在Hadoop上运行基于RMM中文分词算法的MapReduce程序
原文:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-count-on-hadoop/
在Hadoop上运行基于RMM中文分词算法的MapReduce程序
我知道这个文章标题很“学术”化,很俗,让人看起来是一篇很牛B或者很装逼的论文!其实不然,只是一份普通的实验报告,同时本文也不对RMM中文分词算法进行研究。这个实验报告是我做高性能计算课程的实验里提交的。所以,下面的内容是从我的实验报告里摘录出来的,当作是我学习hadoop分享出来的一些个人经验。
实验目标
学习编写 Hadoop 上的 MapReduce 程序。
使用 Hadoop 分布式计算小说《倚天屠龙记》里的中文单词频率,比较张无忌身边的两个女人周芷若与赵敏谁在小说里的热度高。(为什么要提到倚天屠龙记呢?因为我的一位舍友最近把贾静雯演的这部戏看完了,他无时无刻不提到贾静雯演的赵敏,所以这个实验也取材自我的大学生活……)
实验原理
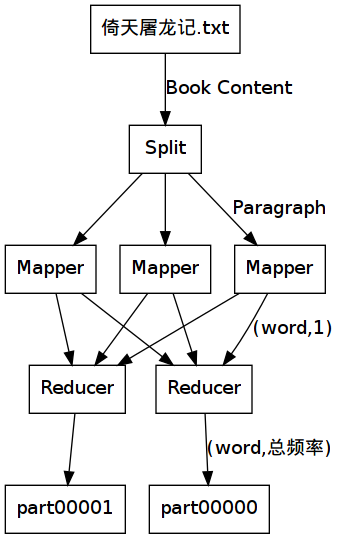
通过自学Hadoop的Streaming工作模式,使用Streaming可以让Hadoop运行非Java的MapReduce程序。
为了减少我们的实验时间,我们使用了以开发效率著名的Python语言来编写我们的mapper.py和reducer.py。其中,我们还使用到了一个小巧的中文分词模块smallseg.py,引用自(http://code.google.com/p/smallseg/,Apache License 2.0)。
对于中文词库,我们使用搜狗实验室提供的中文词库main.dic以及一个字库suffix.dic,均可从smallseg项目中获得。
分布式计算的输入为一个文本文件:倚天屠龙记.txt,我们从网下下载此文本资源,并且转换为utf8文本编码以方便我们在Linux下进行分词计算。
iconv -fgbk -tutf8 倚天屠龙记.txt > 倚天屠龙记utf8.txt
实验环境
NameNode:
OS: Ubuntu11.04
CPU: Intel Core I3
Memory: 512MB
IP: 125.216.244.28
DataNode1:
OS: Ubuntu11.10
CPU: Intel Pentium 4
Memory: 512MB
IP: 125.216.244.21
DataNode2:
OS: Ubuntu11.10
CPU: Intel Pentium 4
Memory: 512MB
IP: 125.216.244.22
Mapper程序
下面是mapper.py的代码。
- #!/usr/bin/env python
- from smallseg import SEG
- import sys
- seg = SEG()
- for line in sys.stdin:
- wlist = seg.cut(line.strip())
- for word in wlist:
- try:
- print "%s\t1" % (word.encode("utf8"))
- except:
- pass
smallseg为一个使用RMM字符串分割算法的中文分词模块。Mapper程序的过程很简单,对每一行的中文内容进行分词,然后把结果以单词和频率的格式输出。对于所有的中文单词,都是下面的格式,
单词[tab]1
每个单词的频率都为1。Mapper并不统计每一行里的单词出现频率,我们把这个统计频率的工作交给Reducer程序。
Reducer程序
下面是reducer.py的代码.
- #!/usr/bin/env python
- import sys
- current_word,current_count,word = None, 1, None
- for line in sys.stdin:
- try:
- line = line.rstrip()
- word, count = line.split("\t", 1)
- count = int(count)
- except: continue
- if current_word == word:
- current_count += count
- else:
- if current_word:
- print "%s\t%u" % (current_word, current_count)
- current_count, current_word = count, word
- if current_word == word:
- print "%s\t%u" % (current_word, current_count)
从标准输入中读取每一个单词频率,并且统计。因为这些单词已经由Hadoop为我们排好了顺序,所以我们只需要对一个单词的出现次数进行累加,当出现不同的单词的时候,我们就输出这个单词的频率,格式如下
单词[tab]频率
实验步骤
实验使用一个NameNode节点和两个DataNode节点。
首先,把所需要的文件复制到每一台主机上。这些文件都放在/home/hadoop/wc目录下。
scp -r wc hadoop@125.216.244.21:.
scp -r wc hadoop@125.216.244.22:.
scp -r wc hadoop@125.216.244.28:.
