python自动化开发-[第二十四天]-高性能相关与初识scrapy
今日内容概要
1、高性能相关
2、scrapy初识
上节回顾:
1. Http协议
Http协议:GET / http1.1/r/n...../r/r/r/na=1
TCP协议:sendall("GET / http1.1/r/n...../r/r/r/na=1") 2. 请求体
GET: GET / http1.1/r/n...../r/r/r/n
POST:
POST / http1.1/r/n...../r/r/r/na=1&b=2
POST / http1.1/r/n...../r/r/r/{"k1":123} PS: 依据Content-Type请求头 3. requests模块
- method
- url
- params
- data
- json
- headers
- cookies
- proxies
4. BeautifulSoup4模块
HTML
XML 5. Web微信
- 轮询
- 长轮询
上节回顾
一、关于web微信几点注意事项
1、关于防盗链机制
一般的网站都会用host,referer,cookies做防盗链,当遇到获取图片地址异常,可以尝试在headers里添加host或者referer或者加cookies
2、通过web微信可以 针对报警生成api进行免费的报警发送,也可以做一些智能回答
二、高性能相关的知识
在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢。
import requests def fetch_async(url):
response = requests.get(url)
return response url_list = ['http://www.github.com', 'http://www.bing.com'] for url in url_list:
fetch_async(url)
串行执行
import requests
from concurrent.futures import ThreadPoolExecutor def fetch_async(url):
print('请求开始')
response = requests.get(url)
print(response.text) url_list = ['http://www.baidu.com','http://www.bing.com'] pool = ThreadPoolExecutor(5)
for url in url_list:
pool.submit(fetch_async,url) pool.shutdown(wait=True)
多线程执行
import requests
from concurrent.futures import ThreadPoolExecutor def fetch_async(url):
print('请求开始')
response = requests.get(url)
return response def call_back(res):
print('开始执行回调')
print(res.result()) url_list = ['http://www.baidu.com','http://www.bing.com'] pool = ThreadPoolExecutor(5)
for url in url_list:
v = pool.submit(fetch_async,url)
v.add_done_callback(call_back) pool.shutdown(wait=True)
多线程+回调执行
from concurrent.futures import ProcessPoolExecutor
import requests def fetch_async(url):
response = requests.get(url)
return response url_list = ['http://www.github.com', 'http://www.bing.com']
pool = ProcessPoolExecutor(5)
for url in url_list:
pool.submit(fetch_async, url)
pool.shutdown(wait=True)
多进程执行
from concurrent.futures import ProcessPoolExecutor
import requests def fetch_async(url):
response = requests.get(url)
return response def callback(future):
print(future.result()) url_list = ['http://www.github.com', 'http://www.bing.com']
pool = ProcessPoolExecutor(5)
for url in url_list:
v = pool.submit(fetch_async, url)
v.add_done_callback(callback)
pool.shutdown(wait=True)
多进程+回调函数
通过上述代码均可以完成对请求性能的提高,对于多线程和多进行的缺点是在IO阻塞时会造成了线程和进程的浪费,所以异步IO回事首选:
异步IO解释: 异步代表回调,非阻塞并发
import asyncio @asyncio.coroutine
def func1():
print('before...func1....')
yield from asyncio.sleep(5)
print('end...func1...') tasks = [func1(),func1()] loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*tasks)) loop.close() '''
before...func1....
before...func1....
end...func1...
