elasticsearch插入索引文档 对数字字符串的处理
对于字符串在搜索匹配的时候,字符串是数字的话需要匹配的是精准匹配,如果是部分匹配字符串的话,需要进行处理,把数字型字符串作为一个字符中的数组表示插入之后显示如下:
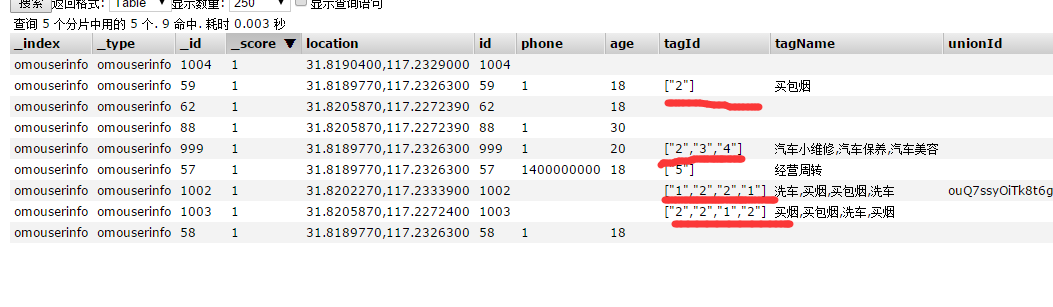
如果插入之后显示如画线部分的话,则表示精准匹配
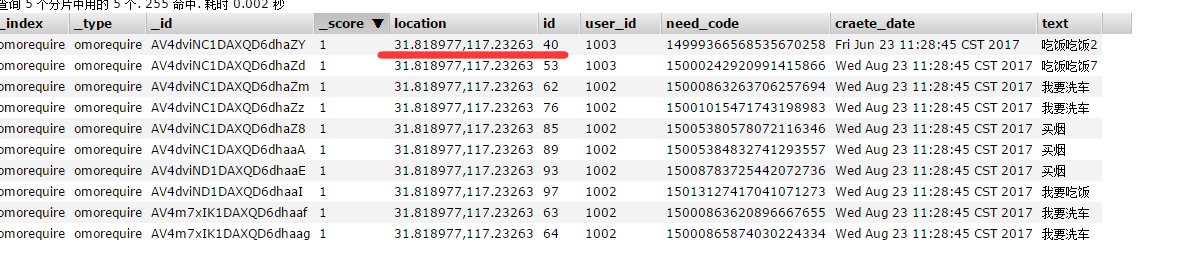
在用clien的java api插入的时候:
String json=null;
if (req.getTagId() != null) {
String[] test = req.getTagId().split(",");
json = JSON.toJSONString(test);
System.out.println(json);
}else {
json = "{"+"\"location\":"+"\""+req.getLatitude()+","+req.getLongitude()+"\""+","
+"\"id\":"+"\""+req.getId()+"\""+","+"\"union_id\":"+"\""+req.getUnionId()+"\""+","
+"\"tag_id\":"+"\""+req.getTagId()+"\""+","+"\"tag_name\":"+"\""+req.getTagName()+"\""+","
+"\"nickname\":"+"\""+req.getNickname()+"\""+","+"\"phone\":"+"\""+req.getPhone()+"\""+","
+"\"name\":"+"\""+req.getName()+"\""+","+"\"age\":"+"\""+req.getAge()+"\""+","
+"\"code\":"+"\""+req.getCode()+"\""+","+"\"gender\":"+"\""+req.getGender()+"\""+","
+"\"province\":"+"\""+req.getProvince()+"\""+","+"\"city\":"+"\""+req.getCity()+"\""+","
+"\"coountry\":"+"\""+req.getCountry()+"\""+","+"\"avatarUrl\":"+"\""+req.getAvatarUrl()+"\""+","
+"\"app_code\":"+"\""+req.getAppCode()+"\""+"}";
System.out.println(json);
}
通过这种插入方式,默认的是json,在json验证的时候显示的json,而在table格式下不能显示:因此通过类的字符形式插入在显示table格式:
public boolean insertIndexUserDoc(String indexname, String type,List<UserEntity> list)
throws ApplicationException, Exception {
// TODO Auto-generated method stub
String location=null;
JestClient jestHttpClient = Connection.getClient();
JestResult jr = null;
try {
// Bulk.Builder bulk = new Bulk.Builder().defaultIndex(indexname)
// .defaultType(type);
for(UserEntity req:list){
UserEntity user = new UserEntity();
user.setId(req.getId());
user.setUnionId(req.getUnionId());
user.setTagName(req.getTagName());
