爬虫框架Scrapy入门——爬取acg12某页面
1.1自行安装python3环境
1.2ide使用pycharm
1.3安装scrapy框架
2.入门案例
2.1新建项目工程
2.2配置settings文件
2.3新建爬虫app
新建app
将start_urls的值修改为需要爬取的第一个url
修改parse()方法
然后运行一下看看,在mySpider目录下执行:
1.安装
1.1自行安装python3环境
1.2ide使用pycharm
1.3安装scrapy框架
pip install twisted
pip install lxml
pip install scrapy2.入门案例
2.1新建项目工程
scrapy startproject mySpider2.2配置settings文件
ROBOTSTXT_OBEY = True
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
ua = random.choice(USER_AGENT_LIST)
if ua:
USER_AGENT = ua
print(ua)
else:
USER_AGENT = "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
#是否遵守robots规则
ROBOTSTXT_OBEY = False
#线程数量
CONCURRENT_REQUESTS = 32
#下载延迟单位秒
DOWNLOAD_DELAY = 3
#cookies开关,建议禁用
COOKIES_ENABLED = False2.3新建爬虫app
新建app
在spiders目录下
scrapy genspider acg12 "acg12.com"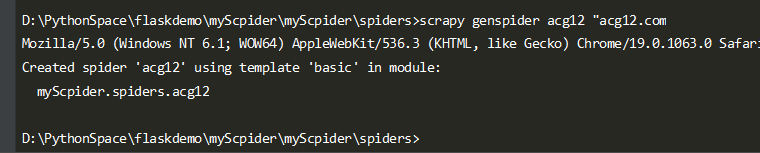
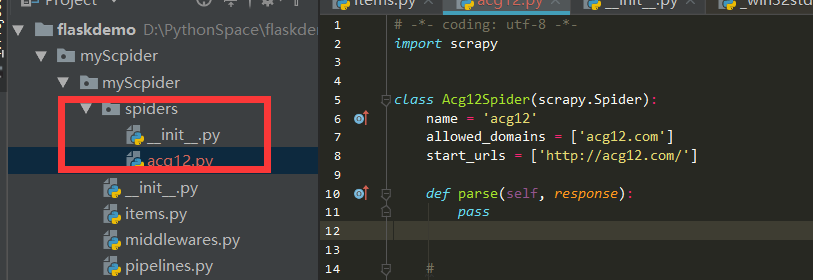
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("https://acg12.com/274004/",) #这个网页可能坏掉换一个新的修改parse()方法
def parse(self, response):
with open("acg12.html", "w",encoding='utf-8') as f:
f.write(response.text)然后运行一下看看,在mySpider目录下执行:
scrapy crawl acg12是的,就是 acg12,看上面代码,它是 Acg12Spider 类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
爬虫框架Scrapy入门——爬取acg12某页面的更多相关文章
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
随机推荐
- Android H5混合开发(4):构建Cordova Jar包
前言 上一节,介绍了原生项目如何嵌入Cordova,我们对Cordova的依赖使用的是CordovaLib Module,这也是安卓项目常用的方式. 但是,也有项目希望以Jar包的方式依赖Cordov ...
- 如何获取比 dism.log 更详细的日志
正文 在工作中,曾经遇到过一个问题. 有一个 component,名字叫做 Oxford Adaptive Learning Dictionary,是一款牛津词典的应用.这个 component,需要 ...
- 大公司喜欢问的Java集合类面试题
Collection Collection是基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements).一些Collection允许相同的元素而另一 ...
- hack the box -- sizzle 渗透过程总结,之前对涉及到域内证书啥的还不怎么了解
把之前的笔记搬运过来 --- 1 开了443,用smbclient建立空连接查看共享 smbclient -N -L \\\\1.1.1.1 Department Shares Operatio ...
- NOIP模拟 33
苏轼三连一脸懵逼 然而既惨者就是没素质 T1是正解思路 然而因为直接从暴力修改过来并且忘了把求约数改成求质约数并且由于快速幂打的有缺陷等 没 有 A C ! 如 果 A C rank1就是俺的了! ( ...
- 2018年7月份JAVA开源软件TOP3
微信开发 Java SDK Weixin Java Tools 评分: 9.6 介绍: 信开发 Java 开发工具包(SDK),支持包括微信支付.微信开放平台.小程序.企业号/企业微信.公众号(包括服 ...
- python、C++经典算法题:打印100以内的素数
题目 打印100以内的素数 思路1 素数的特点: 素数一定是奇数 一个数如果是合数,那么它一定能够被2到这个合数的开平方内的某个素数整除(这个特点是提升效率的关键) 一个数如果不能被从2到它自身开平方 ...
- markdown文档
标题 #加空格# 加粗 *加粗* 斜体 **斜体** 斜体加粗 ***斜体加粗*** 删除线 ~~删除线~~~ 引用 >引用 分割线 --- 超链接[题目](网址) 列表 -加空格 列表内容 ...
- java 中的 shuffle()用于打乱list中的元素
题目描述: 数组里面有{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},请随机打乱顺序生成新的数组: import java.util.ArrayList; import java.ut ...
- nyoj 56-阶乘因式分解(一)(数学)
56-阶乘因式分解(一) 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:15 submit:16 题目描述: 给定两个数m,n,其中m是一个素数. ...