end...func1... '''
asyncio示例1
**socket_server和client之间通信存在4个阻塞的地方:
1、socket_server启动时候,链接循环是阻塞的
2、socket_server的通信循环 send后recv是阻塞的
3、client启动的时候connect_server是阻塞的
4、client send消息后 recv是阻塞的
import asyncio @asyncio.coroutine
def fetch_async(host, url='/'):
print(host, url)
reader, writer = yield from asyncio.open_connection(host, 80) request_header_content = """GET %s HTTP/1.0\r\nHost: %s\r\n\r\n""" % (url, host,)
request_header_content = bytes(request_header_content, encoding='utf-8') writer.write(request_header_content)
yield from writer.drain()
text = yield from reader.read()
print(host, url, text)
writer.close() tasks = [
fetch_async('www.cnblogs.com', '/wupeiqi/'),
fetch_async('dig.chouti.com', '/pic/show?nid=4073644713430508&lid=10273091')
] loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
asyncio示例2
import aiohttp
import asyncio @asyncio.coroutine
def fetch_async(url):
print(url)
response = yield from aiohttp.request('GET', url)
# data = yield from response.read()
# print(url, data)
print(url, response)
response.close() tasks = [fetch_async('http://www.google.com/'), fetch_async('http://www.chouti.com/')] event_loop = asyncio.get_event_loop()
results = event_loop.run_until_complete(asyncio.gather(*tasks))
event_loop.close()
asyncio+aiohttp
import asyncio
import requests @asyncio.coroutine
def fetch_async(func, *args):
loop = asyncio.get_event_loop()
future = loop.run_in_executor(None, func, *args)
response = yield from future
print(response.url, response.content) tasks = [
fetch_async(requests.get, 'http://www.cnblogs.com/wupeiqi/'),
fetch_async(requests.get, 'http://dig.chouti.com/pic/show?nid=4073644713430508&lid=10273091')
] loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
asyncio + requests
import gevent import requests
from gevent import monkey monkey.patch_all() def fetch_async(method, url, req_kwargs):
print(method, url, req_kwargs)
response = requests.request(method=method, url=url, **req_kwargs)
print(response.url, response.content) # ##### 发送请求 #####
gevent.joinall([
gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}),
gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}),
]) # ##### 发送请求(协程池控制最大协程数量) #####
# from gevent.pool import Pool
# pool = Pool(None)
# gevent.joinall([
# pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
# pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}),
# pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}),
# ])
gevent+requests
import grequests request_list = [
grequests.get('http://httpbin.org/delay/1', timeout=0.001),
grequests.get('http://fakedomain/'),
grequests.get('http://httpbin.org/status/500')
] # ##### 执行并获取响应列表 #####
# response_list = grequests.map(request_list)
# print(response_list) # ##### 执行并获取响应列表(处理异常) #####
# def exception_handler(request, exception):
# print(request,exception)
# print("Request failed") # response_list = grequests.map(request_list, exception_handler=exception_handler)
# print(response_list)
grequests
from twisted.web.client import getPage, defer
from twisted.internet import reactor def all_done(arg):
reactor.stop() #终止死循环 def callback(contents):
print(contents) deferred_list = [] url_list = ['http://www.bing.com', 'http://www.baidu.com', ]
for url in url_list:
deferred = getPage(bytes(url, encoding='utf8'))
deferred.addCallback(callback)
deferred_list.append(deferred) dlist = defer.DeferredList(deferred_list)
dlist.addBoth(all_done) reactor.run() #相当于一个死循环一直监听线程的执行状态
Twisted示例
from tornado.httpclient import AsyncHTTPClient
from tornado.httpclient import HTTPRequest
from tornado import ioloop def handle_response(response):
"""
处理返回值内容(需要维护计数器,来停止IO循环),调用 ioloop.IOLoop.current().stop()
:param response:
:return:
"""
if response.error:
print("Error:", response.error)
else:
print(response.body) def func():
url_list = [
'http://www.baidu.com',
'http://www.bing.com',
]
for url in url_list:
print(url)
http_client = AsyncHTTPClient()
http_client.fetch(HTTPRequest(url), handle_response) ioloop.IOLoop.current().add_callback(func)
ioloop.IOLoop.current().start()
Tornado
from twisted.internet import reactor
from twisted.web.client import getPage
import urllib.parse def one_done(arg):
print(arg)
reactor.stop() post_data = urllib.parse.urlencode({'check_data': 'adf'})
post_data = bytes(post_data, encoding='utf8')
headers = {b'Content-Type': b'application/x-www-form-urlencoded'}
response = getPage(bytes('http://dig.chouti.com/login', encoding='utf8'),
method=bytes('POST', encoding='utf8'),
postdata=post_data,
cookies={},
headers=headers)
response.addBoth(one_done) reactor.run()
Twisted更多
以上均是Python内置以及第三方模块提供异步IO请求模块,使用简便大大提高效率,而对于异步IO请求的本质则是【非阻塞Socket】+【IO多路复用】:
import select
import socket
import time class AsyncTimeoutException(TimeoutError):
"""
请求超时异常类
""" def __init__(self, msg):
self.msg = msg
super(AsyncTimeoutException, self).__init__(msg) class HttpContext(object):
"""封装请求和相应的基本数据""" def __init__(self, sock, host, port, method, url, data, callback, timeout=5):
"""
sock: 请求的客户端socket对象
host: 请求的主机名
port: 请求的端口
port: 请求的端口
method: 请求方式
url: 请求的URL
data: 请求时请求体中的数据
callback: 请求完成后的回调函数
timeout: 请求的超时时间
"""
self.sock = sock
self.callback = callback
self.host = host
self.port = port
self.method = method
self.url = url
self.data = data self.timeout = timeout self.__start_time = time.time()
self.__buffer = [] def is_timeout(self):
"""当前请求是否已经超时"""
current_time = time.time()
if (self.__start_time + self.timeout) < current_time:
return True def fileno(self):
"""请求sockect对象的文件描述符,用于select监听"""
return self.sock.fileno() def write(self, data):
"""在buffer中写入响应内容"""
self.__buffer.append(data) def finish(self, exc=None):
"""在buffer中写入响应内容完成,执行请求的回调函数"""
if not exc:
response = b''.join(self.__buffer)
self.callback(self, response, exc)
else:
self.callback(self, None, exc) def send_request_data(self):
content = """%s %s HTTP/1.0\r\nHost: %s\r\n\r\n%s""" % (
self.method.upper(), self.url, self.host, self.data,) return content.encode(encoding='utf8') class AsyncRequest(object):
def __init__(self):
self.fds = []
self.connections = [] def add_request(self, host, port, method, url, data, callback, timeout):
"""创建一个要请求"""
client = socket.socket()
client.setblocking(False)
try:
client.connect((host, port))
except BlockingIOError as e:
pass
# print('已经向远程发送连接的请求')
req = HttpContext(client, host, port, method, url, data, callback, timeout)
self.connections.append(req)
self.fds.append(req) def check_conn_timeout(self):
"""检查所有的请求,是否有已经连接超时,如果有则终止"""
timeout_list = []
for context in self.connections:
if context.is_timeout():
timeout_list.append(context)
for context in timeout_list:
context.finish(AsyncTimeoutException('请求超时'))
self.fds.remove(context)
self.connections.remove(context) def running(self):
"""事件循环,用于检测请求的socket是否已经就绪,从而执行相关操作"""
while True:
r, w, e = select.select(self.fds, self.connections, self.fds, 0.05) if not self.fds:
return for context in r:
sock = context.sock
while True:
try:
data = sock.recv(8096)
if not data:
self.fds.remove(context)
context.finish()
break
else:
context.write(data)
except BlockingIOError as e:
break
except TimeoutError as e:
self.fds.remove(context)
self.connections.remove(context)
context.finish(e)
break for context in w:
# 已经连接成功远程服务器,开始向远程发送请求数据
if context in self.fds:
data = context.send_request_data()
context.sock.sendall(data)
self.connections.remove(context) self.check_conn_timeout() if __name__ == '__main__':
def callback_func(context, response, ex):
"""
:param context: HttpContext对象,内部封装了请求相关信息
:param response: 请求响应内容
:param ex: 是否出现异常(如果有异常则值为异常对象;否则值为None)
:return:
"""
print(context, response, ex) obj = AsyncRequest()
url_list = [
{'host': 'www.google.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
{'host': 'www.baidu.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
{'host': 'www.bing.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
]
for item in url_list:
print(item)
obj.add_request(**item) obj.running()
异步io模块
IO多路复用:select,用于检测socket对象是否发生变化(是否连接成功,是否有数据到来)
封装模块:
import socket
import select class Request(object):
def __init__(self,sock,func,url):
self.sock = sock
self.func = func
self.url = url def fileno(self):
return self.sock.fileno() #获取socket对象文件描述符 def async_request(url_list): input_list = []
conn_list = [] for url in url_list:
client = socket.socket()
client.setblocking(False)
# 创建连接,不阻塞
try:
client.connect((url[0],80,)) # 100个向百度发送的请求
except BlockingIOError as e:
pass obj = Request(client,url[1],url[0]) input_list.append(obj)
conn_list.append(obj) while True:
# 监听socket是否已经发生变化 [request_obj,request_obj....request_obj]
# 如果有请求连接成功:wlist = [request_obj,request_obj]
# 如果有响应的数据: rlist = [request_obj,request_obj....client100]
rlist,wlist,elist = select.select(input_list,conn_list,[],0.05)
for request_obj in wlist:
# print('连接成功')
# # # # 发送Http请求
# print('发送请求')
request_obj.sock.sendall("GET / HTTP/1.0\r\nhost:{0}\r\n\r\n".format(request_obj.url).encode('utf-8'))
conn_list.remove(request_obj) for request_obj in rlist:
data = request_obj.sock.recv(8096)
request_obj.func(data)
request_obj.sock.close()
input_list.remove(request_obj) if not input_list:
break
调用:
def callback1(data):
print('百度回来了',data) def callback2(data):
print('必应回来了',data) url_list = [
['www.baidu.com',callback1],
['www.bing.com',callback2]
]
s2.async_request(url_list)
经典回答录:
使用一个线程完成并发操作,如何并发?
