点太多.在每个关系型数据库里都会作为重点介绍,因为索引关系着数据库的整体性能, 它在数据库性能优化里 ...
- sql server 索引阐述系列八 统计信息
一.概述 sql server在快速查询值时只有索引还不够,还需要知道操作要处理的数据量有多少,从而估算出复杂度,选择一个代价小的执行计划,这样sql server就知道了数据的分布情况.索引的统计值 ...
- sql server 索引阐述系列二 索引存储结构
一.概述. "流光容易把人抛,红了樱桃,绿了芭蕉“ 转眼又年中了,感叹生命的有限,知识的无限.在后续讨论索引之前,先来了解下索引和表数据的内部结构,这一节将介绍页的存储,页分配单元类型,区的 ...
- sql server 索引阐述系列六 碎片查看与解决方案
一 . dm_db_index_physical_stats 重要字段说明 1.1 内部碎片:是avg_page_space_used_in_percent字段.是指页的填充度,为了使磁盘使用状况达到 ...
- sql server 索引阐述系列五 索引参数与碎片
-- 创建聚集索引 create table [dbo].[pub_stocktest] add constraint [pk_pub_stocktest] primary key clustered ...
- sql server 索引阐述系列七 索引填充因子与碎片
一.概述 索引填充因子作用:提供填充因子选项是为了优化索引数据存储和性能. 当创建或重新生成索引时,填充因子的值可确定每个叶级页上要填充数据的空间百分比,以便在每一页上保留一些剩余存储空间作为以后扩展 ...
- 【目录】sql server 进阶篇系列
随笔分类 - sql server 进阶篇系列 sql server 下载安装标记 摘要: SQL Server 2017 的各版本和支持的功能 https://docs.microsoft.com/ ...
- SQL Server索引进阶:第三级,聚集索引
原文地址: Stairway to SQL Server Indexes: Level 3, Clustered Indexes 本文是SQL Server索引进阶系列(Stairway to SQL ...
随机推荐
- MySQL忘记密码怎么修改密码
MySQL的 root 帐号密码默认为空,经常都有修改密码后忘记密码的事.如果忘记了root 帐号密码,那该怎么修改密码呢?这里有一个可行的方法,就是在MySQL安全模式下(跳过权限检查)修改密码的方 ...
- mybatis中怎样使用having?
1.dao层代码 List<ErgTipSimpleBo> queryListMore(@Param("typeId") Integer typeId,@Param(& ...
- HttpWebRequest请求Https协议的WebApi
public static class RequestClient { /// <summary> /// 参数列表转为string /// </summary> /// &l ...
- centos 下Python独立虚拟环境创建
virtualenv Python有着庞大的开源社区的支持,很自然就产生这么一个问题:第三方包参差不齐,如果我们想在服务器测试,或者升级某个包,就会导致生产环境产生杂乱,多余的第三方依赖包. virt ...
- <笔记>三码合一
讲求三码合一,何为三码合一?(这里我用UTF8讲例子) 就是页面编码,文档编码,数据库编码要统一一种格式,切记不可有的是GBK,有的是UFT8 页面编码:也就是用header 函数申明:header( ...
- NUC970开发板烧录
本次烧录的采用新塘公司官方的NuWriter软件进行烧录,现在我们首先来讲解如何将uboot,Linux内核,根文件系统烧录到开发板上. 过程中所需文件链接: 链接:https://pan.baidu ...
- java(三)数据库部分
3.1.1.数据库的分类及常用的数据库 数据库分为:关系型数据库和非关系型数据库 关系型:mysql oracle sqlserver等 非关系型:redis,memcache,mogodb,hado ...
- impala教学视频
https://www.iqiyi.com/playlist394935102.html
- hbuilder下用plus.barcode.Barcode做二维码扫描,当二维码容器的高度设置过低时,启动扫描会发生闪退
解决办法: 将固定高度改为百分比
- Zookeeper在Linux平台Java开发环境配置(命令行)
1.安装必要软件 首先需要安装ant, automake, autoconf, cppunit.在ubuntu上可以直接用apt-get install安装 2.Build Zookeeper 切换到 ...