SqlAlchemy操作(二)
SQLALchemy初始化链接数据库
1. 数据库配置.
https://www.cnblogs.com/mengbin0546/p/10124560.html
2. python端操作.
一、 代码:
from django.shortcuts import render # Create your views here. from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy import Column
from sqlalchemy.types import String,Integer
from sqlalchemy.ext.declarative import declarative_base #创建数据库连接,max_overflow 指定最大连接数.
engine =create_engine("mysql+pymysql://root:123456@132.232.55.209:3306/db1",) DBSession =sessionmaker(engine) #创建DBSession类型 session =DBSession()#创建session对象. BaseModel=declarative_base()#创建对象的基类. class User(BaseModel): #定义User对象
__tablename__ ="user1" #创建表,指定表名称.
#指定表结构
id = Column(String(10),primary_key=True)
username =Column(String(10),index=True) # class Session(BaseModel):
# __tablename__ ="session1"
# id =Column(String(10),primary_key=True)
# user =Column(String(10),index=True)
# ip =Column(String(10)) # 创建表,执行所有BaseModel类的子类create_all,进行创建表
# BaseModel.metadata.create_all(engine) # 删除表,执行drop_all 方法进行删除表.
BaseModel.metadata.drop_all(engine) session.commit() #提交
执行后在数据库中查看:
MariaDB [db1]> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| mengbin |
| session |
| users |
+---------------+
3 rows in set (0.00 sec)
二、数据库增删改查.
#1. 增加
# (方法一)
# user_obj =User(id =1,username ="wupeiqi")
# session.add(user_obj)
# session.commit() #(方法二)
# session.add_all([User(id =3,username="san"),
# User(id =4,username="si"),
# ])
# session.commit() #2.删除.
# session.query(User).filter(User.id >=3).delete()
# session.commit() #3.修改
session.query(User).filter(User.id ==1).update({"username" :"helloworld"})
session.commit() #4.查询.
obj = session.query(User).filter(User.id==1)
print("obj",obj)
obj1= session.query(User).filter(User.id>=1).all()
print("obj1",obj1)
for i in obj1:
print(i.username) 4.查询结果: obj SELECT user1.id AS user1_id, user1.username AS user1_username FROM user1 WHERE user1.id = %(id_1)s
obj1 [<__main__.User object at 0x00000065D55BC278>, <__main__.User object at 0x00000065D55BC2E8>, <__main__.User object at 0x00000065D55BC358>]
三、ORM操作数据库,通过delect执行sql语句.
from sqlalchemy import create_engine
#创建引擎
engine = create_engine("mysql+pymysql://root:dadmin01@127.0.0.1:3306/meng", max_overflow=5)
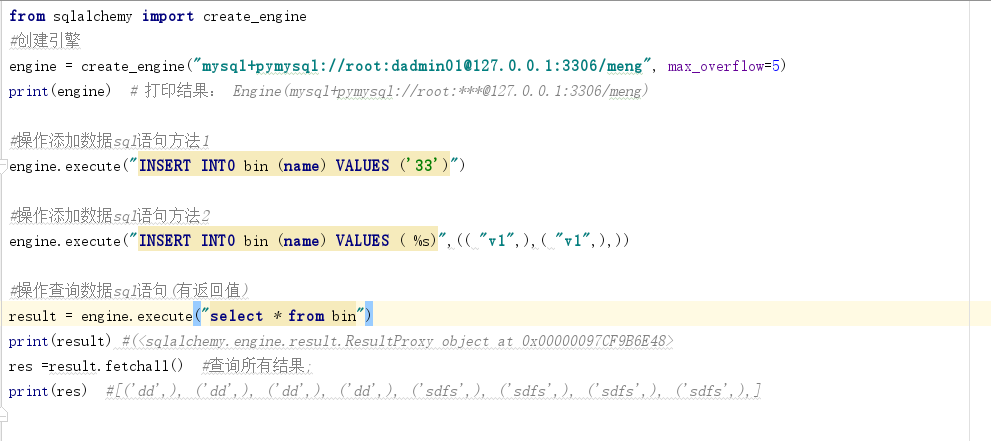
print(engine) # 打印结果: Engine(mysql+pymysql://root:***@127.0.0.1:3306/meng) #操作添加数据sql语句方法1
engine.execute("INSERT INTO bin (name) VALUES ('33')") #操作添加数据sql语句方法2
engine.execute("INSERT INTO bin (name) VALUES ( %s)",(( "v1",),( "v1",),)) #操作查询数据sql语句(有返回值)
result = engine.execute("select * from bin")
print(result) #(<sqlalchemy.engine.result.ResultProxy object at 0x00000097CF9B6E48>
res =result.fetchall() #查询所有结果;
print(res) #[('dd',), ('dd',), ('dd',), ('dd',), ('sdfs',), ('sdfs',), ('sdfs',), ('sdfs',),]
四、使用__repr__定义返回的数据
class TableTest(BaseModel):
__tablename__ ="tabletest"
nid = Column(Integer,primary_key=True,autoincrement=True)
name =Column(String(10),nullable=False)
role =Column(Integer) def __repr__(self):
output ="(%s,%s,)"%(self.nid,self.name)
return output #创建表,执行所有BaseModel类的子类,进行创建表
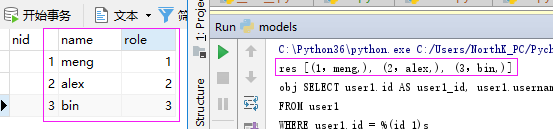
BaseModel.metadata.create_all(engine) res =session.query(TableTest).all() print("res",res)
SqlAlchemy操作(二)的更多相关文章
- flask 操作mysql的两种方式-sqlalchemy操作
flask 操作mysql的两种方式-sqlalchemy操作 二.ORM sqlalchemy操作 #coding=utf-8 # model.py from app import db class ...
