Flink 从 0 到 1 学习 —— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧。
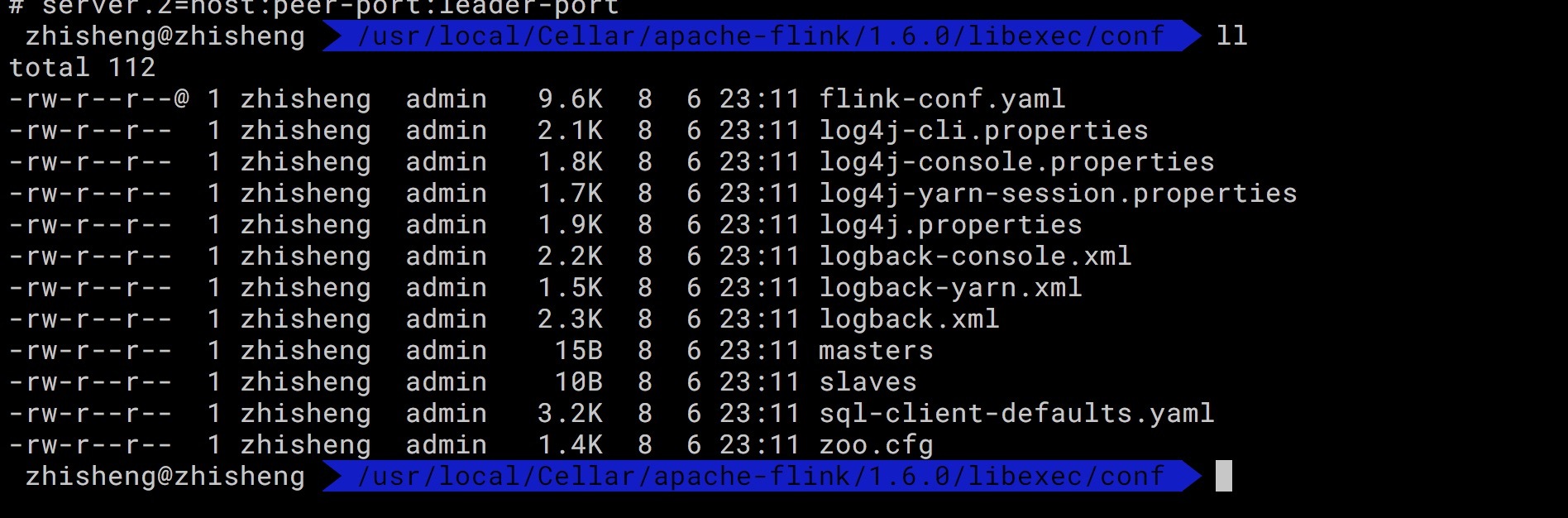
安装目录下主要有 flink-conf.yaml 配置、日志的配置文件、zk 配置、Flink SQL Client 配置。
flink-conf.yaml
基础配置
# jobManager 的IP地址
jobmanager.rpc.address: localhost
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 1
# 程序默认并行计算的个数
parallelism.default: 1
# 文件系统来源
# fs.default-scheme
高可用性配置
# 可以选择 'NONE' 或者 'zookeeper'.
# high-availability: zookeeper
# 文件系统路径,让 Flink 在高可用性设置中持久保存元数据
# high-availability.storageDir: hdfs:///flink/ha/
# zookeeper 集群中仲裁者的机器 ip 和 port 端口号
# high-availability.zookeeper.quorum: localhost:2181
# 默认是 open,如果 zookeeper security 启用了该值会更改成 creator
# high-availability.zookeeper.client.acl: open
容错和检查点 配置
# 用于存储和检查点状态
# state.backend: filesystem
# 存储检查点的数据文件和元数据的默认目录
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints 的默认目标目录(可选)
