爬虫基础02-day24
写在前面
干就完了
s16/17爬虫2 内容回顾:
1. Http协议
Http协议:GET / http1.1/r/n...../r/r/r/na=1
TCP协议:sendall("GET / http1.1/r/n...../r/r/r/na=1") 2. 请求体
GET: GET / http1.1/r/n...../r/r/r/n
POST:
POST / http1.1/r/n...../r/r/r/na=1&b=2
POST / http1.1/r/n...../r/r/r/{"k1":123} PS: 依据Content-Type请求头 3. requests模块
- method
- url
- params
- data
- json
- headers
- cookies
- proxies
4. BeautifulSoup4模块
HTML
XML 5. Web微信
- 轮训
- 长轮训 今日内容概要:
1. Web微信 2. 高性能相关 3. Scrapy 内容详细:
1. Web微信 - 防盗链
- headers
- cookies - 检测请求
- url - Session中:
- qcode
- ctime
- login_cookie_dict
- ticket_dict_cookie
- ticket_dict
- init_cookie_dict - 收发消息 2. 高性能相关 基本原理:
IO多路复用:select,用于检测socket对象是否发生变化(是否连接成功,是否有数据到来)
Socket:socket客户端 import socket
import select class Request(object):
def __init__(self,sock,func,url):
self.sock = sock
self.func = func
self.url = url def fileno(self):
return self.sock.fileno() def async_request(url_list): input_list = []
conn_list = [] for url in url_list:
client = socket.socket()
client.setblocking(False)
# 创建连接,不阻塞
try:
client.connect((url[0],80,)) # 100个向百度发送的请求
except BlockingIOError as e:
pass obj = Request(client,url[1],url[0]) input_list.append(obj)
conn_list.append(obj) while True:
# 监听socket是否已经发生变化 [request_obj,request_obj....request_obj]
# 如果有请求连接成功:wlist = [request_obj,request_obj]
# 如果有响应的数据: rlist = [request_obj,request_obj....client100]
rlist,wlist,elist = select.select(input_list,conn_list,[],0.05)
for request_obj in wlist:
# print('连接成功')
# # # # 发送Http请求
# print('发送请求')
request_obj.sock.sendall("GET / HTTP/1.0\r\nhost:{0}\r\n\r\n".format(request_obj.url).encode('utf-8'))
conn_list.remove(request_obj) for request_obj in rlist:
data = request_obj.sock.recv(8096)
request_obj.func(data)
request_obj.sock.close()
input_list.remove(request_obj) if not input_list:
break 使用一个线程完成并发操作,如何并发?
当第一个任务到来时,先发送连接请求,此时会发生IO等待,但是我不等待,我继续发送第二个任务的连接请求.... IO多路复用监听socket变化
先连接成功:
发送请求信息: GET / http/1.0\r\nhost....
遇到IO等待,不等待,继续检测是否有人连接成功:
发送请求信息: GET / http/1.0\r\nhost....
遇到IO等待,不等待,继续检测是否有人连接成功:
发送请求信息: GET / http/1.0\r\nhost.... 有结果返回:
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数
读取返回内容,执行回调函数 问题:什么是协程?
单纯的执行一端代码后,调到另外一端代码执行,再继续跳... 异步IO:
- 【基于协程】可以用 协程+非阻塞socket+select实现,gevent
- 【基于事件循环】完全通用socket+select实现,Twsited 1. 如何提高爬虫并发?
利用异步IO模块,如:asyncio,twisted,gevent
本质:
- 【基于协程】可以用 协程+非阻塞socket+select实现,gevent
- 【基于事件循环】完全通用socket+select实现,Twsited,tornado 2. 异步非阻塞
异步:回调 select
非阻塞:不等待 setblocking(False) 3. 什么是协程?
pip3 install gevent from greenlet import greenlet def test1():
print(12)
gr2.switch()
print(34)
gr2.switch() def test2():
print(56)
gr1.switch()
print(78) gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch() 3. 爬虫
- request+bs4+twisted或gevent或asyncio
- scrapy框架
- twisted
- 自己html解析
- 限速
- 去重
- 递归,找4层
- 代理
- https
- 中间件
....
