A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问
这是我最近看到的一篇论文,思路还是很清晰的,就是改进的LPA算法。改进的地方在两个方面:
(1)结合K-shell算法计算量了节点重重要度NI(node importance),标签更新顺序则按照NI由大到小的顺序更新
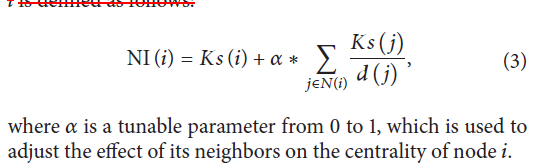
得到ks值后,载计算一下节点邻居ks值和度值d的比值
(2)当出现次数最多的标签不止一个时,再计算一下标签重要度LI(label importance)

其实就是找到节点相同标签的那些令居计算一个合值,看着也不难啊
(3)最后这个算法使用的是异步传播
下面是我实现的代码
function Labelnew=NIBlpa(A,alpha)
% A Node Influence Based Label Propagation Algorithm for
% Community Detection in Networks
% [X,Y,Z] = NIBlpa(A,alpha)
%
% Inputs:
% k - clique size
% A - adjacency matrix
%
% Outputs:
% X - detected communities
% Y - all cliques (i.e. complete subgraphs that are not parts of larger
% complete subgraphs)
% Z - k-clique matrix
%
% Author : Yang Yang
% Email : bethansy@yahoo.com
ks=kshell(A);
n=size(A,1);
D=sum(A,2);
NI=ks;
label = 1:size(A,2);
%%
% calculate NI(node importance)
for i=1:n
Nei=find(A(i,:)==1);
NI(i,2)=ks(i,2)+alpha*sum(ks(Nei,2)./D(Nei));
end
sequence=sortrows(NI,-2);
%%
% Label propagation
Label1 = label;
Labelnew = Label1; while(1)
for i=1:n
% 找到邻居下标对应的标签
nb_lables = Labelnew(A(sequence(i,1),:)==1);
% 只考虑了每个节点至少有一个邻居,如果有孤立节点程序不运行保持原标签
if size(nb_lables,2)>0
x = HistRate(nb_lables);
max_nb_labels = x(x(:,2)==max(x(:,2)),1);
if size(max_nb_labels)==1
Labelnew(sequence(i,1))= max_nb_labels;
else
LI=zeros(length(max_nb_labels),1);
for ma=1:length(max_nb_labels)
Nei=find(A(sequence(i),:));
index=Labelnew(Nei)==max_nb_labels(ma);
LI(ma)=sum(NI(Nei(index),2)./D(Nei(index)));
end
[~,maxx]=max(LI);
Labelnew(sequence(i,1))=max_nb_labels(maxx);
end
end end
% 收敛条件,预防跳跃
if Labelnew==Label1
break;
else
Label1 = Labelnew; end
end
下面是调用K-shell算法的代码
function [kvalue]=kshell(A)
% A :邻接矩阵
% A=load('cdbBA_4000_5_0_.txt');
%
n=size(A,1);
kvalue=zeros(n,2);
kvalue(:,1)=[1:n]';
if find(sum(A,2)==0)
kvalue(sum(A,2)==0,2)=0;
end
a=1;k=1;
% 一层循环主要是叫K-shell中k值,当层层剥掉节点度k的节点后,将这些节点边删除,当网络中不再有小于等于k的节点后,k=k+1
while a
D=sum(A,2);
if sum(D)==0
break;
end
b=1;
% 二层循环主要是找到k层的所有节点
while b
index=find(D<=k&D>0);
if isempty(index)
b=0;continue;
else
A(index,:)=0;
A(:,index)=0;
D=sum(A,2);
kvalue(index,2)=k;
end
end
k=k+1;
end
end
但是后在几个数据集上测试效果都非常不好,例如karate上nmi只有0.2多,但是论文中作者得到的结果却是1,我已经把文章看了几遍还是找不出算法和作者哪里有出入,不过发现改进(2)的公式是错误的源头?抓头???其指教
2017.6.15 更新:用这个代码在人工网络上测试,结果和论文中有是一样的了。但是在实际网络karate、dolphin、football中结果和作者给出的结果相差很大。不知道为什么?
A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问的更多相关文章
- LabelRank非重叠社区发现算法介绍及代码实现(A Stabilized Label Propagation Algorithm for Community Detection in Networks)
最近在研究基于标签传播的社区分类,LabelRank算法基于标签传播和马尔科夫随机游走思路上改装的算法,引用率较高,打算将代码实现,便于加深理解. 这个算法和Label Propagation 算法不 ...
