Python学习笔记【第八篇】:Python内置模块
什么时模块
Python中的模块其实就是XXX.py 文件
模块分类
Python内置模块(标准库)
自定义模块
第三方模块
使用方法
import 模块名
form 模块名 import 方法名
说明:实际就是运行了一遍XX.py 文件
导入模块也可以取别名
如: import time as t
import time as t
print(t.time())
定位模块
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
- 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
- 模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
自定义模块
我们自己写的XX.py 文件就是一个模块,在项目中可以引用这个模块调用里面的方法。
__all__[]关键字
__all__ = ["函数名","类名","方法名"]
没有all关键字 所有方法都可以访问到
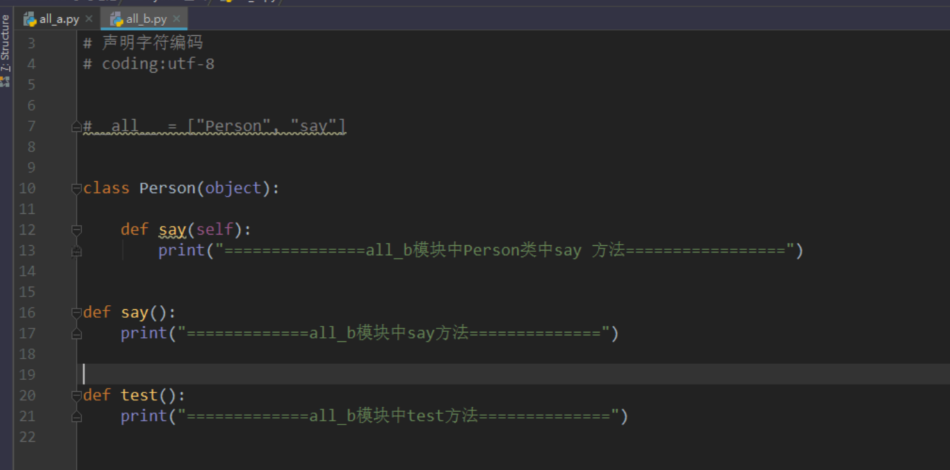
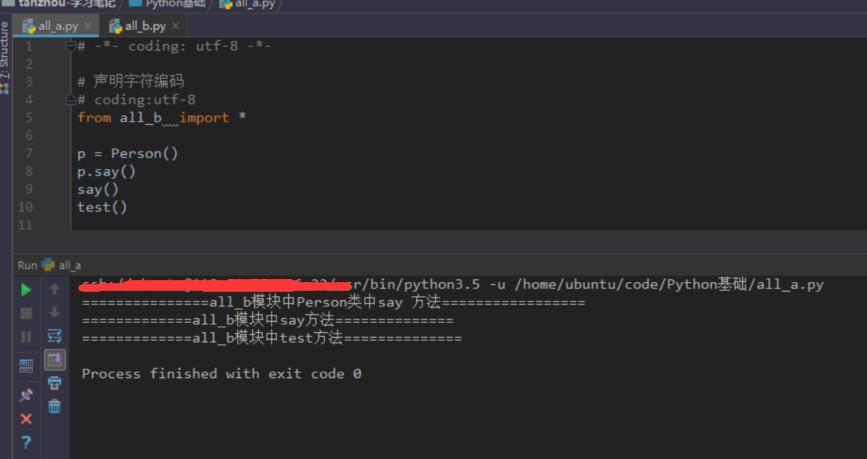
使用all关键字
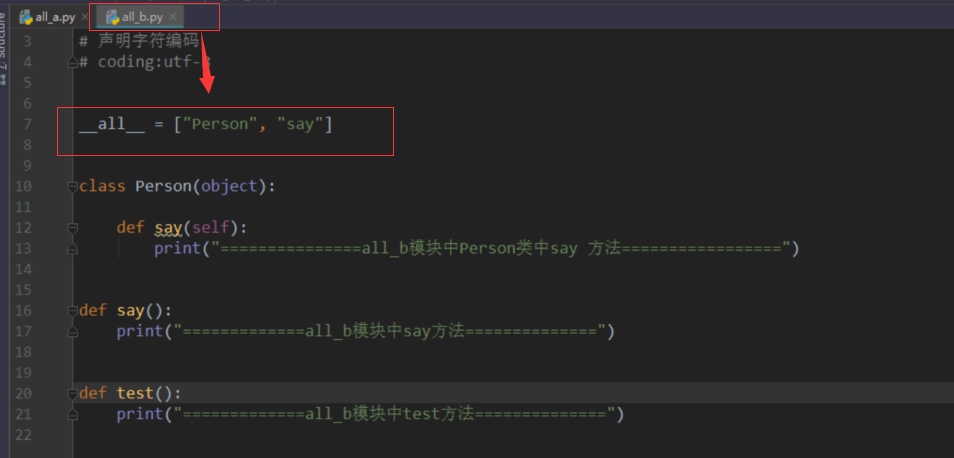
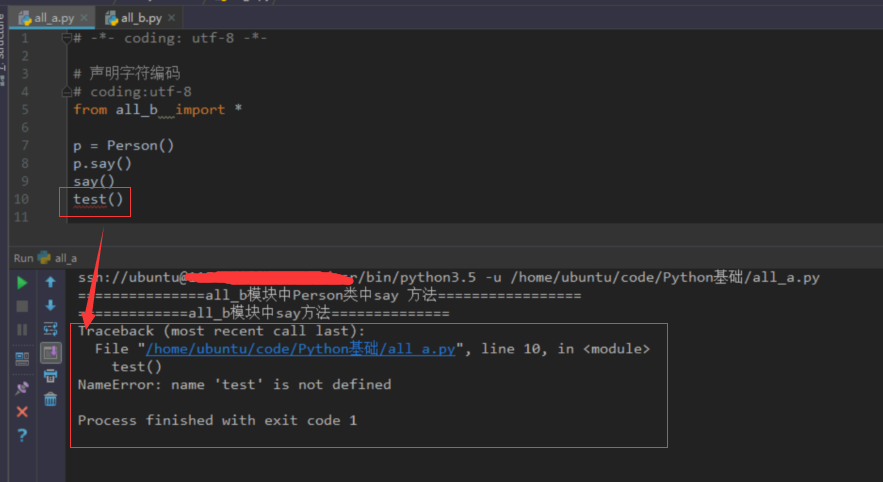
总结
- 如果一个文件中有__all__变量,那么也就意味着不在这个变量中的元素,不会被from xxx import *时导入
模块包
模块包就是为了防止模块重名
两个模块在同一个文件夹里 并且有个__init__.py 文件
__init__.py 文件内容
# -*- coding: utf-8 -*- # 声明字符编码
# coding:utf-8 # 在外部文件中 import all中的模块
__all__ = ["receMsage","myModelDemo"] #"myModelDemoOne" import sys
sys.path.append('/home/ubuntu/code/Python核心编程') print(sys.path)
# 外部文件中访问模块中的方法
from.import receMsage
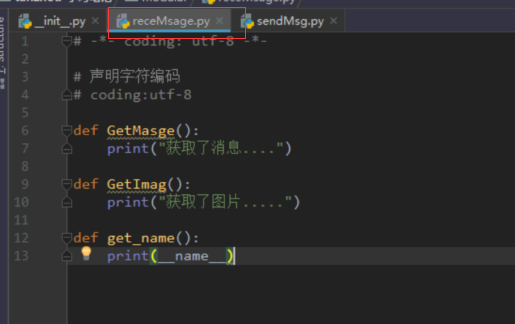
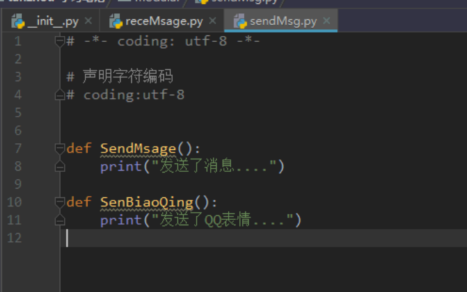
使用:

总结:
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为
__init__.py文件,那么这个文件夹就称之为包 - 有效避免模块名称冲突问题,让应用组织结构更加清晰
标准库
import os
import sys
import random
import time
import datetime
import json
import pickle
import shelve
import xml.etree.ElementTree as et
import xml
import configparser
import hashlib
import logging
import re
笔记
def time_test():
print('\r\n============time时间模块测试============\r\n')
"""
1:时间戳:time.time() 1970 1 1 0点 秒数
2:结构化时间: time.localtime() 和 time.gmtime() 返回的是时间对象(tm_year,tm_mon,tm_wday)
3:字符串时间 """
print("时间戳:%s" % time.time())
t1 = time.localtime()
# print(dir(t1))
print('返回时间对象:%s 年 %s 月 %s 日' % (t1.tm_year, t1.tm_mon, t1.tm_mday))
# t2 = time.gmtime()
# print(dir(t2))
# 时间戳转为时间对象(结构化时间)
t3 = time.localtime()
print(t3)
# 将结构化时间转为时间戳
t4 = time.mktime(t3)
print(t4) # 将结构化时间转字符串时间
t5 = time.strftime("%Y-%m-%d %X", t3)
print(t5)
t8 = time.asctime(t3)
print(t8) # 将字符串时间转为结构化时间
t6 = time.strptime(t5, '%Y-%m-%d %X')
print(t6) # 将时间戳转为特定的字符串时间
t7 = time.ctime(t4)
print(t7) # 睡眠多少秒才继续执行
