Kafka中的HW、LEO、LSO等分别代表什么?
HW 、 LEO 等概念和上一篇文章所说的 ISR有着紧密的关系,如果不了解 ISR 可以先看下ISR相关的介绍。
HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
下图表示一个日志文件,这个日志文件中只有9条消息,第一条消息的offset(LogStartOffset)为0,最有一条消息的offset为8,offset为9的消息使用虚线表示的,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。

LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。上图中offset为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的offset值加1.分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
下面具体分析一下 ISR 集合和 HW、LEO的关系。
假设某分区的 ISR 集合中有 3 个副本,即一个 leader 副本和 2 个 follower 副本,此时分区的 LEO 和 HW 都分别为 3 。消息3和消息4从生产者出发之后先被存入leader副本。
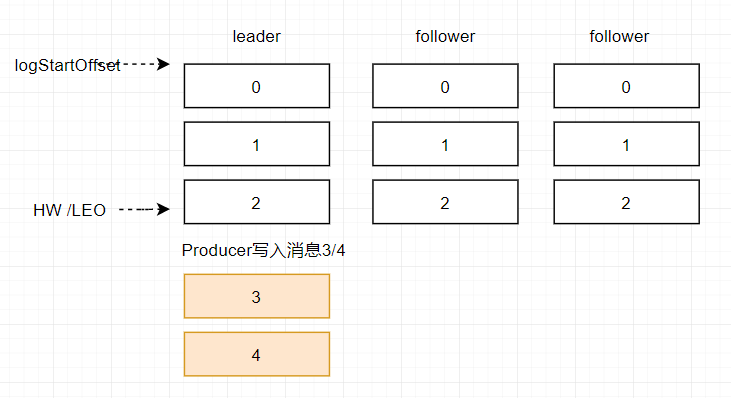
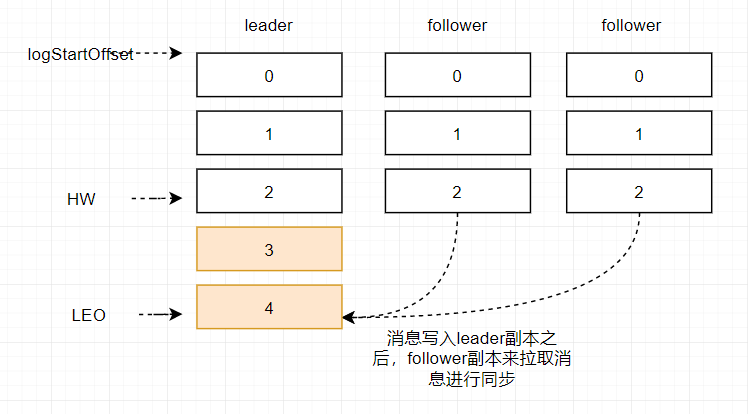
在消息被写入leader副本之后,follower副本会发送拉取请求来拉取消息3和消息4进行消息同步。
在同步过程中不同的副本同步的效率不尽相同,在某一时刻follower1完全跟上了leader副本而follower2只同步了消息3,如此leader副本的LEO为5,follower1的LEO为5,follower2的LEO 为4,那么当前分区的HW取最小值4,此时消费者可以消费到offset0至3之间的消息。
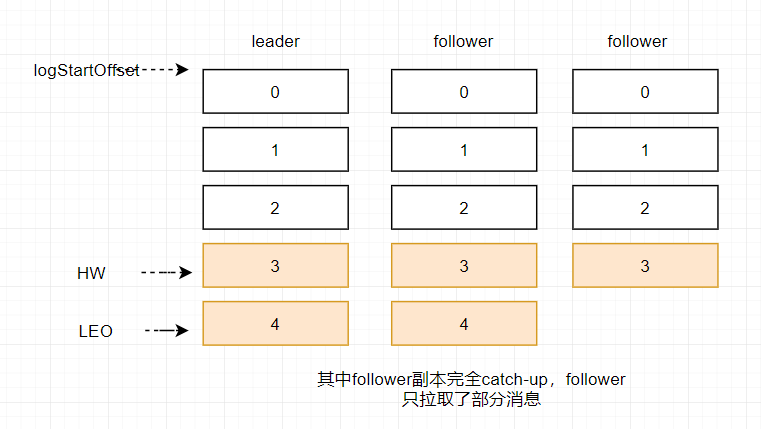
当所有副本都成功写入消息3和消息4之后,整个分区的HW和LEO都变为5,因此消费者可以消费到offset为4的消息了。
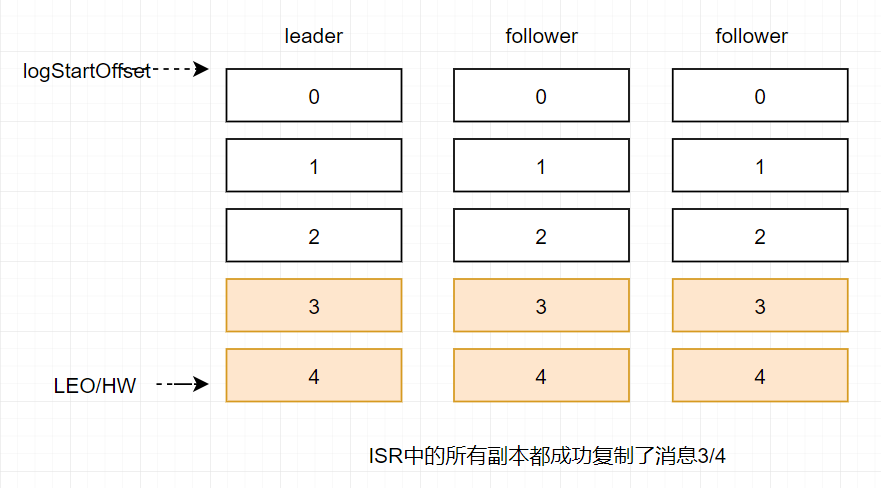
由此可见kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower副本都复制完,这条消息才会被确认已成功提交,这种复制方式极大的影响了性能。而在异步复制的方式下,follower副本异步的从leader副本中复制数据,数据只要被leader副本写入就会被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,然后leader副本宕机,则会造成数据丢失。kafka使用这种ISR的方式有效的权衡了数据可靠性和性能之间的关系。
Kafka中的HW、LEO、LSO等分别代表什么?的更多相关文章
- kafka中的offset概念
在 Kafka 中无论是 producer 往 topic 中写数据, 还是 consumer 从 topic 中读数据, 都避免不了和 offset 打交道, 关于 offset 主要有以下几个概念 ...
