elasticsearch插入索引文档 对数字字符串的处理
对于字符串在搜索匹配的时候,字符串是数字的话需要匹配的是精准匹配,如果是部分匹配字符串的话,需要进行处理,把数字型字符串作为一个字符中的数组表示插入之后显示如下:
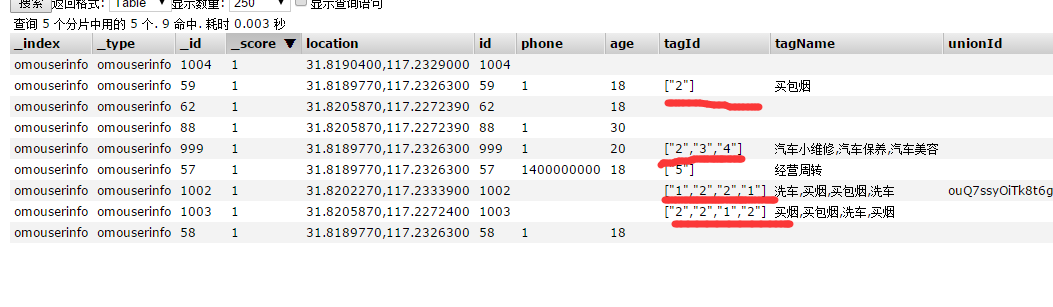
如果插入之后显示如画线部分的话,则表示精准匹配
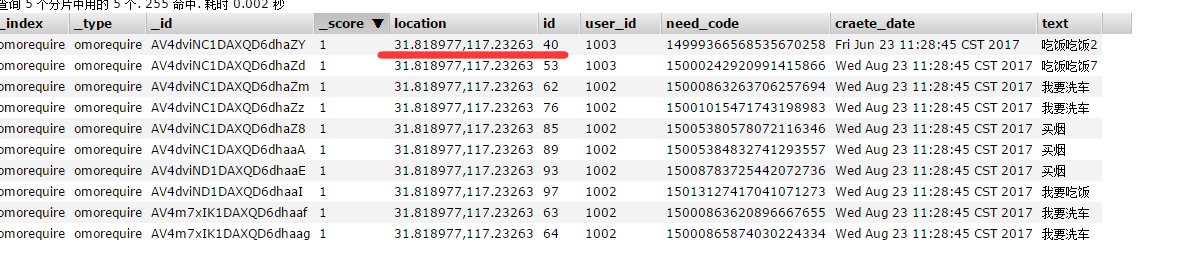
在用clien的java api插入的时候:
String json=null;
if (req.getTagId() != null) {
String[] test = req.getTagId().split(",");
json = JSON.toJSONString(test);
System.out.println(json);
}else {
json = "{"+"\"location\":"+"\""+req.getLatitude()+","+req.getLongitude()+"\""+","
+"\"id\":"+"\""+req.getId()+"\""+","+"\"union_id\":"+"\""+req.getUnionId()+"\""+","
+"\"tag_id\":"+"\""+req.getTagId()+"\""+","+"\"tag_name\":"+"\""+req.getTagName()+"\""+","
+"\"nickname\":"+"\""+req.getNickname()+"\""+","+"\"phone\":"+"\""+req.getPhone()+"\""+","
+"\"name\":"+"\""+req.getName()+"\""+","+"\"age\":"+"\""+req.getAge()+"\""+","
+"\"code\":"+"\""+req.getCode()+"\""+","+"\"gender\":"+"\""+req.getGender()+"\""+","
+"\"province\":"+"\""+req.getProvince()+"\""+","+"\"city\":"+"\""+req.getCity()+"\""+","
+"\"coountry\":"+"\""+req.getCountry()+"\""+","+"\"avatarUrl\":"+"\""+req.getAvatarUrl()+"\""+","
+"\"app_code\":"+"\""+req.getAppCode()+"\""+"}";
System.out.println(json);
}
通过这种插入方式,默认的是json,在json验证的时候显示的json,而在table格式下不能显示:因此通过类的字符形式插入在显示table格式:
public boolean insertIndexUserDoc(String indexname, String type,List<UserEntity> list)
throws ApplicationException, Exception {
// TODO Auto-generated method stub
String location=null;
JestClient jestHttpClient = Connection.getClient();
JestResult jr = null;
try {
// Bulk.Builder bulk = new Bulk.Builder().defaultIndex(indexname)
// .defaultType(type);
for(UserEntity req:list){
UserEntity user = new UserEntity();
user.setId(req.getId());
user.setUnionId(req.getUnionId());
user.setTagName(req.getTagName());