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 用于启用/禁用增量 checkpoints 的标志
# state.backend.incremental: false
web 前端配置
# 基于 Web 的运行时监视器侦听的地址.
#jobmanager.web.address: 0.0.0.0
# Web 的运行时监视器端口
rest.port: 8081
# 是否从基于 Web 的 jobmanager 启用作业提交
# jobmanager.web.submit.enable: false
高级配置
# io.tmp.dirs: /tmp
# 是否应在 TaskManager 启动时预先分配 TaskManager 管理的内存
# taskmanager.memory.preallocate: false
# 类加载解析顺序,是先检查用户代码 jar(“child-first”)还是应用程序类路径(“parent-first”)。 默认设置指示首先从用户代码 jar 加载类
# classloader.resolve-order: child-first
# 用于网络缓冲区的 JVM 内存的分数。 这决定了 TaskManager 可以同时拥有多少流数据交换通道以及通道缓冲的程度。 如果作业被拒绝或者您收到系统没有足够缓冲区的警告,请增加此值或下面的最小/最大值。 另请注意,“taskmanager.network.memory.min”和“taskmanager.network.memory.max”可能会覆盖此分数
# taskmanager.network.memory.fraction: 0.1
# taskmanager.network.memory.min: 67108864
# taskmanager.network.memory.max: 1073741824
Flink 集群安全配置
# 指示是否从 Kerberos ticket 缓存中读取
# security.kerberos.login.use-ticket-cache: true
# 包含用户凭据的 Kerberos 密钥表文件的绝对路径
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# 与 keytab 关联的 Kerberos 主体名称
# security.kerberos.login.principal: flink-user
# 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证)
# security.kerberos.login.contexts: Client,KafkaClient
Zookeeper 安全配置
# 覆盖以下配置以提供自定义 ZK 服务名称
# zookeeper.sasl.service-name: zookeeper
# 该配置必须匹配 "security.kerberos.login.contexts" 中的列表(含有一个)
# zookeeper.sasl.login-context-name: Client
HistoryServer
# 你可以通过 bin/historyserver.sh (start|stop) 命令启动和关闭 HistoryServer
# 将已完成的作业上传到的目录
# jobmanager.archive.fs.dir: hdfs:///completed-jobs/
# 基于 Web 的 HistoryServer 的地址
# historyserver.web.address: 0.0.0.0
# 基于 Web 的 HistoryServer 的端口号
# historyserver.web.port: 8082
# 以逗号分隔的目录列表,用于监视已完成的作业
# historyserver.archive.fs.dir: hdfs:///completed-jobs/
# 刷新受监控目录的时间间隔(以毫秒为单位)
# historyserver.archive.fs.refresh-interval: 10000
查看下另外两个配置 slaves / master

2、slaves
里面是每个 worker 节点的 IP/Hostname,每一个 worker 结点之后都会运行一个 TaskManager,一个一行。
localhost
3、masters
host:port
localhost:8081
4、zoo.cfg
# 每个 tick 的毫秒数
tickTime=2000
# 初始同步阶段可以采用的 tick 数
initLimit=10
# 在发送请求和获取确认之间可以传递的 tick 数
syncLimit=5
# 存储快照的目录
# dataDir=/tmp/zookeeper
# 客户端将连接的端口
clientPort=2181
# ZooKeeper quorum peers
server.1=localhost:2888:3888
# server.2=host:peer-port:leader-port
5、日志配置
Flink 在不同平台下运行的日志文件
log4j-cli.properties
log4j-console.properties
log4j-yarn-session.properties
log4j.properties
logback-console.xml
logback-yarn.xml
logback.xml
sql-client-defaults.yaml
execution:
# 'batch' or 'streaming' execution
type: streaming
# allow 'event-time' or only 'processing-time' in sources
time-characteristic: event-time
# interval in ms for emitting periodic watermarks
periodic-watermarks-interval: 200
# 'changelog' or 'table' presentation of results
result-mode: changelog
# parallelism of the program
parallelism: 1
# maximum parallelism
max-parallelism: 128
# minimum idle state retention in ms
min-idle-state-retention: 0
# maximum idle state retention in ms
max-idle-state-retention: 0
deployment:
# general cluster communication timeout in ms
response-timeout: 5000
# (optional) address from cluster to gateway
gateway-address: ""
# (optional) port from cluster to gateway
gateway-port: 0
Flink sql client :你可以从官网这里了解 https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/sqlClient.html
总结
本文拿安装目录文件下的配置文件讲解了下 Flink 目录下的所有配置。
你也可以通过官网这里学习更多:https://ci.apache.org/projects/flink/flink-docs-stable/ops/config.html
关注我
本篇文章地址是:http://www.54tianzhisheng.cn/2018/10/27/flink-config/
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、实战、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus
27、Flink 源码解析 —— 如何获取 ExecutionGraph ?