当第一个任务到来时,先发送连接请求,此时会发生IO等待,但是我不等待,我继续发送第二个任务的连接请求.... IO多路复用监听socket变化
先连接成功:
发送请求信息: GET / http/1.0\r\nhost....
遇到IO等待,不等待,继续检测是否有人连接成功:
发送请求信息: GET / http/1.0\r\nhost....
遇到IO等待,不等待,继续检测是否有人连接成功:
发送请求信息: GET / http/1.0\r\nhost.... 有结果返回:
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数 问题:什么是协程?
单纯的执行一端代码后,调到另外一端代码执行,再继续跳... 异步IO:
- 【基于协程】可以用 协程+非阻塞socket+select实现,gevent
- 【基于事件循环】完全通用socket+select实现,Twsited 1. 如何提高爬虫并发?
利用异步IO模块,如:asyncio,twisted,gevent
本质:
- 【基于协程】可以用 协程+非阻塞socket+select实现,gevent
- 【基于事件循环】完全通用socket+select实现,Twsited,tornado 2. 异步非阻塞
异步:回调 select
非阻塞:不等待 setblocking(False) 3. 什么是协程?
携程是人工去定义如何切换,遇到io阻塞就切换
pip3 install gevent from greenlet import greenlet def test1():
print(12)
gr2.switch()
print(34)
gr2.switch() def test2():
print(56)
gr1.switch()
print(78) gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
三、Scrapy使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
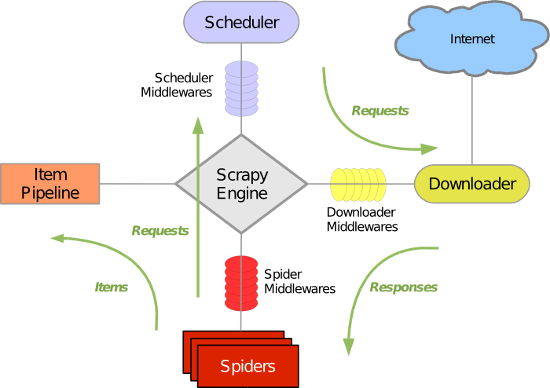
执行流程:
启动scrapy通过scrapy_engine将任务放入scheduler里(队列),执行requests进行下载页面,将返回值传给spiders(这个可以有多个),spider处理可以通过items和pipeline进行数据持久化,也可以进行递归回调 再次将新任务投放到scheduler里
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装:
Linux
pip3 install scrapy Windows
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install scrapy
e. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
f. pip3 install pypiwin32 #如果找不到python_dir就用pip3安装
二、基本命令:
1. scrapy startproject 项目名称
- 在当前目录中创建中创建一个项目文件(类似于Django) 2. scrapy genspider [-t template] <name> <domain>
- 创建爬虫应用
如:
scrapy gensipider -t basic oldboy oldboy.com
scrapy gensipider -t xmlfeed autohome autohome.com.cn
PS:
查看所有命令:scrapy gensipider -l
查看模板命令:scrapy gensipider -d 模板名称 3. scrapy list
- 展示爬虫应用列表 4. scrapy crawl 爬虫应用名称
- 运行单独爬虫应用 5.不输出调试日志 scrapy crawl quotes --nolog 6.终端调试
scrapy shell quotes.toscrape.com 7.生成一个json文件 scrapy crawl quotes -o quotes.json 8.利用download下载源代码 并通过浏览器显示
scrapy view http://www.chuchujie.com 9.格式化输出
#最后的parse是方法 scrapy parse http://quotes.toscrape.com -c parse 10.run方法执行文件
scrapy runspider spiders/quotes.py
三、项目结构以及爬虫应用简介
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
文件说明:
- scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
windows如果出现编码问题:
import sys,os
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
例子:
爬取抽屉新闻内容:
# -*- coding: utf-8 -*-
import scrapy
import io,os,sys sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
from scrapy.selector import HtmlXPathSelector
from ..items import Sp1Item
from scrapy.http import Request class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
# start_urls = ['http://dig.chouti.com/',] def start_requests(self):
yield Request(url="http://dig.chouti.com/",headers={},callback=self.parse) def parse(self, response):
# print(response.body)
# print(response.text)
hxs = HtmlXPathSelector(response)
# result = hxs.select('//div[@id="yellow-msg-box-intohot"]')
item_list = hxs.select('//div[@id="content-list"]/div[@class="item"]')
for item in item_list:
# item.select('./div[@class="news-content"]/div[@class="part2"]/text()').extract()
# item.select('./div[@class="news-content"]/div[@class="part2"]/text()').extract_first()
title = item.select('./div[@class="news-content"]/div[@class="part2"]/@share-title').extract_first()
url = item.select('./div[@class="news-content"]/div[@class="part2"]/@share-pic').extract_first()