user.setLocation(req.getLatitude().toString()+","+req.getLongitude().toString());
user.setAge(req.getAge());
user.setPhone(req.getPhone());
user.setCode(req.getCode());
user.setGender(req.getGender());
user.setProvince(req.getProvince());
user.setCity(req.getCity());
user.setCountry(req.getCountry());
user.setAppCode(req.getAppCode());
user.setAvatarUrl(req.getAvatarUrl());
user.setNickname(req.getNickname());
if (req.getTagId()!=null){
String[] mids=req.getTagId().split(",");
user.setTagId(JSON.toJSONString(mids));;
}
jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());
boolean flag = jr.isSucceeded();
System.out.println(flag);
}
return true;
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return false;
}
}
其中, jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());这个设置的id,如果不设置,在批量插入处理的时候,id第一次自动分配,后面容易冲突
第一段
代码如果批量插入时候可以不设置id,由于id可以在一次之后自增id,不需要设置id;因此,在批量单条处理的时候需要加id。执行之后如下:
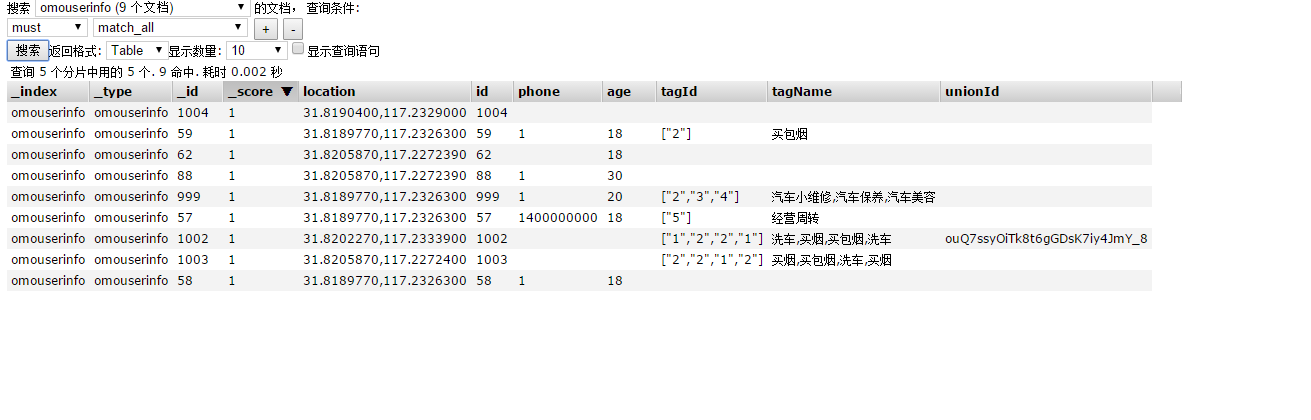
在查询的时候实现精准匹配:

做查询的时候需要对字符串进行处理如下:
ublic static void main(String[] args) {
int from = 0, size = 100;
String serviceTypeIds = "823,770,1182,1431,1432";
System.out.println(serviceTypeIds);
StringBuilder stringBuilder = new StringBuilder("{")
.append("\"from\":")
.append(from)
.append(",")
.append("\"size\":")
.append(size)
.append(",")
.append("\"query\" : {")
.append("\"match_all\" : {}")
.append("},")
.append("\"filter\" : {\"and\" : [")
.append(org.apache.commons.lang3.StringUtils
.isBlank(serviceTypeIds) ? "" : (serviceTypeIds
.contains(",") ? "{\"query_string\" : {\"query\" : \""
+ StringUtils.replace(serviceTypeIds, ",", " or ")
+ "\",\"fields\":[\"tagId\"]}}"
: "{\"term\" : {\"tagId\" : " + serviceTypeIds
+ "}},"));
System.out.println(stringBuilder);
}
花了一上午的时间,做出来,小小激动一下啊!
