机器学习笔记6:K-Means
目标函数
目标函数的表现函数
假设:点集合为D,所有分类的中心点解和为M,如下:
M=[\mu_1,\mu_2,...\mu_k] \\
\]
其中向量\(\bar{r}\),用来标识分类,如果点\(X_i\)离\(\mu_j\)最近,那么\(\bar{r}_i=(0,0,0...1....0)\),即第j位是1,其他位都是0.
\]
那么,K-mean的目标函数可以写为:
\]
针对u和r求解:
- 假定u已知,寻找最优的r,即找到每个点离哪个中心点最近;
- 假定r已知,寻找最优的u,即知道一群点的分类之后,找到每群点的中心点
- 将1、2步骤多循环几次求得最优解
最优解的表达式的意义:
- 说白了,假设有n个点,点i到其所属分类(假设分类编号为1到k)的中心点的距离为\(d_ik\),那么让n个\(d_ik\)加在一起的值最小,就是结果。
- K-means(K均值聚类算法),是一种迭代求解的聚类分析算法,就是把相似的成员弄到一起。
K-means聚类的形象化展示
素材引用自贪心学院:https://github.com/GreedyAIAcademy/Machine-Learning
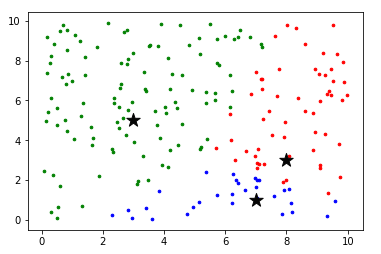
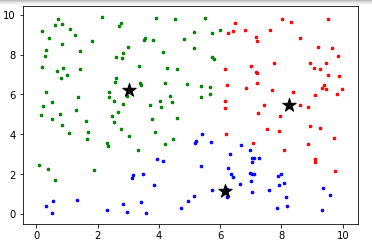
通俗地讲,就是先根据每个点距离哪个中心点最近就染成哪个中心点的颜色,然后再找到所有同一个颜色的点的中心点作为新的中心点,循环多次即得到想要的结果。
什么是K-means++呢?K-means++就是在最初取中心点的时候,让中心点的距离相对远一些,这样可以减小循环的次数。
聚类前
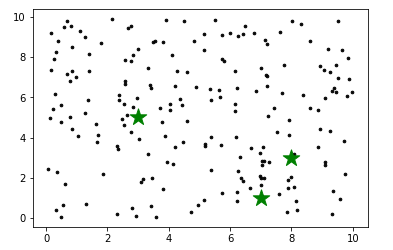
第一轮循环
第二轮循环
第三轮循环
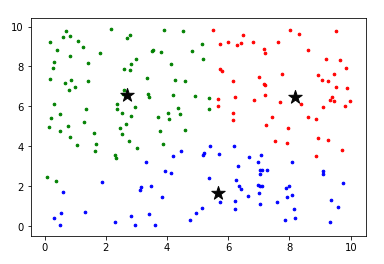
最终结果

演示代码:
# 导入相应的包
from copy import deepcopy
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 导入数据
data = pd.read_csv('data.csv')
print("Input Data and Shape")
print(data.shape)
data.head()
# 提取字段并可视化数据,使用scatter plot
f1 = data['V1'].values
f2 = data['V2'].values
X = np.random.random((200, 2))*10
plt.scatter(X[:,0], X[:,1], c='black', s=6)
# K-means里的K值
k = 3
# 随机初始化K个中心点,把结果存储在C
C_x = np.random.randint(0, np.max(X), size=k)
C_y = np.random.randint(0, np.max(X), size=k)
C = np.array(list(zip(C_x, C_y)), dtype=np.float32)
print("初始化之后的中心点:")
print(C)
# 把中心点也展示一下
plt.scatter(X[:,0], X[:,1], c='#050505', s=7)
plt.scatter(C[:,0], C[:,1], marker='*', s=300, c='g')
# 存储之前的中心点
C_old = np.zeros(C.shape)
clusters = np.zeros(len(X)) # K=3, clusters = [0,0,1,2,1,0]
def dist(a, b, ax=1):
return np.linalg.norm(a - b, axis=ax)
error = dist(C, C_old, None)
colors = ['r', 'g', 'b', 'y', 'c', 'm']
# 循环算法,直到收敛。收敛的条件就是,判断当前的中心点与之前的中心点之间有没有变化,没有变化距离就会变成0,然后抛出异常
while error != 0:
# Assigning each value to its closest cluster
for i in range(len(X)):
distances = dist(X[i], C)
cluster = np.argmin(distances)
clusters[i] = cluster
# 在计算新的中心点之前,先把旧的中心点存下来,以便计算距离
fig, ax = plt.subplots()
C_old = deepcopy(C)
for i in range(k):
points = np.array([X[j] for j in range(len(X)) if clusters[j] == i])
ax.scatter(points[:, 0], points[:, 1], s=7, c=colors[i])
ax.scatter(C_old[:, 0],C_old[:, 1], marker='*', s=200, c='#050505')
# 计算新的中心点
for i in range(k):
points = [X[j] for j in range(len(X)) if clusters[j] == i]
C[i] = np.mean(points, axis=0)
error = dist(C, C_old, None)
fig, ax = plt.subplots()
for i in range(k):
points = np.array([X[j] for j in range(len(X)) if clusters[j] == i])
ax.scatter(points[:, 0], points[:, 1], s=7, c=colors[i])
ax.scatter(C[:, 0], C[:, 1], marker='*', s=200, c='#050505')
关于K-means的几个问题
- 一定会收敛么?