运行Hadoop Job
本次任务,使用3个Mapper进程以及2个Reducer进程。因为分词的步骤最为耗时,所以我们尽量分配最多数目的Mapper进程。
hadoop@xiaoxia-vz:~/hadoop-0.20.203.0$ ./bin/hadoop jar contrib/streaming/hadoop-streaming-0.20.203.0.jar -mapper /home/hadoop/wc/mapper.py -reducer /home/hadoop/wc/reducer.py -input 2-in -output 2-out -jobconf mapred.map.tasks=3 -jobconf mapred.reduce.tasks=2
[...] WARN streaming.StreamJob: -jobconf option is deprecated, please use -D instead.
packageJobJar: [/tmp/hadoop-unjar2897218480344074444/] [] /tmp/streamjob7946660914041373523.jar tmpDir=null
[...] INFO mapred.FileInputFormat: Total input paths to process : 1
[...] INFO streaming.StreamJob: getLocalDirs(): [/tmp/mapred/local]
[...] INFO streaming.StreamJob: Running job: job_201112041409_0005
[...] INFO streaming.StreamJob: To kill this job, run:
[...] INFO streaming.StreamJob: /home/hadoop/hadoop-0.20.203.0/bin/../bin/hadoop job -Dmapred.job.tracker=http://125.216.244.28:9001 -kill job_201112041409_0005
[...] INFO streaming.StreamJob: Tracking URL: http://localhost:50030/jobdetails.jsp?jobid=job_201112041409_0005
[...] INFO streaming.StreamJob: map 0% reduce 0%
[...] INFO streaming.StreamJob: map 9% reduce 0%
[...] INFO streaming.StreamJob: map 40% reduce 0%
[…] INFO streaming.StreamJob: map 67% reduce 12%
[...] INFO streaming.StreamJob: map 71% reduce 22%
[...] INFO streaming.StreamJob: map 100% reduce 28%
[...] INFO streaming.StreamJob: map 100% reduce 100%
[...] INFO streaming.StreamJob: Job complete: job_201112041409_0005
[...] INFO streaming.StreamJob: Output: 2-out
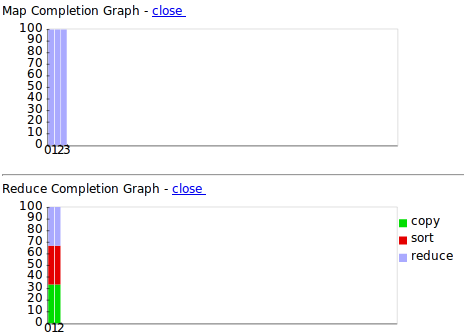
Map过程耗时:41s
Reduce过程耗时:21s
总耗时:62s
计算结果
复制计算结果到本地文件系统。
./bin/hadoop dfs -get 2-out/part* ../wc/
查看part*的部分内容:
hadoop@xiaoxia-vz:~/wc$ tail part-00000
龙的 1
龙眼 1
龙虎 2
龙被 1
龙身 2
龙镇 1
龙骨 1
龟寿 2
龟山 1
龟裂 1
hadoop@xiaoxia-vz:~/wc$ tail part-00001
龙门 85
龙飞凤舞 1
龙驾 1
龟 3
龟一 1
龟二 1
龟息 1
龟缩 1
龟蛇 3
下面,对输出的结果进行合并,并按照频率进行排序。该过程比较快,在1秒内就已经完成。
hadoop@xiaoxia-vz:~/wc$ cat part-00000 part-00001 | sort -rnk2,2 > sorted
hadoop@xiaoxia-vz:~/wc$ head sorted
的 7157
张无忌 4373
是 4199
道 3465
了 3187
我 2516
他 2454
你 2318
这 1991
那 1776
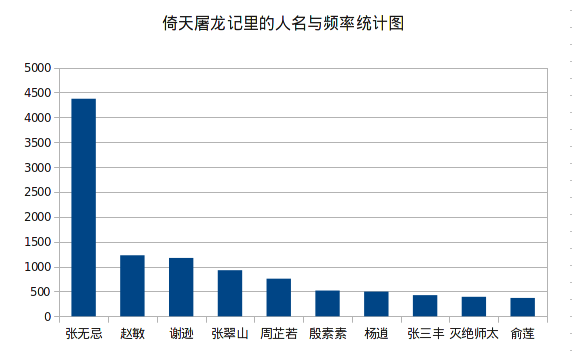
我们去掉单个字的干扰,因为我们的实验目的只对人名感兴趣。
hadoop@xiaoxia-vz:~/wc$ cat sorted | awk '{if(length($1)>=4) print $0}' | head -n 50
张无忌 4373
说道 1584
赵敏 1227
谢逊 1173
自己 1115
甚么 1034
张翠山 926
武功 867
一个 777
咱们 767
周芷若 756
教主 739
笑道 693
明教 685
一声 670
听得 634
姑娘 612
师父 606
只见 590
无忌 576
少林 555
如此 547
弟子 537
之中 527
殷素素 518
杨逍 496
他们 490
不知 484
如何 466
我们 453
两人 453
叫道 450
二人 445
今日 443
心想 433
张三丰 425
声道 425
义父 412
出来 402
虽然 395
灭绝师太 392
之下 389
这时 381
莲舟 374
心中 374
便是 371
不敢 371
俞莲 369
不能 359
身子 356统计图表
结论
赵敏以1227票的频率完胜周芷若的756票,由此可知赵敏在《倚天屠龙记》里的热度比周芷若高。
经过本次实验,我们对 Hadoop 原理有了一定程度的了解,并且顺利的完成Mapper函数和Reducer函数的设计和测试。能够运用 Hadoop 进行简单的并行计算的实现。我们也对并行算法和串行算法的区别和设计有了更深一层的了解。此外,实验还增进了我们的合作精神,提高了我们的动手能力。
在Hadoop上运行基于RMM中文分词算法的MapReduce程序的更多相关文章
- Mmseg中文分词算法解析
Mmseg中文分词算法解析 @author linjiexing 开发中文搜索和中文词库语义自己主动识别的时候,我採用都是基于mmseg中文分词算法开发的Jcseg开源project.使用场景涉及搜索 ...
