爬虫框架Scrapy入门——爬取acg12某页面
1.1自行安装python3环境
1.2ide使用pycharm
1.3安装scrapy框架
2.入门案例
2.1新建项目工程
2.2配置settings文件
2.3新建爬虫app
新建app
将start_urls的值修改为需要爬取的第一个url
修改parse()方法
然后运行一下看看,在mySpider目录下执行:
1.安装
1.1自行安装python3环境
1.2ide使用pycharm
1.3安装scrapy框架
pip install twisted
pip install lxml
pip install scrapy2.入门案例
2.1新建项目工程
scrapy startproject mySpider2.2配置settings文件
ROBOTSTXT_OBEY = True
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
ua = random.choice(USER_AGENT_LIST)
if ua:
USER_AGENT = ua
print(ua)
else:
USER_AGENT = "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
#是否遵守robots规则
ROBOTSTXT_OBEY = False
#线程数量
CONCURRENT_REQUESTS = 32
#下载延迟单位秒
DOWNLOAD_DELAY = 3
#cookies开关,建议禁用
COOKIES_ENABLED = False2.3新建爬虫app
新建app
在spiders目录下
scrapy genspider acg12 "acg12.com"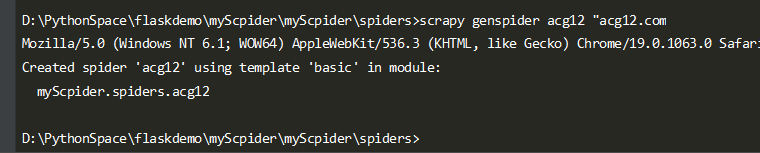
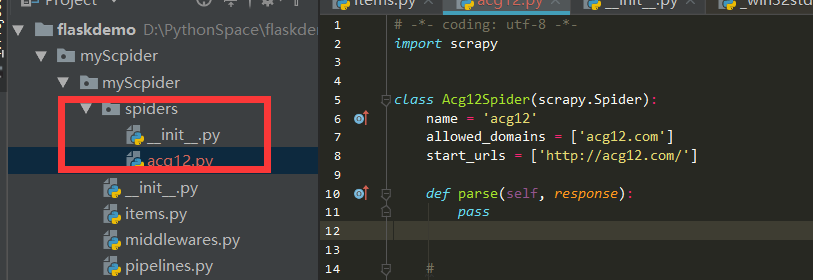
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("https://acg12.com/274004/",) #这个网页可能坏掉换一个新的修改parse()方法
def parse(self, response):
with open("acg12.html", "w",encoding='utf-8') as f:
f.write(response.text)然后运行一下看看,在mySpider目录下执行:
scrapy crawl acg12是的,就是 acg12,看上面代码,它是 Acg12Spider 类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
爬虫框架Scrapy入门——爬取acg12某页面的更多相关文章
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
随机推荐
- 在线预览office文件
Office Online 实现在线预览 office的在线预览,针对不同的浏览器版本和系统具有要求,具体的相关文档请参考官方文档. 利用office online 平台进行office 文档的在线查 ...
- Java编程思想——第14章 类型信息(一)
运行时类型信息使得你可以在程序运行时发现和使用类型信息.Java是如何让我们在运行时识别对象和类的信息得呢? 主要有两种方式:1.传统RTTI,他假定我们在编译期间已经知道了所有类型:2.反射,它允许 ...
- python的位置参数、关键字参数、收集参数,关键字收集参数混合调用问题
参数混合调用顺序用法: 函数中参数顺序为:普通参数,收集参数,关键字参数,关键字收集参数,其顺序不能颠倒,颠倒会报错. 普通参数.关键字参数可以有n个,对量没有具体要求,收集参数和关键字收集参数要么没 ...
- [2018-06-28] django项目 实例
实例一.显示一个基本的字符串在网页中 首先先进入views.py def home(request): string = u'随便写' return render(request, 'home.htm ...
- 监控tomcat,自动启动
tomcatID=`ps -ef |grep tomcat |grep -v 'grep'|awk '{print $2}'` tomcatCount=`ps -ef|grep tomcat |gr ...
- 用selenium实现打码平台
注:本文以 人人网登陆 为例 import time from selenium import webdriver # 准备一个名为yudama的py文件 from yudama import in ...
- Selenium +Chrome浏览器如何模拟手机操作
Selenium +Chrome浏览器如何模拟手机操作 进入手机模式 打开谷歌浏览器,按F12,进入开发者模式,点击Toggle device toolbar,进入手机模式 设置Chrome的手机模式 ...
- Project Euler 57: Square root convergents
五十七.平方根收敛(Square root convergents) 二的平方根可以表示为以下这个无穷连分数: \[ \sqrt 2 =1+ \frac 1 {2+ \frac 1 {2 +\frac ...
- csp-s m 80 题解
写在前面:(扯淡话) 这次考试是AB组分开考,但是觉得题目并不是很水,所以就来写一下题解,其实这次由于翘掉了午休,所以考试的前半部分还是比较困的(越做越清醒!)今天调完还是很有感触的! 正文: T1 ...
- Wireshark嗅探抓取telnet明文账户密码
0x00 Wireshark(前称Ethereal)是一个网络封包分析软件.网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料.Wireshark使用WinPCAP作为接口,直 ...