# v = item.select('./div[@class="news-content"]/div[@class="part2"]/@share-title').extract_first()
obj = Sp1Item(title=title,url=url)
yield obj # 找到所有页码标签
# hxs.select('//div[@id="dig_lcpage"]//a/@href').extract()
page_url_list = hxs.select('//div[@id="dig_lcpage"]//a[re:test(@href,"/all/hot/recent/\d+")]/@href').extract()
for url in page_url_list:
url = "http://dig.chouti.com" + url
obj = Request(url=url,callback=self.parse,headers={},cookies={})
yield obj
chouti.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Sp1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
items.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class Sp1Pipeline(object):
def __init__(self,file_path):
self.file_path = file_path self.file_obj = None @classmethod
def from_crawler(cls, crawler):
"""
初始化时候,用于创建pipeline对象
:param crawler:
:return:
"""
val = crawler.settings.get('XXXXXXX')
return cls(val) def process_item(self, item, spider):
if spider.name == 'chouti':
self.file_obj.write(item['url'])
# print('pipeline-->',item)
return item def open_spider(self,spider):
"""
爬虫开始执行时,只执行一次
:param spider:
:return:
"""
self.file_obj = open(self.file_path,mode='a+') def close_spider(self,spider):
"""
爬虫关闭时,只执行一次
:param spider:
:return:
"""
self.file_obj.close()
pipelines.py
四、选择器
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.selector import Selector, HtmlXPathSelector
from scrapy.http import HtmlResponse
html = """<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<ul>
<li class="item-"><a id='i1' href="link.html">first item</a></li>
<li class="item-0"><a id='i2' href="llink.html">first item</a></li>
<li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li>
</ul>
<div><a href="llink2.html">second item</a></div>
</body>
</html>
"""
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
# hxs = HtmlXPathSelector(response)
# print(hxs)
# hxs = Selector(response=response).xpath('//a')
# print(hxs)
# hxs = Selector(response=response).xpath('//a[2]') 获取第二个标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id]') 含id的a标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@id="i1"]') id=i1的a标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') href=link.html id=i1的a标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[contains(@href, "link")]') href包含link的a标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]') href属性以link开头的a标签
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]') 正则匹配id为i数字
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract() 取a标签的文本
# print(hxs)
# hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract() 取a标签的属性值
# print(hxs)
# hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
# print(hxs)
# hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
# print(hxs) # ul_list = Selector(response=response).xpath('//body/ul/li')
# for item in ul_list:
# v = item.xpath('./a/span')
# # 或
# # v = item.xpath('a/span')
# # 或
# # v = item.xpath('*/a/span')
# print(v)
注意:settings.py中设置DEPTH_LIMIT = 1来指定“递归”的层数。
python自动化开发-[第二十四天]-高性能相关与初识scrapy的更多相关文章
- python自动化开发-[第二十五天]-scrapy进阶与flask使用
今日内容概要 1.cookie操作 2.pipeline 3.中间件 4.扩展 5.自定义命令 6.scrapy-redis 7.flask使用 - 路由系统 - 视图 - 模版 - message( ...
- python自动化开发-[第十四天]-javascript(续)
今日概要: 1.数据类型 2.函数function 3.BOM 4.DOM 1.运算符 算术运算符: + - * / % ++ -- 比较运算符: > >= < <= != = ...
