Python常用的正则表达式处理函数
Python常用的正则表达式处理函数
正则表达式是一个特殊的字符序列,用于简洁表达一组字符串特征,检查一个字符串是否与某种模式匹配,使用起来十分方便。
在Python中,我们通过调用re库来使用re模块:
import re
正则表达式语法模式和操作符详见:https://www.runoob.com/python/python-reg-expressions.html#flags
下面介绍Python常用的正则表达式处理函数。
re.match函数
re.match 函数从字符串的起始位置匹配正则表达式,返回match对象,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。具体参数为:
re.I:忽略大小写。
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境。
re.M:多行模式。
re.S:即 . ,并且包括换行符在内的任意字符(. 不包括换行符)。
re.U:表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库。
re.X:为了增加可读性,忽略空格和 # 后面的注释。
import re
#从起始位置匹配
r1=re.match('abc','abcdefghi')
print(r1)
#不从起始位置匹配
r2=re.match('def','abcdefghi')
print(r2)
运行结果:
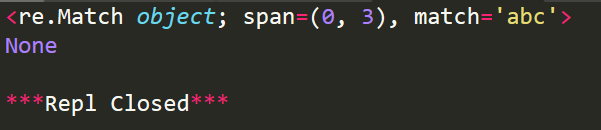
其中,span表示匹配成功的整个子串的索引。
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s='This is a demo'
r1=re.match(r'(.*) is (.*)',s)
r2=re.match(r'(.*) is (.*?)',s) print(r1.group())
print(r1.group(1))
print(r1.group(2))
print(r1.groups())
print()
print(r2.group())
print(r2.group(1))
print(r2.group(2))
print(r2.groups())
运行结果:
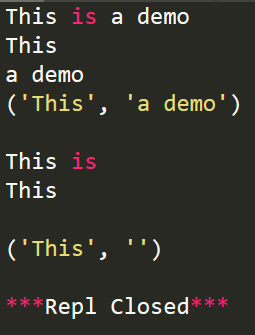
上述代码中的(.*)和(.*?)表示正则表达式的贪婪匹配与非贪婪匹配,详情见此:https://blog.csdn.net/lxcnn/article/details/4756030
re.search函数
re.search函数扫描整个字符串并返回第一个成功的匹配,如果匹配成功则返回match对象,否则返回None。
re.search(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
#从起始位置匹配
r1=re.search('abc','abcdefghi')
print(r1)
#不从起始位置匹配
r2=re.search('def','abcdefghi')
print(r2)
运行结果:
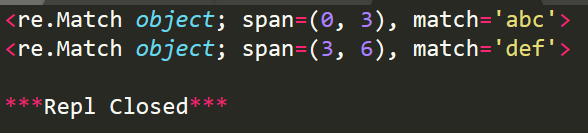
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group(num=0):匹配的整个表达式的字符串,group() 可以一次输入多个组号,这时它将返回一个包含那些组所对应值的元组。
groups():返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re s='This is a demo'
r1=re.search(r'(.*) is (.*)',s)
r2=re.search(r'(.*) is (.*?)',s) print(r1.group())
print(r1.group(1))
print(r1.group(2))
print(r1.groups())
print()
print(r2.group())
print(r2.group(1))
print(r2.group(2))
print(r2.groups())
运行结果:
从上面不难发现re.match与re.search的区别:re.match只匹配字符串的起始位置,只要起始位置不符合正则表达式就匹配失败,而re.search是匹配整个字符串,直到找到一个匹配为止。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式对象,供 match() 和 search() 这两个函数使用。
re.compile(pattern[, flags])
pattern:一个字符串形式的正则表达式。
flags:可选,表示匹配模式,比如忽略大小写,多行模式等。
import re
#匹配数字