# time.sleep(2) def random_test():
print('\r\n============random模块测试============\r\n')
print(random.random()) # 0-1 返回float类型
print(random.randint(1, 10)) # 1-10 整形
print(random.randrange(1, 10))
print(random.choice([1, 'a', 3, 'w', 5])) # 随机返回列表中的数据
print(random.sample(['b', 'z', 1, 3, 'he', 4, '我'], 4)) # 随机返回集合中的内容4个 # 验证码
def v_code(n):
result = ""
for i in range(n):
# 随机数字
num = random.randint(0, 9)
# 随机字母
f = chr(random.randint(65, 122))
s = str(random.choice([num, f]))
result += s
return result # 调用
print("随机验证码:%s" % (v_code(5))) def os_test():
print('\r\n============OS模块测试============\r\n')
# 获取当前文件路径
print(os.getcwd())
# 创建文件夹
# os.makedirs("makdir")
# 删除文件夹
# os.removedirs('makdir') # 获取当前文件同级的所有文件
print(os.listdir()) # 获取文件信息
print(os.stat("11-lnh-python模块.py")) print(os.name)
# 获取绝对路径
print(os.path.abspath("makdir")) a = "User/Administrator"
c = "python/基础"
print(os.path.join(a, c)) def sys_test():
print('\r\n============sys模块测试============\r\n')
"""
sys.argv # 执行参数List ,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解析程序的版本信息
sys.maxint # 最大的Int值
sys.path # 返回模块的搜索路径,初始时使用Python环境变量的值
sys.platform # 返回操作系统平台名称 """
print(sys.platform)
print(sys.path)
print(sys.version)
# print("程序准备退出...")
# sys.exit(0)
# print('程序退出后....')
# 接收参数 ['11-lnh-python模块.py', 'select', '12']
print(sys.argv) for i in range(100):
# 打完后一次性显示
sys.stdout.write('#')
# time.sleep(1)
# # 立刻刷新
# sys.stdout.flush() def json_test():
print("\r\n==================json模块测试==================\r\n")
js = {
'name': 'BeJson',
"url": "http://www.bejson.com",
"page": 88,
"isNonProfit": True,
"address": {
"street": "科技园路.",
"city": "江苏苏州",
"country": "中国"
},
"links": [
{
"name": "Google",
"url": "http://www.google.com"
},
{
"name": "Baidu",
"url": "http://www.baidu.com"
},
{
"name": "SoSo",
"url": "http://www.SoSo.com"
}
]
}
# # json 转字符串(将所有的单引号转为双引号)
# jd = json.dumps(js)
# print(jd)
# with open("../files/BeJson", "w", encoding="utf-8") as f:
# f.write(jd) # ----------->json.dump(js,f)
# print("保存磁盘完成") # 读取数据
with open("../files/BeJson", "r", encoding="utf-8") as f:
# 将字符串转为字典
jl = json.loads(f.read()) # -------->json.load(f)