- SLAP(Speaker-Listener Label Propagation Algorithm)社区发现算法
其中部分转载的社区发现SLPA算法文章 一.概念 社区(community)定义:同一社区内的节点与节点之间关系紧密,而社区与社区之间的关系稀疏. 设图G=G(V,E),所谓社区发现是指在图G中确定n ...
- 标签传播算法(Label Propagation Algorithm, LPA)初探
0. 社区划分简介 0x1:非重叠社区划分方法 在一个网络里面,每一个样本只能是属于一个社区的,那么这样的问题就称为非重叠社区划分. 在非重叠社区划分算法里面,有很多的方法: 1. 基于模块度优化的社 ...
- Label Propagation Algorithm LPA 标签传播算法解析及matlab代码实现
转载请注明出处:http://www.cnblogs.com/bethansy/p/6953625.html LPA算法的思路: 首先每个节点有一个自己特有的标签,节点会选择自己邻居中出现次数最多的标 ...
- VIPS: a VIsion based Page Segmentation Algorithm
VIPS: a VIsion based Page Segmentation Algorithm VIPS: a VIsion based Page Segmentation Algorithm In ...
- 标签传播算法(Label Propagation)及Python实现
众所周知,机器学习可以大体分为三大类:监督学习.非监督学习和半监督学习.监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到数据的分布,以期对未来没有见到的 ...
- Affinity Propagation Algorithm
The principle of Affinity Propagation Algorithm is discribed at above. It is widly applied in many f ...
- 论文笔记之:Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013
Dynamic Label Propagation for Semi-supervised Multi-class Multi-label Classification ICCV 2013 在基于Gr ...
- TOTP:Time-based One-time Password Algorithm(基于时间的一次性密码算法)
TOTP:Time-based One-time Password Algorithm(基于时间的一次性密码算法) TOTP - Time-based One-time Password Algori ...
随机推荐
- nodejs的优点
nodejs主要用于搭建高性能的web服务器,优点如下: 可以解决高并发,它是单线程,当访问量很多时,将访问者分配到不同的内存中,不同的内存区做不同的事,以快速解决这个线程.就像医院的分科室看病人.效 ...
- 2018.08.31 bzoj1419 Red is good(期望dp)
描述 桌面上有R张红牌和B张黑牌,随机打乱顺序后放在桌面上,开始一张一张地翻牌,翻到红牌得到1美元,黑牌则付 出1美元.可以随时停止翻牌,在最优策略下平均能得到多少钱. 输入 一行输入两个数R,B,其 ...
- =delete(c++11)
1.为什么要阻止类对象的拷贝? 1)有些类,不需要拷贝和赋值运算符,如:IO类,以避免多个拷贝对象写入或读取相同的IO缓冲 2.如何阻止? 1)不定义拷贝构造函数和拷贝赋值运算符时,好心的编译器也会及 ...
- idea使用svn提交时出现错误Warning not all local changes may be shown due to an error
参考于https://www.cnblogs.com/zhujiabin/p/6708012.html 解决方案: 1.File > Settings > Version Control ...
- UVa 1638 Pole Arrangement (递推或DP)
题意:有高为1,2,3...n的杆子各一根排成一行,从左边能看到L根,从右边能看到R根,求杆子的排列有多少种可能. 析:设d(i, j, k)表示高度为1-i的杆子排成一行,从左边看到j根,从右边看到 ...
- windows开启禁用网卡
' 在Windows中实现sudo命令--命令行环境中获取管理员权限 'ShellExecute 方法 '作用: 用于运行一个程序或脚本. '语法 ' .ShellExecute "appl ...
- 让tableView的某行移动到tableView的某位置
NSIndexPath *indexPath = [NSIndexPath indexPathForRow:lineNumber inSection:0]; [lrcTableView selectR ...
- SoC FPGA JTAG电路设计 要点
JTAG协议制定了一种边界扫描的规范,边界扫描架构提供了有效的测试布局紧凑的PCB板上元件的能力.边界扫描可以在不使用物理测试探针的情况下测试引脚连接,并在器件正常工作的过程中捕获运行数据. SoC ...
- Unity3D中随机函数的应用
电子游戏中玩家与系统进行互动的乐趣绝大多数取决于事件发生的不可预知性和随机性.在unity3D的API中提供了Random类来解决随机问题. 最简单的应用就是在数组中随机选择一个元素,使用Random ...
- 权限管理系统系列之WCF通信
目录 权限管理系统系列之序言 首先说下题外话,有些园友看了前一篇[权限管理系统系列之序言]博客加了QQ群(186841119),看了我写的权限管理系统的相关文档(主要是介绍已经开发的功能),给出了一 ...