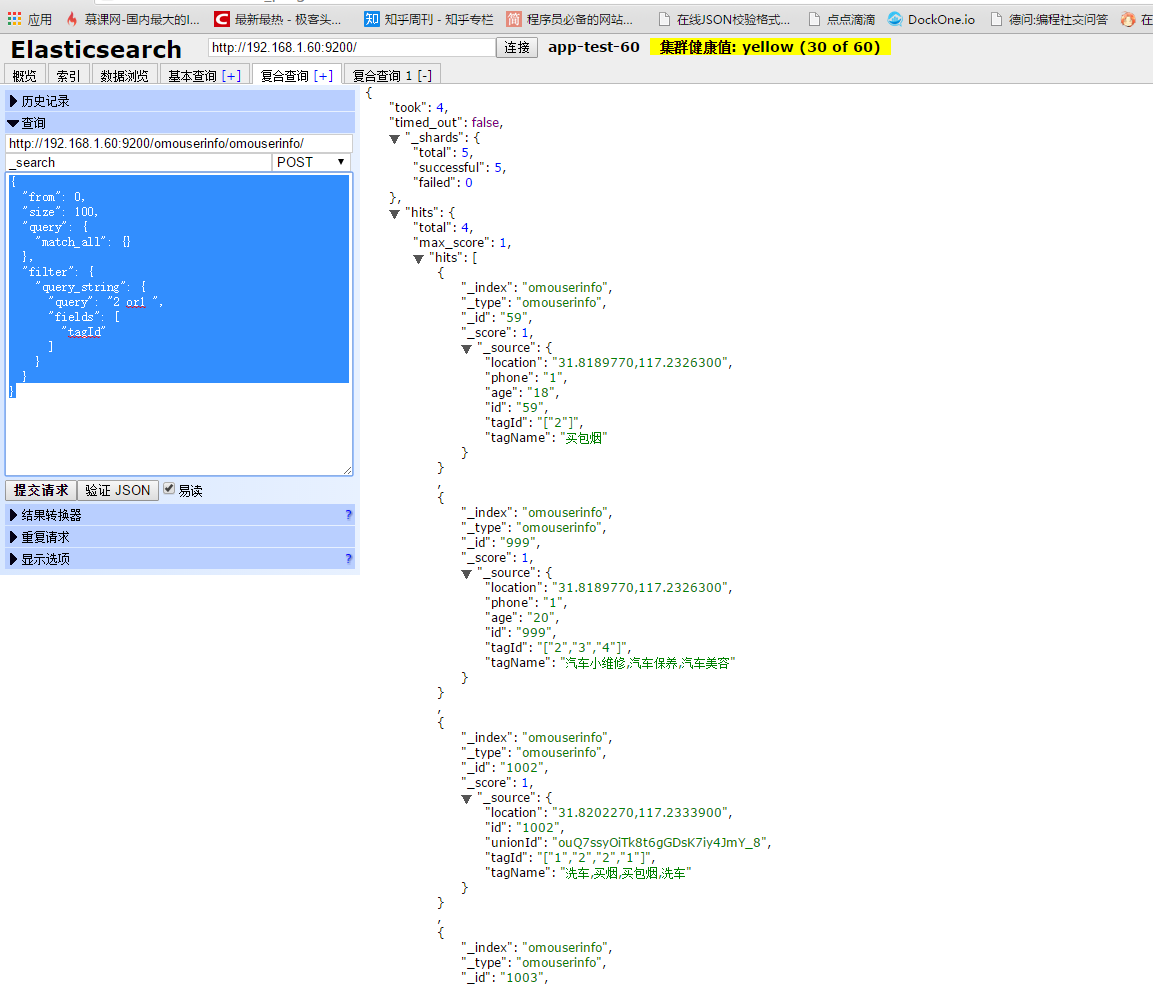
打印出来的json如下:
{
"from": 0,
"size": 100,
"query": {
"match_all": {}
},
"filter": {
"query_string": {
"query": "2 or1 ",
"fields": [
"tagId"
]
}
}
}
查询结果如下:
elasticsearch插入索引文档 对数字字符串的处理的更多相关文章
- 关于Elasticsearch单个索引文档最大数量问题
因为ElasticSearch是一个基于Lucene的搜索服务器.Lucene的索引有个难以克服的限制,导致Elasticsearch的单个分片存在最大文档数量限制,一个索引分片的最大文档数量是20亿 ...
- Elasticsearch必知必会的干货知识一:ES索引文档的CRUD
若在传统DBMS 关系型数据库中查询海量数据,特别是模糊查询,一般我们都是使用like %查询的值%,但这样会导致无法应用索引,从而形成全表扫描效率低下,即使是在有索引的字段精确值查找,面对海量数 ...