print(jl)
print(type(jl)) def pickle_test():
print("\r\n==================pickle模块测试==================\r\n")
js = {
'name': 'BeJson',
"url": "http://www.bejson.com",
"page": 88,
"isNonProfit": True,
"address": {
"street": "科技园路.",
"city": "江苏苏州",
"country": "中国"
},
"links": [
{
"name": "Google",
"url": "http://www.google.com"
},
{
"name": "Baidu",
"url": "http://www.baidu.com"
},
{
"name": "SoSo",
"url": "http://www.SoSo.com"
}
]
}
# 将字符串序列化为字节
data = pickle.dumps(js)
print(data)
print("序列化后类型为:%s" % type(data))
# 将字符串字节转为字典
da = pickle.loads(data)
print(da)
print("loads序列化类型为:%s" % type(da)) def shelve_test():
print("\r\n==================shelve模块测试==================\r\n")
# # 数据传输
# js = {
# 'name': 'BeJson',
# "url": "http://www.bejson.com",
# "page": 88,
# "isNonProfit": True,
# "address": {
# "street": "科技园路.",
# "city": "江苏苏州",
# "country": "中国"
# },
# "links": [
# {
# "name": "Google",
# "url": "http://www.google.com"
# },
# {
# "name": "Baidu",
# "url": "http://www.baidu.com"
# },
# {
# "name": "SoSo",
# "url": "http://www.SoSo.com"
# }
# ]
# }
# # 拿到文件的句柄返回的是一个字典类型
# f = shelve.open(r"../files/ShelveJson") # 将字典放入文本
# f["Info"] = js
# f.close() # 取值
f = shelve.open(r"../files/ShelveJson")
print(f.get("Info")["name"]) def xml_test():
print("\r\n==================XML模块测试==================\r\n")
# 读取xml文件
tree = et.parse("../files/app")
root = tree.getroot()
for i in root:
print(i.tag)
print(i.attrib)
a = 0
for j in i: # ---> i.iter('add') 只便利指定节点
# 获取节点名称
print(j.tag)
# 获取属性值
print(j.attrib)
# 获取便签内容 <name>张三</name> ----> 得到:张三
print(j.text) # 新增节点属性
# j.set("index", '1')
a += 1
# tree.write("../files/app") # 遍历指定节点内容
tree = et.parse("../files/app")
root = tree.getroot()
for i in root:
print(i.tag)
print(i.attrib)
a = 0
for j in i.iter('add'): # ---> i.iter('add') 只便利指定节点
print(j.attrib) def regex_test():
print("\r\n==================re模块测试==================\r\n")
# 正则就是做模糊匹配
with open("../files/retext", "r", encoding="utf-8") as f:
str = f.read()
print(str)
print(re.findall('href', str)) # 分组 返回匹配的第一个
r1 = re.search("(?P<name>[a-z]+)\d+", "zhangsan15lisi23").group('name')
print(r1)