答:一定会收敛,什么叫做收敛,当前后两次循环所计算出的中心点吻合时,我们就确定其为收敛。 - 不同初始化结果,会不会带来不一样的结果?
答: 会,因为K-means的函数是非凸函数,存在多个极值点,因此最终的结果有一定的随机性; - K-means的目标函数是什么?
答: 见上文第一章。 - K值如何选择?
答:超参,以K为横坐标,K-means的结果为纵坐标,得到一调递减的函数曲线,通过观察函数曲线在那个段放缓转变得最厉害,对应的横坐标就是哪个合适的K值。
可以做的事情
对用户进行分层
%matplotlib inline
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
data_offer = pd.read_excel("./WineKMC.xlsx", sheetname=0)
data_offer.columns = ["offer_id", "campaign", "varietal", "min_qty", "discount", "origin", "past_peak"]
data_offer.head()
data_transactions = pd.read_excel("./WineKMC.xlsx", sheetname=1)
data_transactions.columns = ["customer_name", "offer_id"]
data_transactions['n'] = 1
data_transactions.head()
import numpy as np
# 合并两个dataframe
cust_compare = data_transactions.merge(data_offer, on = 'offer_id')
#Drop unnecessary columns
cust_compare = cust_compare.drop(['campaign', 'varietal', 'min_qty', 'discount', 'origin', 'past_peak'], axis = 1)
#Create pivot table
table = pd.pivot_table(cust_compare, index = 'customer_name', columns = 'offer_id', aggfunc=np.sum, fill_value = 0)
table
#offers = table.columns.get_level_values('offer_id')
#x_cols = np.matrix(offers)
SS = []
from sklearn.cluster import KMeans
for K in range(2, 20):
kmeans = KMeans(n_clusters = K).fit(table) #Using all default values from method
SS.append(kmeans.inertia_)
plt.plot(range(2,20), SS);
plt.xlabel('K');
plt.ylabel('SS');
结果:
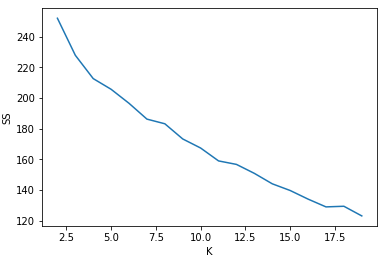
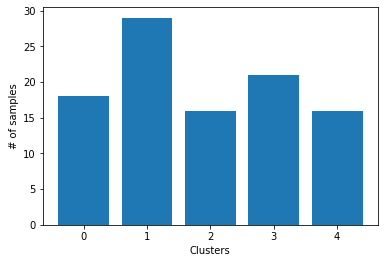
#Choosing K=5
kmeans_5 = KMeans(n_clusters = 5).fit_predict(table)
points = list(kmeans_5)
d = {x:points.count(x) for x in points}
heights = list(d.values())
plt.bar(range(5),heights)
plt.xlabel('Clusters')
plt.ylabel('# of samples')
结果:
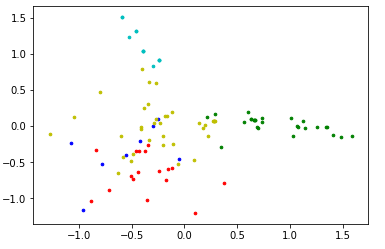
利用降维的方法使数据可视化
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
data_new = pca.fit_transform(table)
print(table.shape)
print(data_new.shape)
colors = ['r', 'g', 'b', 'y', 'c', 'm']
fig, ax = plt.subplots()
for i in range(5):
points = np.array([data_new[j] for j in range(len(data_new)) if kmeans_5[j] == i])
ax.scatter(points[:, 0], points[:, 1], s=7, c=colors[i])
结果:
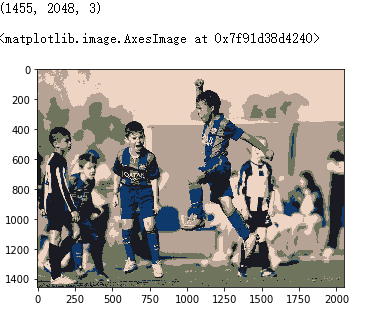
图像处理
1. 代码
from pylab import imread,imshow,figure,show,subplot
from numpy import reshape,uint8,flipud