user.setLocation(req.getLatitude().toString()+","+req.getLongitude().toString());
user.setAge(req.getAge());
user.setPhone(req.getPhone());
user.setCode(req.getCode());
user.setGender(req.getGender());
user.setProvince(req.getProvince());
user.setCity(req.getCity());
user.setCountry(req.getCountry());
user.setAppCode(req.getAppCode());
user.setAvatarUrl(req.getAvatarUrl());
user.setNickname(req.getNickname());
if (req.getTagId()!=null){
String[] mids=req.getTagId().split(",");
user.setTagId(JSON.toJSONString(mids));;
}
jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());
boolean flag = jr.isSucceeded();
System.out.println(flag);
}
return true;
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return false;
}
}
其中, jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());这个设置的id,如果不设置,在批量插入处理的时候,id第一次自动分配,后面容易冲突
第一段
代码如果批量插入时候可以不设置id,由于id可以在一次之后自增id,不需要设置id;因此,在批量单条处理的时候需要加id。执行之后如下:
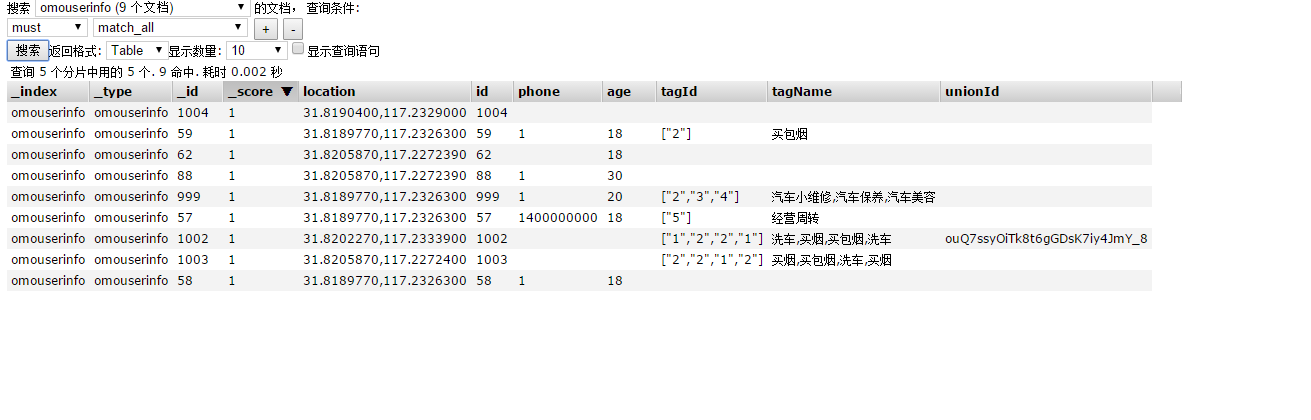
在查询的时候实现精准匹配:

做查询的时候需要对字符串进行处理如下:
ublic static void main(String[] args) {
int from = 0, size = 100;
String serviceTypeIds = "823,770,1182,1431,1432";
System.out.println(serviceTypeIds);
StringBuilder stringBuilder = new StringBuilder("{")
.append("\"from\":")
.append(from)
.append(",")
.append("\"size\":")
.append(size)
.append(",")
.append("\"query\" : {")
.append("\"match_all\" : {}")
.append("},")
.append("\"filter\" : {\"and\" : [")
.append(org.apache.commons.lang3.StringUtils
.isBlank(serviceTypeIds) ? "" : (serviceTypeIds
.contains(",") ? "{\"query_string\" : {\"query\" : \""
+ StringUtils.replace(serviceTypeIds, ",", " or ")
+ "\",\"fields\":[\"tagId\"]}}"
: "{\"term\" : {\"tagId\" : " + serviceTypeIds
+ "}},"));
System.out.println(stringBuilder);
}
花了一上午的时间,做出来,小小激动一下啊!