r2 = re.search("(?P<name>[a-z]+)(?P<age>\d+)", "zhangsan15lisi23").group('age')
print(r2) # 返回匹配的第一个
r3 = re.match("\d+", "154alix12lisi45xiaoming25").group()
print(r3) # 以什么分割返回分割的数组
r4 = re.split('[ |]', 'rer|eabc jiklabc|ljiabcjijk')
print(r4)
r5 = re.split('[ab]', 'asdabcd')
print(r5) # 替换:匹配规则 替换内容 原类容 匹配次数
r6 = re.subn('\d', 'A', 'fjlfjsl212jkj343ljlj', 3)
print(r6) # 编译 (可多次使用)
r7 = re.compile('\d+')
f1 = r7.findall('sfsf4sfsf455sffs451dfsa5')
print(f1) # 功能方法和findall一样,只不过返回的是一个迭代器(适用于大数据的处理)
rf = re.finditer('\d', 'fsdf1fsf151sfsfasf84885afasf874af')
r8 = next(rf).group()
print(r8) # ?: 表示去掉优先级
r9 = re.findall('www\.(?:baidu|163)\.com', 'www.baidu.com')
print(r9) def logging_test():
print('\n==================logging模块测试=====================\n') """
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
""" # ====================basicConfig=====================
# 日志级别 debug info warning error critical
# print('默认等级输出:')
# logging.debug('debug日志')
# logging.info('info日志')
# logging.warning('warning日志')
# logging.error('error日志')
# logging.critical('critical日志')
#
# # 以上默认打印warning以上级别的日志会输出
# 设置等级后
print('设置等级后')
# 日志配置
logging.basicConfig(level=logging.DEBUG, # 日志等级
filename='../files/Log/logger.log', # 日志路径及文件名
filemode='a', # a:追加 w:覆盖
format="%(asctime)s [%(filename)s 行:%(lineno)d] %(message)s \n" # 日志输出格式
) logging.debug('debug日志')
# logging.info('info日志')
# logging.warning('warning日志')
# logging.error('error日志')
# logging.critical('critical日志') # ====================logger对象=======================
# 1:创建对象
logger = logging.getLogger() # 2:创建文件Handler
fh = logging.FileHandler('../files/Log/logger.log')
# 3:创建屏幕输出Handler
ch = logging.StreamHandler() # 4:屏幕文件输出日志格式
fm = logging.Formatter("%(asctime)s [%(filename)s 行:%(lineno)d] %(message)s \n")
fh.setFormatter(fm)
ch.setFormatter(fm) # :5:将文件屏幕添加到logger对象中
logger.addHandler(fh)
logger.addHandler(ch) # 设置logger输出等级
logger.setLevel("DEBUG") # 使用logger打印信息
logging.info('info日志')
logging.warning('warning日志')
logging.error('error日志')
logging.critical('critical日志') def configparse_test():
print('\n==================configparse模块测试=====================\n') # 新增一个配置文件