30、Flink Clients 源码解析
原文出处:zhisheng的博客,欢迎关注我的公众号:zhisheng
Flink 从 0 到 1 学习 —— Flink 配置文件详解的更多相关文章
- Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
前言 今天上午被 Flink 的一个算子困惑了下,具体问题是什么呢? 我有这么个需求:有不同种类型的告警数据流(包含恢复数据),然后我要将这些数据流做一个拆分,拆分后的话,每种告警里面的数据又想将告警 ...
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
- Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
toc: true title: Flink 从 0 到 1 学习 -- Flink Data transformation(转换) date: 2018-11-04 tags: Flink 大数据 ...
- Elasticsearch 学习之配置文件详解
Elasticsearch配置文件##################### Elasticsearch Configuration Example ##################### # # ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?
前言 在 <从0到1学习Flink>-- Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇 ...
- 《从0到1学习Flink》—— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- 《从0到1学习Flink》—— Flink 写入数据到 Kafka
前言 之前文章 <从0到1学习Flink>-- Flink 写入数据到 ElasticSearch 写了如何将 Kafka 中的数据存储到 ElasticSearch 中,里面其实就已经用 ...
随机推荐
- wordpress搬家 更换域名
结论:wordpress网站文件夹是和域名相关联的 wordpress,备份了数据库 然后用另一个新域名新建站,直接从wordpress官网直接下载的网站压缩包,没有用之前的网站文件夹. 然后把原来的 ...
- socket基于TCP(粘包现象和处理)
目录 6socket套接字 7基于TCP协议的socket简单的网络通信 AF_UNIX AF_INET(应用最广泛的一个) 报错类型 单一 链接+循环通信 远程命令 9.tcp 实例:远程执行命令 ...
- Vue cli2.0 项目中使用Monaco Editor编辑器
monaco-editor 是微软出的一条开源web在线编辑器支持多种语言,代码高亮,代码提示等功能,与Visual Studio Code 功能几乎相同. 在项目中可能会用带代码编辑功能,或者展示代 ...
- Mybatis中使用PageHelper插件进行分页
分页的场景比较常见,下面主要介绍一下使用PageHelper插件进行分页操作: 一.概述: PageHelper支持对mybatis进行分页操作,项目在github地址: https://github ...
- HBase 系列(七)——HBase 过滤器详解
一.HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predic ...
- Java 操作Word书签(二):添加文本、图片、表格到书签内容
在Java操作Word书签(一)中介绍了给Word中的特定段落或文字添加书签.读取及删除已有书签的方法,本文将继续介绍Java 操作Word书签的方法,即如何给已有的书签添加内容,包括添加文本.图片. ...
- Vue入门到TodoList练手
学习资料 慕课网 - vue2.5入门 基础语法 示例代码1 <div id="root"> <h1>hello {{msg}}</h1> &l ...
- netty无缝切换rabbitmq、activemq、rocketmq实现聊天室单聊、群聊功能
netty的pipeline处理链上的handler:需要IdleStateHandler心跳检测channel是否有效,以及处理登录认证的UserAuthHandler和消息处理MessageHan ...
- 怎样才算精通Linux
1.掌握至少50个以上的常用命令(包括grep.awk.sed.ps.find等等吧,熟练使用,基础的选项不用man) 2.熟悉Gnome/KDE等X-windows桌面环境操作 3.掌握.tgz.. ...
- 【RabbitMQ】如何进行消息可靠投递【下篇】
说明 上一篇文章里,我们了解了如何保证消息被可靠投递到RabbitMQ的交换机中,但还有一些不完美的地方,试想一下,如果向RabbitMQ服务器发送一条消息,服务器确实也接收到了这条消息,于是给你返回 ...