转 python2 与 python3 的编码
原文链接:https://blog.csdn.net/xufive/article/details/102726739
引文如下:
无论是py2还是py3,都使用unicode作为内存编码,简称内码。保存在python解释器内存中的文本,输出到屏幕、编辑器,或者保存成文件的时候,都要将内码转换成utf8或者gbk等编码格式;同样,python解释器从输入设备接收文本,或者从文件读取文本的时候,都要将utf8或者gbk等编码转换成unicode编码格式。因此,无论是py2还是py3,想要在unicode、utf8、gbk等编码格式之间转换的话,下图是通用的:

我们之所以会产生困惑,是因为py2和py3给这些编码格式指定了令人困惑的名字。py2的字符串有两种类型:unicode类型和str类型。py2的unicode类型就是unicode编码,py2的str类型泛指除unicode编码之外的所有编码,包括ascii编码、utf8编码、gbk编码、cp936编码等。py3的字符串也有两种类型:bytes类型和str类型。py3的str类型就是unicode编码,py3的bytes类型泛指除unicode编码之外的所有编码,包括ascii编码、utf8编码、gbk编码、cp936编码等。同样是str类型,在py2和py3中完全颠倒了!下图稍微补充了一点内容,更有助于理解编码问题。
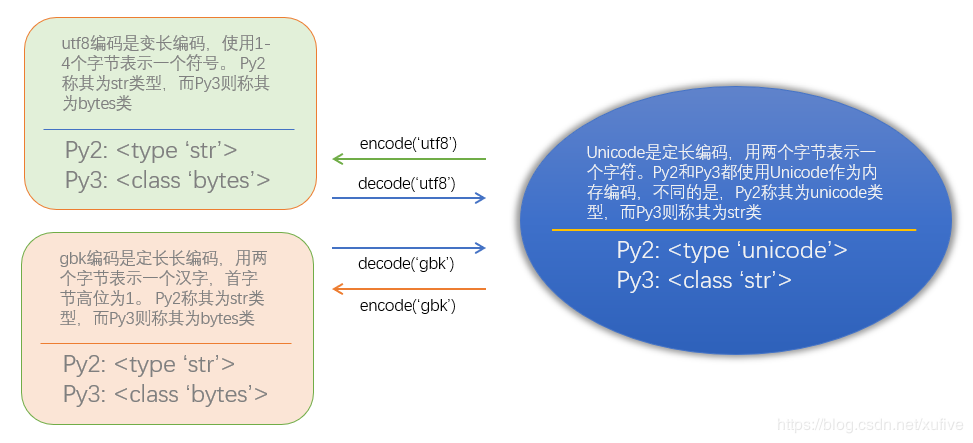
接下来,我们实战演练一下。
>>> s = 'abc天圆地方'
>>> type(s)
<class 'str'>
>>> len(s)
7
>>> s
'abc天圆地方'
>>> print(s)
abc天圆地方
>>> s.encode('unicode-escape')
b'abc\\u5929\\u5706\\u5730\\u65b9'
不管是否在字符串前面加了u,只要不在字符串前面使用b,在IDLE中定义的字符串都是unicode编码,也就是py3的<class ‘str’>,其长度就是字符数量,不是字节数。我们把unicode字符串’abc天圆地方’转成utf8编码:
>>> s_utf8 = s.encode('utf8')
>>> type(s_utf8)
<class 'bytes'>
>>> len(s_utf8)
15
>>> s_utf8
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9'
>>> print(s_utf8)
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9'
>>> s_utf8.decode('utf8')
'abc天圆地方'
utf8编码就是bytes类型(字节码),长度就是字节数量。我们把unicode字符串’abc天圆地方’转成gbk编码:
>>> s_gbk= s.encode('gbk')
>>> type(s_gbk)
<class 'bytes'>
>>> len(s_gbk)
11
>>> s_gbk
b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> print(s_gbk)
b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> s_gbk.decode('s_gbk')
'abc天圆地方'
gbk编码也是bytes类型(字节码),长度也是字节数量。我们再来看看,不同编码的字节码能否连接:
>>> ss = s_utf8 + s_gbk
>>> ss
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> ss.decode('utf8')
Traceback (most recent call last):
File "<pyshell#64>", line 1, in <module>
ss.decode('utf8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 18: invalid continuation byte
>>> ss.decode('gbk')
'abc澶╁渾鍦版柟abc天圆地方'
>>> ss.decode('utf8', 'ignore')
'abc天圆地方abcԲط'
>>> ss.decode('gbk', 'ignore')
'abc澶╁渾鍦版柟abc天圆地方'
看以看出,不同编码的字节码可以连接,但一般不能解码成unicode(字符串),除非使用ignore参数。
转 python2 与 python3 的编码的更多相关文章
- day008 字符编码之 字符编码 、Python2和Python3字符编码的区别
计算机基础(掌握) 启动应用程序的流程 双击qq 操作系统接受指令然后把该操作转化为0和1发送给CPU CPU接受指令然后把指令发送给内存 内存接受指令把指令发送给硬盘获取数据 qq在内存中运行 文本 ...
