Kafka中的HW、LEO、LSO等分别代表什么?
HW 、 LEO 等概念和上一篇文章所说的 ISR有着紧密的关系,如果不了解 ISR 可以先看下ISR相关的介绍。
HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
下图表示一个日志文件,这个日志文件中只有9条消息,第一条消息的offset(LogStartOffset)为0,最有一条消息的offset为8,offset为9的消息使用虚线表示的,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。

LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。上图中offset为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的offset值加1.分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
下面具体分析一下 ISR 集合和 HW、LEO的关系。
假设某分区的 ISR 集合中有 3 个副本,即一个 leader 副本和 2 个 follower 副本,此时分区的 LEO 和 HW 都分别为 3 。消息3和消息4从生产者出发之后先被存入leader副本。
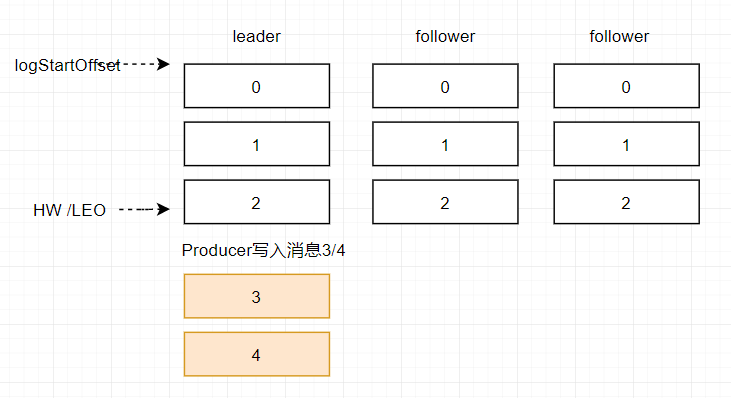
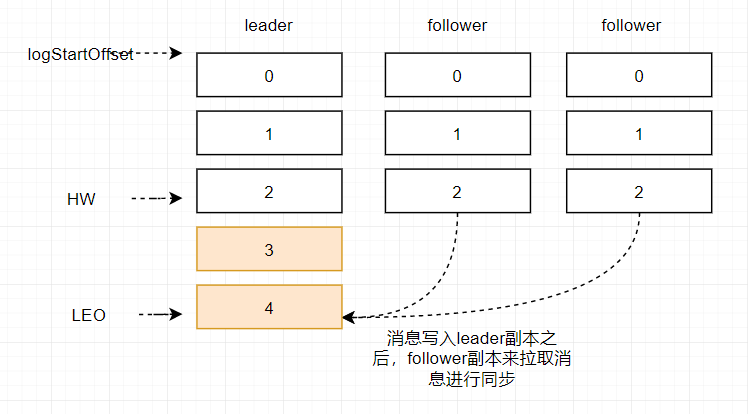
在消息被写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4进行消息同步。
在同步过程中不同的副本同步的效率不尽相同,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO 为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset0至3之间的消息。
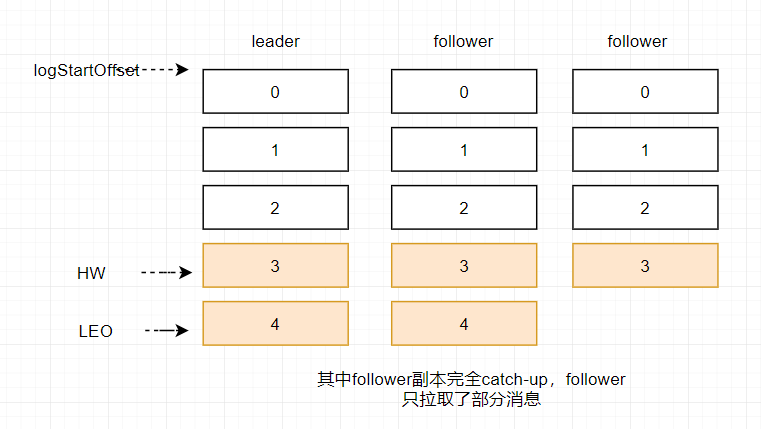
当所有副本都成功写入消息3和消息4之后,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
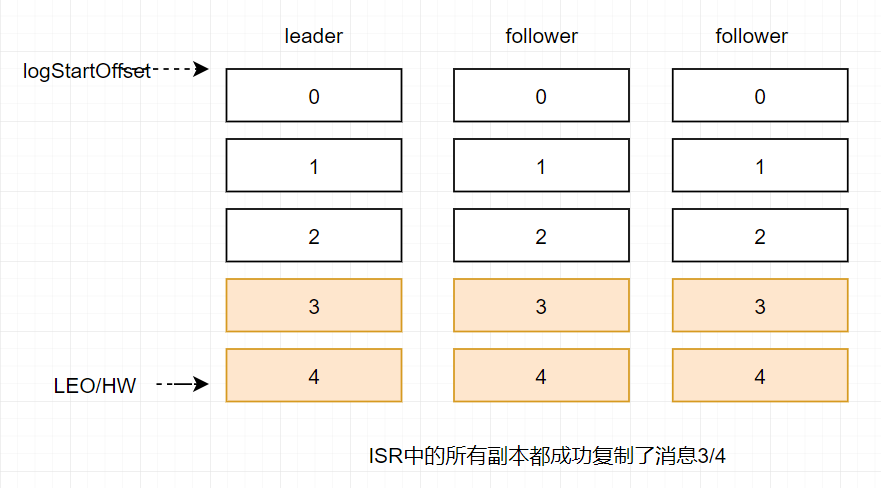
由此可见kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才会被确认已成功提交,这种复制方式极大的影响了性能。而在异步复制的方式下,follower副本异步的从leader副本中复制数据,数据只要被leader副本写入就会被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,然后leader副本宕机,则会造成数据丢失。kafka使用这种ISR的方式有效的权衡了数据可靠性和性能之间的关系。
Kafka中的HW、LEO、LSO等分别代表什么?的更多相关文章
- kafka中的offset概念
在 Kafka 中无论是 producer 往 topic 中写数据, 还是 consumer 从 topic 中读数据, 都避免不了和 offset 打交道, 关于 offset 主要有以下几个概念 ...