打印出来的json如下:
{
"from": 0,
"size": 100,
"query": {
"match_all": {}
},
"filter": {
"query_string": {
"query": "2 or1 ",
"fields": [
"tagId"
]
}
}
}
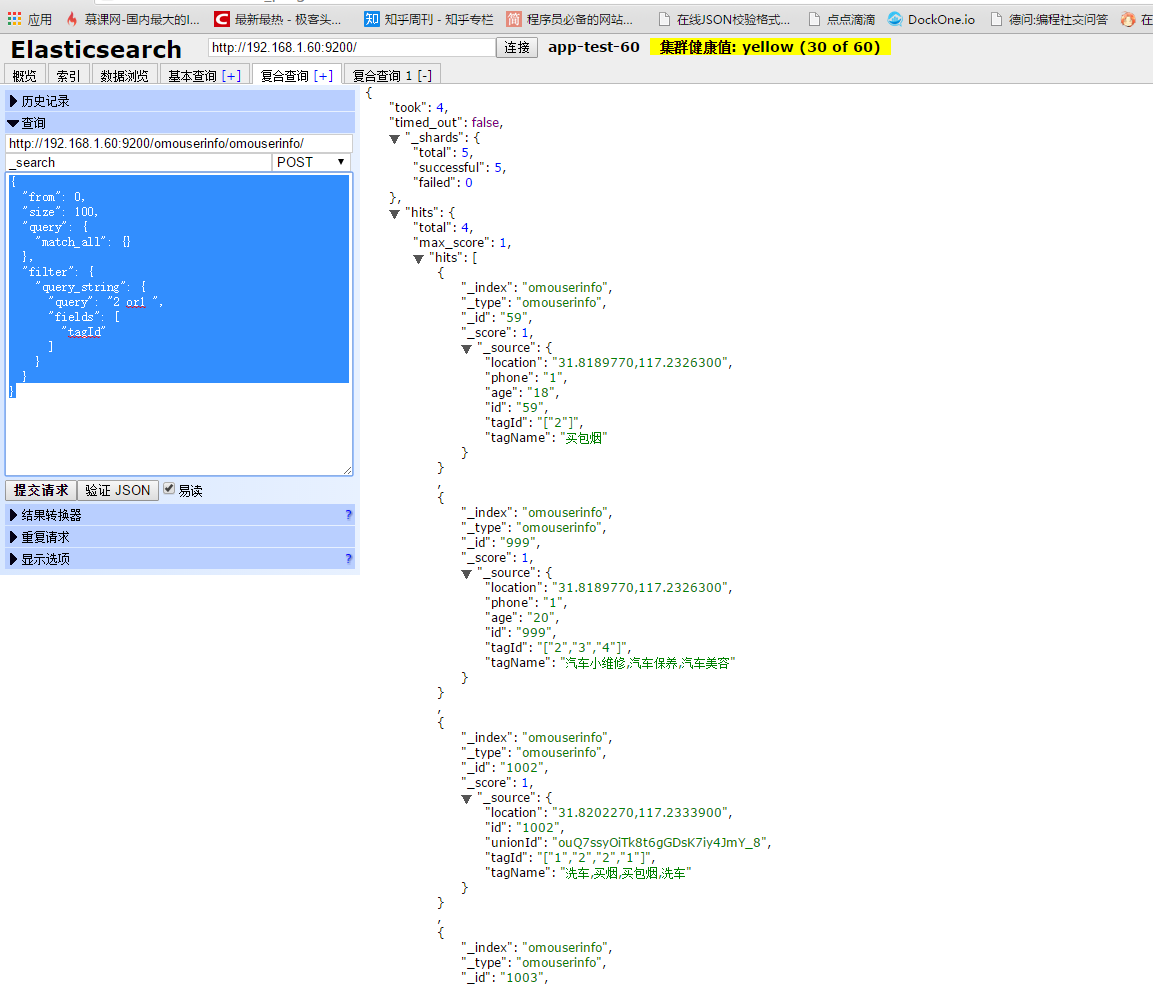
查询结果如下:
elasticsearch插入索引文档 对数字字符串的处理的更多相关文章
- 关于Elasticsearch单个索引文档最大数量问题
因为ElasticSearch是一个基于Lucene的搜索服务器.Lucene的索引有个难以克服的限制,导致Elasticsearch的单个分片存在最大文档数量限制,一个索引分片的最大文档数量是20亿 ...