from sklearn.cluster import KMeans
from copy import deepcopy
img = imread('sample.jpeg') # img: 图片的数据
pixel = reshape(img,(img.shape[0]*img.shape[1],3))
pixel_new = deepcopy(pixel)
print (img.shape)
model = KMeans(n_clusters=5)
labels = model.fit_predict(pixel)
palette = model.cluster_centers_
for i in range(len(pixel)):
pixel_new[i,:] = palette[labels[i]]
imshow(reshape(pixel_new, (img.shape[0], img.shape[1],3)))
2. 解释
第一步:用像素shape[0]*shape[1]来对每个像素点进行标号;
第二步:将描述每个像素点的RGB值作为一个向量(x,y,z),相当与把颜色值当成了一个立体坐标内的点了;
第三步:对像素点的颜色值进行归类,将所有像素点的颜色值替换为其中心点的颜色值
第四步:根据之前的标号生成图片并显示
3. 结果
机器学习笔记6:K-Means的更多相关文章
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- 【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)
原文链接:https://blog.csdn.net/gwplovekimi/article/details/80288964 本博文为逻辑斯特回归的学习笔记.由于仅仅是学习笔记,水平有限,还望广大读 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- Python机器学习笔记:SVM(1)——SVM概述
前言 整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思 ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
随机推荐
- token的验证过程
1.用户向服务器发送用户名和密码. 2.服务端收到请求,验证用户名和密码. 3.验证成功后,服务端会签发一个token,并将这个token发送到客户端. 4.客户端收到token后将token存储起来 ...
- 【转】30种MySQL索引优化的方法
第一方面:30种mysql优化sql语句查询的方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by涉及的列上建立索引. 2.应尽量避免在 where ...
- 内置函数、反射、__str__、__del__、元类
一.内置函数的补充 isinstance(obj,cls)检查是否obj是否是类 cls 的对象 class Foo: pass obj=Foo() print(isinstance(obj,Foo) ...
- 有趣的js代码
for ( ; ; ) { window.alert(" ∧_∧ ババババ\n( ・ω・)=つ≡つ\n(っ ≡つ=つ\n`/ )\n(ノΠU\n何回閉じても無駄ですよ-ww\nm9(^Д^) ...
- python总结三
1.线性表若采用链式存储结构的时候,要求内存中可用存储单位的地址是:连续或者不连续都可以 链式存储去找后继节点或者前驱节点是使用指针来实现的,不需要连续的内存,当然,也可以是连续的内存地址 2. 线性 ...
- nginx配置神器
原文 https://mp.weixin.qq.com/s/zFEk7XzHj3xPReDXEnQxcQ https://nginxconfig.io/ Nginx作为一个轻量级的HTTP服务器,相比 ...
- Windows远程桌面连接Debian
参考 https://portal.databasemart.com/kb/a457/how-to-install-desktop-environment-and-xrdp-service-in-de ...
- JAVA数学函数与常量
在JAVA中,没有幂运算,因此需要借助于Math类的pow方法. double y = Math.pow(x,a) Math类提供了一些常用的三角函数: Math.sin Math.cos Math. ...
- linux 远程文件复制和拉取
基本命令格式 上传 scp -r myfilder tiantian@192.168.168.221:/home/tiantian/temp/ 复制本地文件到远程/home/tiantian/te ...
- sql优化(原理,方法,特点,实例)
整理的有点多,做好心理准备...... 1.资源优化理解: 不同设备,io不同.每种设备都有两个指标:延时(响应时间):表示硬件的突发处理能力:带宽(吞吐量):代表硬件持续处理能力. 每种硬件主要的工 ...