理解Spark SQL(一)—— CLI和ThriftServer
Spark SQL主要提供了两个工具来访问hive中的数据,即CLI和ThriftServer。前提是需要Spark支持Hive,即编译Spark时需要带上hive和hive-thriftserver选项,同时需要确保在$SPARK_HOME/conf目录下有hive-site.xml配置文件(可以从hive中拷贝过来)。在该配置文件中主要是配置hive metastore的URI(Spark的CLI和ThriftServer都需要)以及ThriftServer相关配置项(如hive.server2.thrift.bind.host、hive.server2.thrift.port等)。注意如果该台机器上同时运行有Hive ThriftServer和Spark ThriftServer,则hive中的hive.server2.thrift.port配置的端口与spark中的hive.server2.thrift.port配置的端口要不一样,避免同时启动时发生端口冲突。
启动CLI和ThriftServer之前都需要先启动hive metastore。执行如下命令启动:
[root@BruceCentOS ~]# nohup hive --service metastore &
成功启动后,会出现一个RunJar的进程,同时会监听端口9083(hive metastore的默认端口)。


先来看CLI,通过spark-sql脚本来使用CLI。执行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-sql --master yarn
上述命令执行后会启动一个yarn client模式的Spark程序,如下图所示:

同时它会连接到hive metastore,可以在随后出现的spark-sql>提示符下运行hive sql语句,比如:

其中每输入并执行一个SQL语句相当于执行了一个Spark的Job,如图所示:

也就是说执行spark-sql脚本会启动一个yarn clien模式的Spark Application,而后出现spark-sql>提示符,在提示符下的每个SQL语句都会在Spark中执行一个Job,但是对应的都是同一个Application。这个Application会一直运行,可以持续输入SQL语句执行Job,直到输入“quit;”,然后就会退出spark-sql,即Spark Application执行完毕。
另外一种更好地使用Spark SQL的方法是通过ThriftServer,首先需要启动Spark的ThriftServer,然后通过Spark下的beeline或者自行编写程序通过JDBC方式使用Spark SQL。
通过如下命令启动Spark ThriftServer:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/start-thriftserver.sh --master yarn
执行上面的命令后,会生成一个SparkSubmit进程,实际上是启动一个yarn client模式的Spark Application,如下图所示:

而且它提供一个JDBC/ODBC接口,用户可以通过JDBC/ODBC接口连接ThriftServer来访问Spark SQL的数据。具体可以通过Spark提供的beeline或者在程序中使用JDBC连接ThriftServer。例如在启动Spark ThriftServer后,可以通过如下命令使用beeline来访问Spark SQL的数据。
[root@BruceCentOS3 spark]# $SPARK_HOME/bin/beeline -n root -u jdbc:hive2://BruceCentOS4.Hadoop:10003
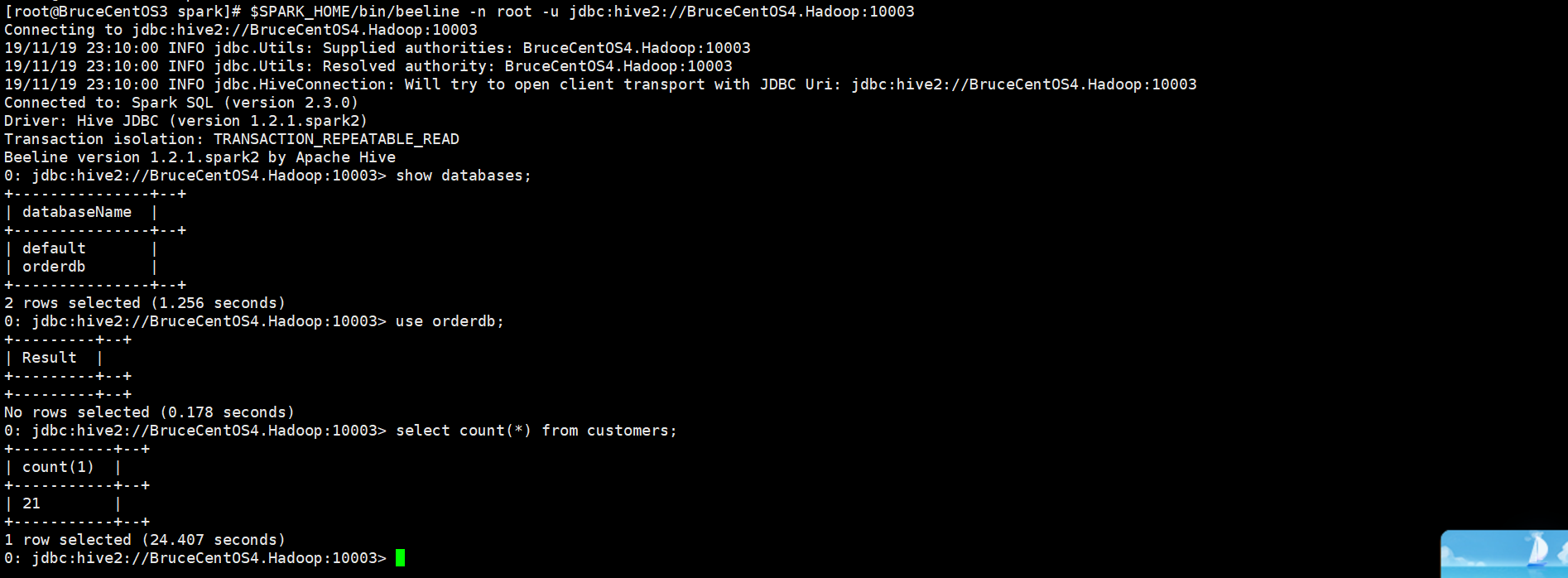
上述beeline连接到了BruceCentOS4上的10003端口,也就是Spark ThriftServer。所有连接到ThriftServer的客户端beeline或者JDBC程序共享同一个Spark Application,通过beeline或者JDBC程序执行SQL相当于向这个Application提交并执行一个Job。在提示符下输入“!exit”命令可以退出beeline。
最后,如果要停止ThriftServer(即停止Spark Application),需要执行如下命令:
[root@BruceCentOS4 spark]# $SPARK_HOME/sbin/stop-thriftserver.sh