- 字符编码 + python2和python3的编码区别(day08整理)
目录 昨日回顾 二十三.元组内置方法 二十四.散列表 二十五.字典内置方法 二十六.集合内置方法 二十七.深浅拷贝 拷贝 浅拷贝 深拷贝 今日内容 二十八.字符编码 1.文本编辑器存储信息的过程 2. ...
- Python2 与 Python3 的编码对比
在 Python 中,不论是 Python2 还是 Python3 中,总体上说,字符都只有两大类: 通用的 Unicode 字符: (unicode 被编码后的)某种编码类型的字符,比如 UTF-8 ...
- Python2与Python3字符编码的区别
目录 字符编码应用之Python(掌握) 执行Python程序的三个阶段 Python2与Python3字符串类型的区别(了解) Python2 str类型 Unicode类型 Python3 字符编 ...
- python2和python3的编码问题
python2中有两种类型 str字符串和unicode字符串 python3则改成了 bytes和str字符串 在python2中‘xxx’和b‘xxx’都是str字符串,u‘xxx’是unicod ...
- python2和python3的编码encode解码decode函数
python比较坑的一个点:意义完全变了的两个函数 首先 常用的编码方式有3种,utf-8: 常用的传输和存储格式,Unicode的一种简化 Unicode:包括了所有可能字符的国际统一编码 GBK ...
- python2与python3 字符问题以及 字符编码 内容总结
python2与python3默认编码: python2:gbk print( u'上' ) 操作系统也是 gbk python3:unicode p ...
- 字符编码、python2和python3编码的区别
目录 字符编码 文本编辑器存储信息的过程 python解释器解释python代码的流程 python解释器与文本编辑器的异同 不同编码格式存入与读取数据的过程 乱码的分析 python2和python ...
- Python2和Python3中的字符串编码问题解决
Python2和Python3在字符串编码上是有明显的区别. 在Python2中,字符串无法完全地支持国际字符集和Unicode编码.为了解决这种限制,Python2对Unicode数据使用了单独的字 ...
随机推荐
- ubuntu18docker下安装MySQL
sudo docker run –name mysqldb -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root-d mysql:latest 这里的容器名字叫:mysql ...
- spark读写Oracle、hive的艰辛之路(二)-Oracle的date类型
近期又有需求为:导入Oracle的表到hive库中: 关于spark读取Oracle到hive有以下两点需要说明: 1.数据量较小时,可以直接使用spark.read.jdbc(orclUrl,tab ...
- SpringBoot 之Spring Boot Starter依赖包及作用(自己还没有看)
spring-boot-starter 这是Spring Boot的核心启动器,包含了自动配置.日志和YAML. spring-boot-starter-amqp 通过spring-rabbit来支持 ...
- [React] Handle React Suspense Errors with an Error Boundary
Error Boundaries are the way you handle errors with React, and Suspense embraces this completely. Le ...
- 文件描述符fd,struct files_struct
程序可以理解为硬盘上的普通二进制文件:进程是加载到内存中的二进制文件,除了加载到内存中的二进制文件外,还附有所有对于该二进制文件描述信息的结构体,描述该进程的结构体叫PCB(进程控制块),在这就不在讨 ...
- pycharm中使用2to3
https://www.jianshu.com/p/abbb005ba002 可用
- uniapp登录流程详解uni.login
uni.login(OBJECT)登录 H5平台登陆注意事项: 微信内嵌浏览器运行H5版时,可通过js sdk实现微信登陆,需要引入一个单独的js,详见普通浏览器上实现微信登陆,并非开放API,需要向 ...
- python 路径拼接
>>> import os>>> os.path.join('/hello/','good/boy/','doiido')>>>'/hello/g ...
- curl 设置超时时间
使用CURL时,有两个超时时间:一个是连接超时时间,另一个是数据传输的最大允许时间.连接超时时间用--connect-timeout参数来指定,数据传输的最大允许时间用-m参数来指定. curl -- ...
- 【CSP模拟赛】Freda的旗帜
题目描述 要开运动会了,Freda承担起了制作全校旗帜的工作.旗帜的制作方法是这样的:Freda一共有C种颜色的布条,每种布条都有无数个,你可以认为这些布条的长.宽.厚都相等,只有颜色可能不同.每个 ...