- 安装scrapy
依赖Twisted - 开始写爬虫
执行命令:
scrapy startproject sp1 sp1
- sp1
- spiders 爬虫
- xx.py
- chouti.py
- middlewares 中间件
- pipelines 持久化
- items 规则化
- settings 配置
- scrapy.cfg cd sp1
scrapy genspider xx xx.com
scrapy genspider chouti chouti.com - scrapy crawl chouti
name
allow_domains
start_urls parse(self,response) yield Item yield Request(url,callback) 本周任务:
1. Web微信 2. 高性能示例保存 3.
- 煎蛋
- 拉钩
- 知乎
- 抽屉
武Sir - 笔记
before Web微信 高性能 scrapy requests.post(data=xxx) -> Form Data requests.post(json=xxx) -> Request Payload HttpResponse() 参数可以是字符串也可以是字节 response.text 字符串
response.content 字节 # 获取最近联系人然后进行初始化 # 获取头像 # 拿联系人列表
response = requests.get(url,cookies=xxx)
response.encoding = 'utf-8'
print(json.loads(response.text)) Web微信总结
- 头像防盗链
- headers
- cookies - 检测请求:
- tip | pass_ticket | ...
- redirect_url和真实请求的url是否一致 - session 保存关键点的cookies和关键变量值
- qrcode 和 ctime
- login_cookie_dict
- ticket_dict_cookie
- ticket_dict
- init_cookie_dict
- init_dict - all_cookies = {}
- all_cookies.update(...) json序列化的时候是可以加参数的: data = {
'name':'alex',
'msg':'中文asa'
}
import json
print(json.dumps(data))
按Unicode显示 print(json.dumps(data,ensure_ascii=False))
按中文显示 json.dumps() 之后是字符串
requests.post() 默认是按照 latin-1 编码,不支持中文 所以改成直接发bytes:
requests.post(data=json.dumps(data,ensure_ascii=False).encode('utf-8')) 发送消息需带上cookies 发送消息 检测是否有新消息到来
接收消息 ######################### 高性能相关 100张图片,下载 使用一个线程完成并发操作
是配合IO多路复用完成的 爬虫:
- 简单的爬虫
- requests+bs4+twsited+asyncio
- scrapy框架
- 下载页面:twsited
- 解析页面:自己的HTML解析
- 可限速
- 去重
- 递归 一层一层的爬,成倍速的增长,还可以限制层数
- 代理
- https
- 中间件
... scrapy
- scrapy startproject sp1
- cd sp1
- scrapy genspider baidu baidu.com
- scrapy genspider chouti chouti.com
- scrapy crawl chouti --nolog - name
- allow_dimains
- start_urls
- parse(self,response)
- yield Item 持久化
- yield Request(url,callback) 把url放到调度器队列里 本周作业:
1.Web微信
自己去写,写完跟老师的对比 2.高性能总结文档(源码示例+文字理解) 3.任意找一个网站,用Scrapy去爬
- 煎蛋
- 拉钩
- 知乎
- 抽屉
- ... 不遵循爬虫规范:
ROBOTSTXT_OBEY = False 可能会失败:没有带请求头 起始url如何携带指定请求头?
自定义start_requests(self)
一、Web微信
获取最近联系人列表并初始化:
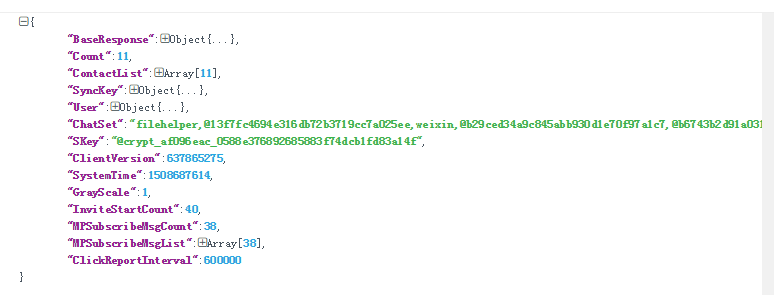
获取联系人列表:
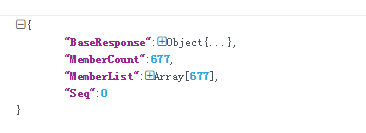
代码实现见另一片博客:Web微信
二、高性能编程示例
参考:http://www.cnblogs.com/wupeiqi/articles/6229292.html
代码示例见另一篇那博客:Python高性能编程
三、Scrapy框架初探
参考:http://www.cnblogs.com/wupeiqi/articles/5354900.html
代码示例参见博客:Scrapy基础01 Scrapy基础02
爬虫基础02-day24的更多相关文章
- 【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
[网络爬虫入门02]HTTP客户端库Requests的基本原理与基础应用 广东职业技术学院 欧浩源 1.引言 实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求.urllib是 ...