- kafka数据一致性(HW只能保证副本之间的数据一致性,并不能保证数据不丢失ack或者不重复。)
数据一致性问题:消费一致性和存储一致性 例如:一个leader 写入 10条数据,2个follower(都在ISR中),F1.F2都有可能被选为Leader,例如选F2 .后面Leader又活了.可能 ...
- kafka中server.properties配置文件参数说明
转自:http://blog.csdn.net/lizhitao/article/details/25667831 参数 说明(解释) broker.id =0 每一个broker在集群中的唯一表示, ...
- Kakfa揭秘 Day4 Kafka中分区深度解析
Kakfa揭秘 Day4 Kafka中分区深度解析 今天主要谈Kafka中的分区数和consumer中的并行度.从使用Kafka的角度说,这些都是至关重要的. 分区原则 Partition代表一个to ...
- kafka中处理超大消息的一些考虑
Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好(可参见LinkedIn的kafka性能测试).但有时候,我们需要处理更大的消息,比如XML文档或JSON内容,一个消息差不多 ...
- Kafka中操作topic时 Error:Failed to parse the broker info from zookeeper
Kafka中操作topic时 Error: Failed to parse the broker info from zookeeper 1.问题描述 2.问题原因 kafka在启动后 ...
- 使用Flink时从Kafka中读取Array[Byte]类型的Schema
使用Flink时,如果从Kafka中读取输入流,默认提供的是String类型的Schema: val myConsumer = new FlinkKafkaConsumer08[String](&qu ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
- Kafka中时间轮分析与Java实现
在Kafka中应用了大量的延迟操作但在Kafka中 并没用使用JDK自带的Timer或是DelayQueue用于延迟操作,而是使用自己开发的DelayedOperationPurgatory组件用于管 ...
随机推荐
- 使用arcpy添加grb2数据到镶嵌数据集中
#!coding: utf-8 import numpy as np import arcpy def addGRB2ToMosaic(grb2name): print "start add ...
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- 【git】【Idea】git刷新获取远程分支列表,可以在idea上看到最新的远程分支列表
[前提:本地项目是从GitLab或gitHub这些远程仓库上拉下来的 ,并且本地安装了git] ==================================================== ...
- Regex 常见语法
常用元字符 . 匹配除换行符以外的任意字符. \w 匹配字母或数字或下划线或汉字.\W 匹配任意不是字母,数字,下划线,汉字的字符. \s 匹配任意的空白符.\S 匹配任意不是空白符的字符.等价于 [ ...
- 我是如何一步步编码完成万仓网ERP系统的(八)产品库设计 4.品牌类别
https://www.cnblogs.com/smh188/p/11533668.html(我是如何一步步编码完成万仓网ERP系统的(一)系统架构) https://www.cnblogs.com/ ...
- 好用到哭!8个技巧让Vim菜鸟变专家
原文: https://juejin.im/post/5da68cb8f265da5b8c03c4a1 Vim只不过是一个文本编辑器,但如果你曾见过真正的高手是如何使用vim的,你就会知道,这个软件出 ...
- .Net IOC框架入门之——CastleWindsor
一.简介 Castle是.net平台上的一个开源项目,为企业级开发和WEB应用程序开发提供完整的服务,用于提供IOC的解决方案.IOC被称为控制反转或者依赖注入(Dependency Injectio ...
- Flask模板渲染
目录 Flask模板渲染 Jinja2模板引擎简介 模板 Jinja2 模板变量 变量 控制结构 宏,类似Python代码中的函数 模板继承 包含(Include) 过滤器 链式调用 常见内建过滤器 ...
- 记录前端开发vue常见问题,不断更新
1.点击刷新当天组件 1.可以在query中添加一个时间戳,缺点就是不好看 2.加一个重定向页面redirect页面,然后在beforecreate时this.$router.replace原路径 2 ...
- vue-cli的安装及版本查看更新
vue-cli安装 npm install vue-cli -g vue-cli的版本查看 vue -V vue-cli的3.0+以后使用的不是vue-cli了,如果用以上的安装命令安装的并不是最新版 ...