- Elasticsearch必知必会的干货知识一:ES索引文档的CRUD
若在传统DBMS 关系型数据库中查询海量数据,特别是模糊查询,一般我们都是使用like %查询的值%,但这样会导致无法应用索引,从而形成全表扫描效率低下,即使是在有索引的字段精确值查找,面对海量数 ...
- 分布式搜索elasticsearch 索引文档的增删改查 入门
1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演示,实际上内部调用的RESTful接口. RESTful接口URL的格式: http://localhost:9200/ ...
- head插件对elasticsearch 索引文档的增删改查
1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演示,实际上内部调用的RESTful接口. RESTful接口URL的格式: http://localhost:9200 ...
- Elasticsearch 索引文档的增删改查
利用Elasticsearch-head可以在界面上(http://127.0.0.1:9100/)对索引进行增删改查 1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演 ...
- 详细描述一下 Elasticsearch 索引文档的过程 ?
面试官:想了解 ES 的底层原理,不再只关注业务层面了. 解答: 这里的索引文档应该理解为文档写入 ES,创建索引的过程. 文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流 ...
- 详细描述一下 Elasticsearch 索引文档的过程 ?
这里的索引文档应该理解为文档写入 ES,创建索引的过程. 文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程. 记住官方文档中的这个图. 第一步:客户写集群某节点写入数据, ...
- elasticsearch 官方监控文档 老版但很有用
https://zhaoyanblog.com/page/1?s=elasticsearch 监控每个节点(jvm部分) 操作系统和进程部分 操作系统和进程部分的含义是很清楚的,这里不会描述的很详细. ...
- Elasticsearch 7.x文档基本操作(CRUD)
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html 1.添加文档 1.1.指定文档ID PUT ...
随机推荐
- [Selenium] WebDriver 操作 HTML5 中的 video
测试播放,停止播放 http://www.videojs.com/ 示例: package com.learningselenium.html5; import static org.junit.As ...
- BZOJ3996 线性代数
题目:http://www.lydsy.com/JudgeOnline/problem.php?id=3996 转化题目给的条件 $$D = \sum_{i=1}^n \sum_{j=1}^n{A(i ...
- Collection View Programming Guide for iOS---(二)----Collection View Basics
Collection View Basics Collection View 基础 To present its content onscreen, a collection view coope ...
- 如何开始学习Go语言
除了Java.Python和JavaScript之外,如果要开始学习一门新语言的话,我想应该是Go! Go语言正在被越来越多的公司使用.我们公司的后端服务已经全面采用Go语言实现了. 最开始接触Go语 ...
- SCUT - 261 - 对称与反对称 - 构造 - 简单数论
https://scut.online/p/261 由于M不是质数,要用扩展欧几里得求逆元,而不是费马小定理! 由于M不是质数,要用扩展欧几里得求逆元,而不是费马小定理! 由于M不是质数,要用扩展欧几 ...
- 51nod 1094 【水题】
暴力即可!!! #include <stdio.h> #include <string.h> #include <iostream> using namespace ...
- bzoj 1003: [ZJOI2006]物流运输【spfa+dp】
预处理出ans[i][j]为i到j时间的最短路,设f[i]为到i时间的最小代价,转移显然就是 f[i]=min(f[j-1]+ans[j][i]*(i-j+1)+k); #include<ios ...
- IT兄弟连 JavaWeb教程 Servlet
Servlet的定义 Java Servlet是运行在Web服务器或应用服务器上的程序,它是作为来自Web浏览器或其他HTTP客户端的请求和HTTP服务器上的数据库或应用程序之间的中间层. 使用Ser ...
- Django学习:ORM
Object Relational Mapping(ORM) ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据 ...
- vlc media player
还是很好用的目前来看 倍速播放: [ 减速播放 ] 加速播放 = 恢复原速度