config = configparser.ConfigParser()
# config['DEFAULT'] = {'ServerAliveInterval': '45', 'Compression': 'yes',
# 'CompressionLevel': '9',
# 'ForwardX11': 'yes'}
# config['bitbucket.org'] = {'User': 'ZhangSan'}
# config['topsecret.server.com'] = {'Port': 50022,
# 'ForwardX11': 'no'}
#
# with open('../files/config.init', 'w') as f:
# config.write(f) # 查
print(config.sections())
config.read('../files/config.init')
# DEFULT 不打印
config_sect = config.sections()
print(config_sect)
print('bytebong.com' in config)
print(config['bitbucket.org']['User'])
print('遍历节点新消息,无论是遍历哪个节点,DEFAULT的节点下的信息也会被遍历出来')
for key in config['topsecret.server.com']:
print(key) # 返回key列表
print(config.options('topsecret.server.com'))
# 返回 key value 列表
print(config.items('topsecret.server.com')) # 增
# config.add_section('address')
# config.set('address', 'UTC', '10212')
# config.add_section('INFO')
# config.set('INFO', 'Name', 'Lisi')
# config.set('INFO', 'Age', '18')
# config.set('INFO', 'Sex', '男') # 删
# config.remove_section('address')
# config.remove_option('INFO', 'Sex') # 改
config['INFO']['Name'] = '雷锋' # 重新写入文件
with open('../files/config.init', 'w') as cf:
config.write(cf) def hashib_test():
print('\n==================hashib模块测试=====================\n')
# has 算法 ----->摘要算法
md = hashlib.md5()
md.update('hello'.encode('utf8'))
print(md.hexdigest()) # 5d41402abc4b2a76b9719d911017c592 # 当前文件调用 modular.receMsage 模块下的 get_name方法,打印__name__值为:modular.receMsage
# 如果在receMsage.py 文件中执行,打印__name__值为:__main__
# 作用1:测试代码,外部引用调用的时候,就不会运行我的测试代码 2:
if __name__ == '__main__':
# get_name()
time_test()
random_test()
os_test()
sys_test()
json_test()
pickle_test()
shelve_test()
xml_test()
regex_test()
logging_test()
configparse_test()
hashib_test()
Python学习笔记【第八篇】:Python内置模块的更多相关文章
- Python 学习笔记(八)Python列表(二)
列表函数 追加和扩展 list.append() 在列表末尾追加新的对象 >>> dir(list) #dir 查看列表的函数 ['__add__', '__class__', '_ ...
- Python 学习笔记(八)Python列表(一)
列表基本操作 列表(list)定义 列表是Python中的一种对象类型,也是一种序列 对象类型:list 表示方法:[ ] python 列表中的元素可以是任何类型的对象 >>> ...
- python学习笔记(八)python操作Excel
一.python操作excel,python操作excel使用xlrd.xlwt和xlutils模块,xlrd模块是读取excel的,xlwt模块是写excel的,xlutils是用来修改excel的 ...