- kafka数据一致性(HW只能保证副本之间的数据一致性,并不能保证数据不丢失ack或者不重复。)
数据一致性问题:消费一致性和存储一致性 例如:一个leader 写入 10条数据,2个follower(都在ISR中),F1.F2都有可能被选为Leader,例如选F2 .后面Leader又活了.可能 ...
- kafka中server.properties配置文件参数说明
转自:http://blog.csdn.net/lizhitao/article/details/25667831 参数 说明(解释) broker.id =0 每一个broker在集群中的唯一表示, ...
- Kakfa揭秘 Day4 Kafka中分区深度解析
Kakfa揭秘 Day4 Kafka中分区深度解析 今天主要谈Kafka中的分区数和consumer中的并行度.从使用Kafka的角度说,这些都是至关重要的. 分区原则 Partition代表一个to ...
- kafka中处理超大消息的一些考虑
Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好(可参见LinkedIn的kafka性能测试).但有时候,我们需要处理更大的消息,比如XML文档或JSON内容,一个消息差不多 ...
- Kafka中操作topic时 Error:Failed to parse the broker info from zookeeper
Kafka中操作topic时 Error: Failed to parse the broker info from zookeeper 1.问题描述 2.问题原因 kafka在启动后 ...
- 使用Flink时从Kafka中读取Array[Byte]类型的Schema
使用Flink时,如果从Kafka中读取输入流,默认提供的是String类型的Schema: val myConsumer = new FlinkKafkaConsumer08[String](&qu ...
- Kafka生产者-向Kafka中写入数据
(1)生产者概览 (1)不同的应用场景对消息有不同的需求,即是否允许消息丢失.重复.延迟以及吞吐量的要求.不同场景对Kafka生产者的API使用和配置会有直接的影响. 例子1:信用卡事务处理系统,不允 ...
- Kafka中时间轮分析与Java实现
在Kafka中应用了大量的延迟操作但在Kafka中 并没用使用JDK自带的Timer或是DelayQueue用于延迟操作,而是使用自己开发的DelayedOperationPurgatory组件用于管 ...
随机推荐
- Hbase Filter之FilterList
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl/p/7098138.html 转载请注明出处 我们知道Hbase的Scan经常需要用到filter来过滤表中的数 ...
- 使用excel中的数据快速生成sql语句
在小公司的话,总是会有要开发去导入历史数据(数据从旧系统迁移到新系统上)的时候.这个时候,现场实施或客户会给你一份EXCEL文档,里面包含了一些别的系统上的历史数据,然后就让你导入到现在的系统上面去. ...
- Prometheus PromSQL 获取系统服务运行状态
Prometheus PromSQL 获取系统服务运行状态 使用systemd收集器:--collector.systemd.unit-whitelist=".+" 从system ...
- LinkedHashMap 的核心就 2 点,搞清楚,也就掌握了
HashMap 有一个不足之处就是在迭代元素时与插入顺序不一致.而大多数人都喜欢按顺序做某些事情,所以,LinkedHashMap 就是针对这一点对 HashMap 进行扩展,主要新增了「两种迭代方式 ...
- 七雄Q传封包辅助技术探讨回忆贴
前言 网页游戏2013年左右最火的类型最烧钱游戏,当年的我也掉坑了.为了边玩还满足码农精神我奋力的学习如何来做外挂.2013年我工作的第二个年头.多一半…介绍下游戏<七雄Q传>是北京游戏谷 ...
- sql脚本来获取数据库中的所有表结构了
sql脚本来获取数据库中的所有表结构了,代码如下: use AdventureWorks2008 go SELECT (case when a.colorder=1 then d.name else ...
- 实验吧——忘记密码了(vim备份文件,临时文件(交换文件))
题目地址:http://ctf5.shiyanbar.com/10/upload/step1.php 前些天突然发现个游戏,于是浪费了好多时间,终于还是忍住了,现在专心学习,从今天开始正式写些学习笔记 ...
- 面试官:优化代码中大量的if/else,你有什么方案?
一个快速迭代的项目,时间久了之后,代码中可能会充斥着大量的if/else,嵌套6.7层,一个函数几百行,简!直!看!死!人! 这个无限循环嵌套,只是总循环的一部分...我已经绕晕在黄桷湾立交 仔细数了 ...
- 【spring data jpa】带有条件的查询后分页和不带条件查询后分页实现
一.不带有动态条件的查询 分页的实现 实例代码: controller:返回的是Page<>对象 @Controller @RequestMapping(value = "/eg ...
- Django框架(十二)-- Djang与Ajax
一.什么是Ajax AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步Javascript和XML”.即使用Javascript语言与服务器进行异步交互,传 ...