综上所述,在Spark SQL的CLI和ThriftServer中,比较推荐使用后者,因为后者更加轻量,只需要启动一个ThriftServer(对应一个Spark Application)就可以给多个beeline客户端或者JDBC程序客户端使用SQL,而前者启动一个CLI就启动了一个Spark Application,它只能给一个用户使用。
理解Spark SQL(一)—— CLI和ThriftServer的更多相关文章
- 理解Spark SQL(二)—— SQLContext和HiveContext
使用Spark SQL,除了使用之前介绍的方法,实际上还可以使用SQLContext或者HiveContext通过编程的方式实现.前者支持SQL语法解析器(SQL-92语法),后者支持SQL语法解析器 ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
- Spark SQL CLI 实现分析
背景 本文主要介绍了Spark SQL里眼下的CLI实现,代码之后肯定会有不少变动,所以我关注的是比較核心的逻辑.主要是对照了Hive CLI的实现方式,比較Spark SQL在哪块地方做了改动,哪些 ...
- 【原创 Hadoop&Spark 动手实践 9】Spark SQL 程序设计基础与动手实践(上)
[原创 Hadoop&Spark 动手实践 9]SparkSQL程序设计基础与动手实践(上) 目标: 1. 理解Spark SQL最基础的原理 2. 可以使用Spark SQL完成一些简单的数 ...
- 【原创 Hadoop&Spark 动手实践 10】Spark SQL 程序设计基础与动手实践(下)
[原创 Hadoop&Spark 动手实践 10]Spark SQL 程序设计基础与动手实践(下) 目标: 1. 深入理解Spark SQL 程序设计的原理 2. 通过简单的命令来验证Spar ...
- Spark SQL with Hive
前一篇文章是Spark SQL的入门篇Spark SQL初探,介绍了一些基础知识和API,可是离我们的日常使用还似乎差了一步之遥. 终结Shark的利用有2个: 1.和Spark程序的集成有诸多限制 ...
- SparkSQL使用之Spark SQL CLI
Spark SQL CLI描述 Spark SQL CLI的引入使得在SparkSQL中通过hive metastore就可以直接对hive进行查询更加方便:当前版本中还不能使用Spark SQL C ...
- 整理对Spark SQL的理解
Catalyst Catalyst是与Spark解耦的一个独立库,是一个impl-free的运行计划的生成和优化框架. 眼下与Spark Core还是耦合的.对此user邮件组里有人对此提出疑问,见m ...
- 6. 运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行任务查询.需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互.在Spark目录下执行如下命令 ...
随机推荐
- [Luogu2359] 三素数数
题目背景 蛟川书院的一道练习题QAQ 题目描述 如果一个数的所有连续三位数字都是大于100的素数,则该数称为三素数数.比如113797是一个6位的三素数数. 输入输出格式 输入格式: 一个整数n(3 ...
- Cocos2d-x 学习笔记(11.3) JumpBy JumpTo
1. JumpBy JumpTo JumpBy,边跳边平移,不只做垂直向上的抛物动作,同时还在向终点平移.JumpTo是JumpBy的子类. 1.1 成员变量 create方法 JumpBy: Vec ...
- 阿里云 centos7.X mysql数据库安装、配置
前言 1024阿里云搞活动,ecs云服务新用户促销活动,活动连接就不贴了,买了之后暂时不知道要做啥,想着先安装mysql数据库. 步骤 root用户登录进来 1.配置mysql的yum源,yum lo ...
- C#的集合类型及使用技巧
在日常开发过程中,我们不能避免的要对批量数据处理,这时候就要用到集合.集合总体上分为线性集合和非线性集合.线性集合是指元素具有唯一的前驱和后驱的数据结构类型:非线性集合是指有多个前驱和后驱的数据结构类 ...
- JavaScript 实用技巧
1数组中删除重复 let arr = [1,2,4,3,6,4] Array.from(new Set(arr)) // es6中 .from()[1,2,4,3,6] [...new Set(arr ...
- 百万年薪python之路 -- HTML标签
HTML标签 html标签分类 html标签又叫做html元素,它分为块级元素和内联元素(也可以叫做行内元素),都是html规范中的概念. 标题 h1 h2 h3 h4 h5 h6 列表 ol ul ...
- 06 python学习笔记-常用模块(六)
一. 模块.包 1.什么是模块? Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句,是用来组织代码的.模块能定义函数 ...
- 用MATLAB绘制折线图,x轴为字符串,并旋转一定的角度!!!
先上代码,然后再一行一行解释: x=1:37; %这一行其实一开始,写的时候是没有的,后来需要给X轴上规定几个刻度才加上的 plot(x,Y,'linewidth',2); %以x为自变量,y为因变量 ...
- epoll(2) 源码分析
epoll(2) 源码分析 文本内核代码取自 5.0.18 版本,和上一篇文章中的版本不同是因为另一个电脑出了问题,但是总体差异不大. 引子留下的问题 关键数据结构 提供的系统调用 就绪事件相关逻辑 ...
- 常用html转义符,JavaScript转义符
HTML字符实体(Character Entities),转义字符串(Escape Sequence) 为什么要用转义字符串? HTML中<,>,&等有特殊含义(<,> ...