- 利用Mahout实现在Hadoop上运行K-Means算法
利用Mahout实现在Hadoop上运行K-Means算法 一.介绍Mahout Mahout是Apache下的开源机器学习软件包,目前实现的机器学习算法主要包含有协同过滤/推荐引擎,聚类和分类三个部 ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 中文分词算法之最大正向匹配算法(Python版)
最大匹配算法是自然语言处理中的中文匹配算法中最基础的算法,分为正向和逆向,原理都是一样的. 正向最大匹配算法,故名思意,从左向右扫描寻找词的最大匹配. 首先我们可以规定一个词的最大长度,每次扫描的时候 ...
- 原生态在Hadoop上运行Java程序
第一种:原生态运行jar包1,利用eclipse编写Map-Reduce方法,一般引入Hadoop-core-1.1.2.jar.注意这里eclipse里没有安装hadoop的插件,只是引入其匝包,该 ...
- 基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试
做过搜索的同学都知道,分词的好坏直接决定了搜索的质量,在英文中分词比中文要简单,因为英文是一个个单词通过空格来划分每个词的,而中文都一个个句子,单独一个汉字没有任何意义,必须联系前后文字才能正确表达它 ...
- 分词 | 双向匹配中文分词算法python实现
本次实验内容是基于词典的双向匹配算法的中文分词算法的实现.使用正向和反向最大匹配算法对给定句子进行分词,对得到的结果进行比较,从而决定正确的分词方法. 算法描述正向最大匹配算法先设定扫描的窗口大小ma ...
- Docker在Linux上运行NetCore系列(五)更新应用程序
转发请注明此文章作者与路径,请尊重原著,违者必究. 本篇文章与其它系列文章不同,为了方便测试,新建了一个ASP.Net Core视图应用. 备注:下面说的应用,只是在容器中运行的应用程序. 查看现在运 ...
- 关于运行“基于极限学习机ELM的人脸识别程序”代码犯下的一些错误
代码来源 基于极限学习机ELM的人脸识别程序 感谢文章主的分享 我的环境是 win10 anaconda Command line client (version 1.6.5)(conda 4.3.3 ...
随机推荐
- python list的应用
先看下面的操作 In [2]: lis = [(1,2),(3,4),(5,6)] In [3]: for a,b in lis: ...: if a == 1: ...: print (" ...
- [ 原创 ] Java基础8--什么叫做重载
重载是在同一个类中,有多个方法名相同,参数列表不同(参数个数不同,参数类型不同),与方法的返回值无关,与权限修饰符无关,B中的参数列表和题目的方法完全一样了.
- 【CF540D】 D. Bad Luck Island (概率DP)
D. Bad Luck Island time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- Codeforces Round #351 (VK Cup 2016 Round 3, Div. 2 Edition) C. Bear and Colors 暴力
C. Bear and Colors 题目连接: http://www.codeforces.com/contest/673/problem/C Description Bear Limak has ...
- php 获取所有常量
有的时候想得到某个完整路径,看看都定义了哪些常量,可以这样做,即把所有的常量都打印出来,然后看看有没有自己想要的,感觉挺方便 官方给的原型: array get_defined_constants ( ...
- 读书笔记_Effective_C++_条款三十五:考虑virtual函数以外的其他选择
举书上的例子,考虑一个virtual函数的应用实例: class GameCharacter { private: int BaseHealth; public: virtual int GetHea ...
- Windows下openssl安装及使用
配置过程中需要生成一些mak文件,这些生成代码用perl脚本生成,所以要安装一个ActivePerl. 网址: http://www.activestate.com/activeperl/ 下载后直接 ...
- [置顶] Spring的自动装配
采用构造函数注入,以及setter方法注入都需要写大量的XML配置文件,这时可以采用另一种方式,就是自动装,由Spring来给我们自动装配我们的Bean. Spring提供了四种自动装配类型 1:By ...
- android四大组件--ContentProvider具体解释
一.相关ContentProvider概念解析: 1.ContentProvider简单介绍 在Android官方指出的Android的数据存储方式总共同拥有五种,各自是:Shared Prefere ...
- ibatis实战之中的一个对多关联
在实际开发中,我们经常遇到关联数据的情况,如User对象拥有若干Book对象 每一个Book对象描写叙述了归属于一个User信息,这样的情况下,我们应该怎样处理? 通过单独的Statement操作固然 ...