- javascript基础02
javascript基础02 1.数据类型 数据类型的描述在上篇的扩展中有写到链接 由于ECMAScript数据类型具有动态性,因此的确没有再定义其他数据类型的必要.这句话很重要. 如果以后再数据类型 ...
- javaSE基础02
javaSE基础02 一.javac命令和java命令做什么事情? javac:负责编译,当执行javac时,会启动java的编译程序,对指定扩展名的.java文件进行编译,生成了jvm可以识别的字节 ...
- java基础学习05(面向对象基础02)
面向对象基础02 实现的目标 1.String类的使用2.掌握this关键字的使用3.掌握static关键字的使用4.了解内部类 String类 实例化String对象一个字符串就是一个String类 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- java网络爬虫基础学习(三)
尝试直接请求URL获取资源 豆瓣电影 https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort= ...
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
随机推荐
- 【arc073f】Many Moves(动态规划,线段树)
[arc073f]Many Moves(动态规划,线段树) 题面 atcoder 洛谷 题解 设\(f[i][j]\)表示第一个棋子在\(i\),第二个棋子在\(j\)的最小移动代价. 发现在一次移动 ...
- 文艺平衡Splay树学习笔记(2)
本blog会讲一些简单的Splay的应用,包括但不局限于 1. Splay 维护数组下标,支持区间reserve操作,解决区间问题 2. Splay 的启发式合并(按元素多少合并) 3. 线段树+Sp ...
- A/D和D/A的学习
从我们学到的知识了解到,我们的单片机是一个典型的数字系统.数字系统只能对输入的数字信号进行处理,其输出信号也是数字信号.但是在工业检测系统和日常生活中的许多物理量都是模拟量,比如温度.长度.压力.速度 ...
- Manthan, Codefest 18 (rated, Div. 1 + Div. 2) C D
C - Equalize #include<bits/stdc++.h> using namespace std; using namespace std; string a,b; int ...
- 前端JS Excel导出
本文转载自:https://blog.csdn.net/plmzaqokn11/article/details/73604705 下载table2Excel插件 <input type=&quo ...
- 【CF1141F2】Same Sum Blocks
题解:发现可以通过枚举区间将区间和相同的元组记录在一个表中,对于答案来说,在同一个表中的元组的选择才会对答案产生贡献.发现每一个表中都是一个个区间,问题转化成了对于每一个表来说,选择若干个不相交的区间 ...
- [luogu3294][背单词]
题目链接 题意 读完题目就一个感受:这出题人tm不会说人话吗.真的感觉这个题理解题意比想出正解更难. 其实题目的意思就是,给出一些单词,给这些单词编个号,然后要求其他的单词中是这个单词后缀的词都在这个 ...
- Java 多线程篇
先举个例子 计算机的核心是CPU,它承担了计算机所有计算任务,可以把它理解为像一个工厂,时刻在运行. 假定工厂有一个电力系统,工厂有很多车间,一次只能供给一个车间使用,也就是说一个车间开工的时候,其他 ...
- post请求中data参数的应用
一.data为参数,json是自动的把参数转换成了json格式,一般建议用json ,url是请求地址. 二,以一个网站来做解释,看登陆的请求 抓包看一下: 用在代码里面看一下: 如果不转的话,那么用 ...
- 手机nv
NV值是记录手机的射频参数的,和手机的IMEI号.手机信号.WIFI信号等有关,如果NV值刷没了,手机没有这些校准的数据了,会对手机有一定的影响. qcn里面包含手机的imei 所有改变imei就改变 ...