- python自动化开发-[第十天]-线程、协程、socketserver
今日概要 1.线程 2.协程 3.socketserver 4.基于udp的socket(见第八节) 一.线程 1.threading模块 第一种方法:实例化 import threading imp ...
- python自动化开发-[第二天]-基础数据类型与编码(续)
今日简介: - 编码 - 进制转换 - 初识对象 - 基本的数据类型 - 整数 - 布尔值 - 字符串 - 列表 - 元祖 - 字典 - 集合 - range/enumcate 一.编码 encode ...
- Android UI开发第二十四篇——Action Bar
Action bar是一个标识应用程序和用户位置的窗口功能,并且给用户提供操作和导航模式.在大多数的情况下,当你需要突出展现用户行为或全局导航的activity中使用action bar,因为acti ...
- 【转】Android UI开发第二十四篇——Action Bar
Action bar是一个标识应用程序和用户位置的窗口功能,并且给用户提供操作和导航模式.在大多数的情况下,当你需要突出展现用户行为或全局导航的activity中使用action bar,因为acti ...
- Appium+python自动化(二十四)- 白素贞千年等一回许仙 - 元素等待(超详解)
简介 许仙小时候最喜欢吃又甜又软的汤圆了,一次一颗汤圆落入西湖,被一条小白蛇衔走了.十几年后,一位身着白衣.有青衣丫鬟相伴的美丽女子与许仙相识了,她叫白娘子.白娘子聪明又善良,两个人很快走到了一起.靠 ...
- python自动化开发-[第二十三天]-初识爬虫
今日概要: 1.爬汽车之家的新闻资讯 2.爬github和chouti 3.requests和beautifulsoup 4.轮询和长轮询 5.django request.POST和request. ...
- python自动化开发-[第十六天]-bootstrap和django
今日概要: 1.bootstrap使用 2.栅格系统 3.orm简介 4.路由系统 5.mvc和mtv模式 6.django框架 1.bootstrap的引用方式 1.Bootstrap 专门构建了免 ...
随机推荐
- 【C/C++】求解线性方程组的雅克比迭代与高斯赛德尔迭代
雅克比迭代: /* 方程组求解的迭代法: 雅克比迭代 */ #include<bits/stdc++.h> using namespace std; ][]; ]; void swapA( ...
- python模块psutil的使用
介绍 psutil是一个跨平台库(http://code.google.com/p/psutil/),能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等)信息.它主要应用于系统 ...
- zabbix批量操作
利用zabbix-api来实现zabbix的主机的批量添加,主机的查找,删除等等操作. 代码如下: #!/usr/bin/env python #-*- coding: utf- -*- import ...
- Codeforces Round #429 Div. 1
A:甚至连题面都不用仔细看,看一下样例就知道是要把大的和小的配对了. #include<iostream> #include<cstdio> #include<cmath ...
- Python内建GUI模块Tkinter(一)
Python主窗口 Python特定的GUI界面,是一个图像的窗口,tkinter是python自带的,可以编辑的GUI界面,我们可以用GUI实现很多一个直观的功能,如何想开发一个计算器,如果只是一个 ...
- Git神器使用相关
感谢 感谢作者的网站,本文所有的知识可以在上述网站了解到,讲的非常详细,感谢.(https://www.liaoxuefeng.com/wiki/0013739516305929606dd183612 ...
- 解决sublime text3 中文字符乱码
前言 由于系统编码问题导致的中文乱码解决,linux和windows解决方式都一样. 流程 linux下两步都需要,windows下只需要第二步. 1.在package install中搜索安装:co ...
- Collect devices information
Collect devices information root@vpx-test# kenv > kenv.txt root@vpx-test# sysctl -a > sysctl_a ...
- 微信小程序Dom事件实现
面对微信小程序,可能没有像我们平时使用JQuery那样随心所欲.本篇就是为了解决这个问题. 请合理使用工具! 细节就不说了,直接备份一个实现的案例: wxml <view class=" ...
- 【BZOJ4868】[六省联考2017]期末考试(贪心)
[BZOJ4868][六省联考2017]期末考试(贪心) 题面 BZOJ 洛谷 题解 显然最终的答案之和最后一个公布成绩的课程相关. 枚举最后一天的日期,那么维护一下前面有多少天可以向后移,后面总共需 ...