r=re.compile(r'\d+')
r1=r.match('This is a demo')
r2=r.match('This is 111 and That is 222',0,27)
r3=r.match('This is 111 and That is 222',8,27) print(r1)
print(r2)
print(r3)
运行结果:
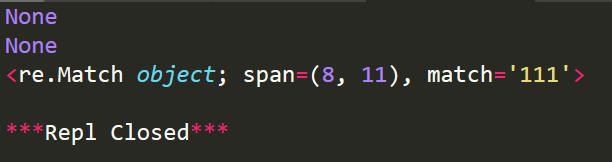
findall函数
搜索字符串,以列表形式返回正则表达式匹配的所有子串,如果没有找到匹配的,则返回空列表。
需要注意的是,match 和 search 是匹配一次,而findall 匹配所有。
findall(string[, pos[, endpos]])
string:待匹配的字符串。
pos:可选参数,指定字符串的起始位置,默认为0。
endpos:可选参数,指定字符串的结束位置,默认为字符串的长度。
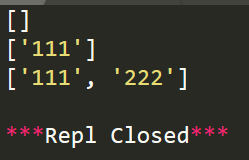
import re
#匹配数字
r=re.compile(r'\d+')
r1=r.findall('This is a demo')
r2=r.findall('This is 111 and That is 222',0,11)
r3=r.findall('This is 111 and That is 222',0,27) print(r1)
print(r2)
print(r3)
运行结果:
re.finditer函数
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等。
import re r=re.finditer(r'\d+','This is 111 and That is 222')
for i in r:
print (i.group())
运行结果:

re.split函数
将一个字符串按照正则表达式匹配的子串进行分割后,以列表形式返回。
re.split(pattern, string[, maxsplit=0, flags=0])
pattern:匹配的正则表达式。
string:待匹配的字符串。
maxsplit:分割次数,maxsplit=1分割一次,默认为0,不限次数。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等。
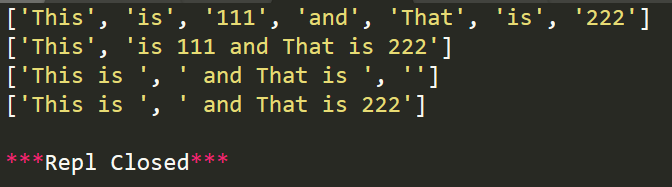
import re
r1=re.split('\W+','This is 111 and That is 222')
r2=re.split('\W+','This is 111 and That is 222',maxsplit=1)
r3=re.split('\d+','This is 111 and That is 222')
r4=re.split('\d+','This is 111 and That is 222',maxsplit=1)
print(r1)
print(r2)
print(r3)
print(r4)
运行结果:
re.sub函数
re.sub函数用于替换字符串中的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)
pattern:正则中的模式字符串。
repl:替换的字符串,也可为一个函数。
string:要被查找替换的原始字符串。
count:模式匹配后替换的最大次数,默认0表示替换所有的匹配。
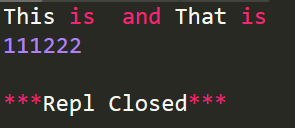
import re r='This is 111 and That is 222'
# 删除字符串中的数字
r1=re.sub(r'\d+','',r)
print(r1)
# 删除非数字的字符串
r2=re.sub(r'\D','',r)
print(r2)
运行结果:
参考资料:
https://www.runoob.com/python/python-reg-expressions.html#flags
search
Python常用的正则表达式处理函数的更多相关文章
- python常用的内置函数哈哈
python常用的内置函数集合做一个归类用的时候可以查找 abs 返回数字x的绝对值或者x的摸 all (iterable)对于可迭代的对象iterable中所有元素x都有bool(x)为true,就 ...
- python常用的内置函数
python常用的内置函数集合做一个归类用的时候可以查找- abs 返回数字x的绝对值或者x的摸 - all (iterable)对于可迭代的对象iterable中所有元素x都有bool(x)为tru ...
- Python_常用的正则表达式处理函数
正则表达式就是用查找字符串的,它能查找规则比较复杂的字符串反斜杠:正则表达式里面用"\"作为转义字符. s='<a class="h3" href=&qu ...