- Python之Mysql及SQLAlchemy操作总结
一.Mysql命令总结 1.创建库 create database test1; 2.授权一个用户 grant all privileges on *.* to 'feng'@'%' identifi ...
- {MySQL的库、表的详细操作}一 库操作 二 表操作 三 行操作
MySQL的库.表的详细操作 MySQL数据库 本节目录 一 库操作 二 表操作 三 行操作 一 库操作 1.创建数据库 1.1 语法 CREATE DATABASE 数据库名 charset utf ...
- Python3.x:SQLAlchemy操作数据库
Python3.x:SQLAlchemy操作数据库 前言 SQLAlchemy是一个ORM框架(Object Rational Mapping,对象关系映射),它可以帮助我们更加优雅.更加高效的实现数 ...
- GIS基础软件及操作(二)
原文 GIS基础软件及操作(二) 练习二.管理地理空间数据库 1.利用ArcCatalog 管理地理空间数据库 2.在ArcMap中编辑属性数据 第1步 启动 ArcCatalog 打开一个地理数据库 ...
- 百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(二) -- 多表查询
MySQL行(记录)的操作(二) -- 多表查询 数据的准备 #建表 create table department( id int, name varchar(20) ); create table ...
- PHP操作 二维数组模拟mysql函数
PHP操作 二维数组模拟mysql函数<pre>public function monimysqltest(){ $testarray=array( array('ss'=>'1', ...
- JNI操作二维数组
之前的文章讲解了有关JNI使用方法,这篇文章进阶一点,介绍下JNI操作二维数组的方法.有了之前文章的操作JNI的方法,这里直接上代码了. Java代码部分 package com.testjni; p ...
- SQLAlchemy(二):SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
随机推荐
- 基于udp的套接字
1 ss = socket() #创建一个服务器的套接字 2 ss.bind() #绑定服务器套接字 3 inf_loop: #服务器无限循环 4 cs = ss.recvfrom()/ss.send ...
- 从输入url到显示网页发生了什么
原文链接:https://juejin.im/post/5bf23afa6fb9a049be5d1494 在浏览器中输入url到显示网页主要包含两个部分: 网络通信和页面渲染 互联网内各网络设备间的通 ...
- Loadrunner12.5-录制http://www.gw.com.cn/网页时提示“SSL身份验证失败”错误,这是为什么呢?
问题:LR产品,录制http://www.gw.com.cn/ 网页时提示下图错误,这是为什么呢? 请在如下recording options中选择正确的SSL版本,再进行录制. 注:如何确定那个SS ...
- PAT 1070 结绳(25)(代码)
1070 结绳(25 分) 给定一段一段的绳子,你需要把它们串成一条绳.每次串连的时候,是把两段绳子对折,再如下图所示套接在一起.这样得到的绳子又被当成是另一段绳子,可以再次对折去跟另一段绳子串连.每 ...
- PAT 1044 火星数字(20)(思路+代码)
1044 火星数字(20)(20 分) 火星人是以13进制计数的: 地球人的0被火星人称为tret. 地球人数字1到12的火星文分别为:jan, feb, mar, apr, may, jun, jl ...
- Codeforces 689B. Mike and Shortcuts SPFA/搜索
B. Mike and Shortcuts time limit per test: 3 seconds memory limit per test: 256 megabytes input: sta ...
- linq 使用or构建动态查询
You can certainly do it within a Where clause (extension method). If you need to build a complex que ...
- 【Win】使用ScreenToGif制作gif动态图片
ScreenToGif 经常要写各类教程,有时候需要制作一些演示动画,GIF动画图片是个不错的选择,ScreenToGif是一款GIF录屏软件,下载地址可自行百度. 运行环境 操作系统:windows ...
- hdu-2955(01背包+逆向思维+审题)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2955 思路:注意p和m[i]是被抓的概率,不能直接用,要转换为逃跑的概率,然后将得到的钱视为背包体积再 ...
- UVa 12034 Race (递推+组合数学)
题意:A,B两个人比赛,名次有三种情况(并列第一,AB,BA).输入n,求n个人比赛时最后名次的可能数. 析:本来以为是数学题,排列组合,后来怎么想也不对.原来这是一个递推... 设n个人时答案为f( ...