- 分布式搜索elasticsearch 索引文档的增删改查 入门
1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演示,实际上内部调用的RESTful接口. RESTful接口URL的格式: http://localhost:9200/ ...
- head插件对elasticsearch 索引文档的增删改查
1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演示,实际上内部调用的RESTful接口. RESTful接口URL的格式: http://localhost:9200 ...
- Elasticsearch 索引文档的增删改查
利用Elasticsearch-head可以在界面上(http://127.0.0.1:9100/)对索引进行增删改查 1.RESTful接口使用方法 为了方便直观我们使用Head插件提供的接口进行演 ...
- 详细描述一下 Elasticsearch 索引文档的过程 ?
面试官:想了解 ES 的底层原理,不再只关注业务层面了. 解答: 这里的索引文档应该理解为文档写入 ES,创建索引的过程. 文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流 ...
- 详细描述一下 Elasticsearch 索引文档的过程 ?
这里的索引文档应该理解为文档写入 ES,创建索引的过程. 文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程. 记住官方文档中的这个图. 第一步:客户写集群某节点写入数据, ...
- elasticsearch 官方监控文档 老版但很有用
https://zhaoyanblog.com/page/1?s=elasticsearch 监控每个节点(jvm部分) 操作系统和进程部分 操作系统和进程部分的含义是很清楚的,这里不会描述的很详细. ...
- Elasticsearch 7.x文档基本操作(CRUD)
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html 1.添加文档 1.1.指定文档ID PUT ...
随机推荐
- 安装YCM出现:YouCompleteMe unavailable no module named frozendict或者 YouCompleteMe unavailable no module named future
参考博文:http://blog.sina.com.cn/s/blog_8f70642d0102wo57.html 原因就是你或者没用Vundle安装,或者Vundle由于网速太慢下载到一半不能把安装 ...
- Objective-C Runtime(一)预备知识
很早就知道了Objective-C Runtime这个概念,「Objective-C奇技淫巧」「iOS黑魔法」各种看起来很屌的主题中总会有它的身影:但一直没有深入去学习,一来觉得目前在实际项目中还没有 ...
- Watir 能够为你做什么?
为了提高自己的工作效率,我曾经对Watir进行了系统性的学习,比起学习C++, Java等始终不得门,Watir还是学进去了,能够完整搭建出一个自己很容易理解的自动化架构. 之后我想继续在自动化测试方 ...
- 使用Cocos2dx-JS开发一个飞行射击游戏
一.前言 笔者闲来无事,某天github闲逛,看到了游戏引擎的专题,引起了自己的兴趣,于是就自己捣腾了一下Cocos2dx-JS.由于是学习,所谓纸上得来终觉浅,只是看文档看sample看demo,并 ...
- MariaDB + Visual Studio 2017 环境下的 ODBC 入门开发
参考: Easysoft公司提供的ODBC教程 微软提供的ODBC文档 环境: Windows 10 x64 1803 MariaDB TX 10.2.14 x64 MariaDB ODBC Conn ...
- 在头文件#pragma comment(lib,"glaux.lib");编译器提示waring C4081: 应输入“newline“
在头文件#pragma comment(lib,"glaux.lib");编译器提示waring C4081: 应输入“newline“ #行不能加分号的
- Linux入侵检测工具
原文:https://www.cnblogs.com/lvcisco/p/4045203.html 一.rootkit简介 rootkit是Linux平台下最常见的一种木马后门工具,它主要通过替换系统 ...
- E20170403-gg
thumbnail 缩略图 inherit vt. 继承; vt. 经遗传获得(品质.身体特征等),继任; opacity 不透明度 flat adj. 平的; 单调的; 不景气的 ...
- POJ3250【单调栈】
思路: 维护一个单调递增的栈,对于栈顶元素<=新值来说,那么后面的,我一定看不到了,pop掉以后,那么这时候的栈的大小就是我能看到的这个刚刚pop出去元素的个数. //#include < ...
- 51nod 1003【数学】
思路: 2和5能构成0,然后就是看2和5因子组成个数,然而我们知道,1-n中2的因子数肯定>5的,所以我们只要求一下1-n中5的因子个数就好了... #include <stdio.h&g ...