- Python 学习笔记(八)Python列表(三)
序列 序列:数学上,序列是被排成一列的对象(或事件):这样,每个元素不是在器他元素之前,就是在其他元素之后.这里元素之间的顺序非常重要.<维基百科> 序列是Python中最基本的数据结构. ...
- Python学习笔记(八)
Python学习笔记(八): 复习回顾 递归函数 内置函数 1. 复习回顾 1. 深浅拷贝 2. 集合 应用: 去重 关系操作:交集,并集,差集,对称差集 操作: 定义 s1 = set('alvin ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
- openresty 学习笔记番外篇:python的一些扩展库
openresty 学习笔记番外篇:python的一些扩展库 要写一个可以使用的python程序还需要比如日志输出,读取配置文件,作为守护进程运行等 读取配置文件 使用自带的ConfigParser模 ...
- openresty 学习笔记番外篇:python访问RabbitMQ消息队列
openresty 学习笔记番外篇:python访问RabbitMQ消息队列 python使用pika扩展库操作RabbitMQ的流程梳理. 客户端连接到消息队列服务器,打开一个channel. 客户 ...
- Python 学习笔记(基础篇)
背景:今年开始搞 Data science ,学了 python 小半年,但一直没时间整理整理.这篇文章很基础,就是根据廖雪峰的 python 教程 整理了一下基础知识,再加上自己的一些拓展,方便自己 ...
- Python学习笔记——基础语法篇
一.Python初识(IDE环境及基本语法,Spyder快捷方式) Python是一种解释型.面向对象.动态数据类型的高级程序设计语言,没有编译过程,可移植,可嵌入,可扩展. IDE 1.检查Pyth ...
随机推荐
- ubuntu 中 vim 的使用
安装 sudo apt install vim vim file_name #创建或者打开文件 vim file_name 定位到文件开头 vim file_name + 定位到文件末尾 vim f ...
- hbase-bloom filter
bloom fliter的作用主要用于提升hbase的读性能,但是会牺牲一定的存储空间. 原理: bloom fliter是一种空间效率很高的随机数据结构,初始状态时,bloom filter是一个包 ...
- HYSBZ 2743 (树状数组) 采花
题目:这里 题意: 在2016年,佳媛姐姐刚刚学习了树,非常开心.现在他想解决这样一个问题:给定一颗有根树(根为1),有以下 两种操作:1. 标记操作:对某个结点打上标记(在最开始,只有结点1有标记, ...
- Visual Studio连接Oracle数据库
一.安装Oracle Developer Tools for Visual Studio 2015 其他的什么client一概不要装,装了的直接卸载. 下载时需要登录,如果之前已经注册账号,提醒一下密 ...
- 服务管理之httpd
目录 1. httpd简介 2. httpd版本 2.2 httpd-2.4新增的模块 3. httpd基础 3.1 httpd自带的工具程序 3.2 rpm包安装的httpd程序环境 3.3 web ...
- mysql_事物
1) set autocommit=0 关闭自动提交 插入修改,只有commit 才最终存入 2) start transaction commit/rollback 3) show var ...
- JavaSE 初学系统托盘图标SystemTray类
文章目录 1.预备知识 2.使系统托盘显示图标 3.添加提示 4.添加弹出菜单 设置Java程序的系统托盘图标,用到SystemTray类和TrayIcon类. 1.预备知识 JavaAPI对于Sys ...
- c语言01次作业--分支,顺序结构
C语言--第01次作业 1.1思维导图 1.2本章学习体会及代码量学习体会 1.2.1学习体会 本章学习让我体会良多.首先,不得不承认自己是一个非常马虎的人.常见的问题就是输出格式上常因为没有与题目要 ...
- DWR使用总结
这两天学了下DWR,现在总结一下. DWR是方便使用AJAX连接JS和JAVA的的一个框架,把服务器端 Java 对象的方法公开给 JavaScript 代码. 如果是用dwr2.0的jar包,还 ...
- idea在debugger模式下无法启动,但是在run模式下可以启动的问题
debugger模式下,启动idea,总是报内存溢出异常, Error creating bean with name 'sysRoleUserMapper' defined in URL [jar: ...