- python 常用的高阶函数
前言 高阶函数指的是能接收函数作为参数的函数或类:python中有一些内置的高阶函数,在某些场合使用可以提高代码的效率. map() map函数可以把一个迭代对象转换成另一个可迭代对象,不过在pyth ...
- python常用的正则表达式,持续更新<<
# -*- coding: utf-8 -*- import re str_0 = 'Aqin1012Heheheaaaaaaahehe如何da' def re_str(re_str_0,str_0) ...
- Python 常用的正则表达式
校验数字的相关表达式: 功能 表达式 数字 ^[0-9]*$ n位的数字 ^\d{n}$ 至少n位的数字 ^\d{n,}$ m-n位的数字 ^\d{m,n}$ 零和非零开头的数字 ^(0|[1-9][ ...
- Python 常用的内置函数
1. str.isdigit( ) 作用:检测字符串是否有数字组成 2. strip( ) 作用:除去首尾指定的字符,包括空格,换行符,不能除去中间的字符 3. slice( ) 作用:以指定参数切割 ...
- Python基础学习笔记(七)常用元组内置函数
参考资料: 1. <Python基础教程> 2. http://www.runoob.com/python/python-tuples.html 3. http://www.liaoxue ...
- [Python Study Notes]正则表达式
正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 P ...
随机推荐
- 《Dotnet9》系列-Google ProtoBuf在C#中的简单应用
时间如流水,只能流去不流回! 点赞再看,养成习惯,这是您给我创作的动力! 本文 Dotnet9 https://dotnet9.com 已收录,站长乐于分享dotnet相关技术,比如Winform.W ...
- Android组件体系之视图绘制
一.View组件View组件有几个重要的方法需要关注,也是自定义View经常需要重写的方法. 1.measure作用是测量View组件的尺寸.对应的方法是onMeasure,测量View的宽和高.Vi ...
- Android组件体系之ContentProvider使用注意事项
1.数据访问机制 客户端/调用者通过getContentResolver调用,由ActivityThread.AMS获取到ContentProvider的代理,再通过这个代理对象调用服务端的实现(也即 ...
- ESP32的NVS使用指南
NVS总的来说,就是非易失性存储,类似MCU EEPROM,但实际上调用ESP32这些函数,数据是存储在FLASH中的. 它的管理方式类似数据库的表,在NVS里面可以存储很多个不同的表,每个表下面有不 ...
- 如何实现一台服务器同时运行两个php版本
有需要学习交流的友人请加入交流群的咱们一起,有问题一起交流,一起进步!前提是你是学技术的.感谢阅读! 点此加入该群jq.qq.com 假设您已经安装了Apache,为这两个项目创建了虚拟主机,并添加 ...
- 前端小白webpack学习(四)
.less文件与.scss文件使用与.css文件相仿 less-loader使用需要借助less插件,终端输入npm i less less-loader -D安装; sass-loader使用需要借 ...
- 计算几何 val.3
目录 计算几何 val.3 自适应辛普森法 定积分 引入 辛普森公式 处理精度 代码实现 模板 时间复杂度 练习 闵可夫斯基和 Pick定理 结论 例题 后记 计算几何 val.3 自适应辛普森法 可 ...
- Centos 下安装 Nginx(新)
今天重新实践了下 CentOS 7.6 下安装 Nginx,总结了一条更直接并简单的方式 从官方获取写入 nginx.repo 的方式 从官网查看文档,获取 nginx.repo 的文档内容,将其内容 ...
- C# base
using System; using System.Collections.Generic; using System.Text; namespace 继承 { class Program { st ...
- http请求报400错误的原因分析
在ajax请求后台数据时有时会报 HTTP 400 错误 - 请求无效 (Bad request);出现这个请求无效报错说明请求没有进入到后台服务里: 原因:1)前端提交数据的字段名称或者是字段类型 ...