(数据挖掘-入门-6)十折交叉验证和K近邻
主要内容:
1、十折交叉验证
2、混淆矩阵
3、K近邻
4、python实现
一、十折交叉验证
前面提到了数据集分为训练集和测试集,训练集用来训练模型,而测试集用来测试模型的好坏,那么单一的测试是否就能很好的衡量一个模型的性能呢?
答案自然是否定的,单一的测试集具有偶然性和随机性。因此本文介绍一种衡量模型(比如分类器)性能的方法——十折交叉验证(10-fold cross validation)
什么是十折交叉验证?
假设有个数据集,需要建立一个分类器,如何验证分类器的性能呢?
将数据集随机均为为10份,依次选择某1份作为测试集,其他9份作为训练集,训练出来的模型对测试集进行分类,并统计分类结果,就这样,重复10次实验,综合所有分类结果,就可以得到比较稳定的评价结果(当然,由于是随机划分数据集,因此每次运行结果都不一致)。
附:当然也可以选择k折交叉验证,最极端的就是留1交叉验证,每次只留一个样本做测试集,但这样的计算规模太大。
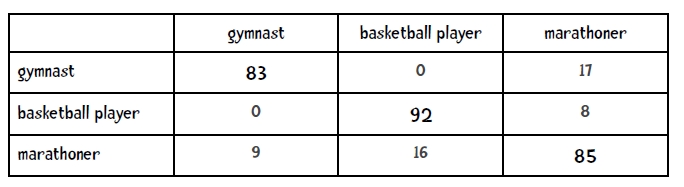
二、混淆矩阵
混淆矩阵:confuse matrix
假设有n个类别,那么分类结果的统计可以通过一个n*n的矩阵来表示,即混淆矩阵。
对角线即为分类正确的样本数。
三、K近邻(KNN)
在协同过滤中已经提到过K近邻,就是选择离某个样本最近的K个样本,根据该K个样本来决定此样本的数值或类别。
如果是连续数值,那么K近邻可以作为回归方法,通过K个样本的矩阵权重来拟合数值;
如果是离散数值,那么K近邻可以作为分类方法,通过K个样本的多数投票策略来决定类别;
四、python实现
数据集:
代码:
1、切分数据
# divide data into 10 buckets
import random def buckets(filename, bucketName, separator, classColumn):
"""the original data is in the file named filename
bucketName is the prefix for all the bucket names
separator is the character that divides the columns
(for ex., a tab or comma and classColumn is the column
that indicates the class""" # put the data in 10 buckets
numberOfBuckets = 10
data = {}
# first read in the data and divide by category
with open(filename) as f:
lines = f.readlines()
for line in lines:
if separator != '\t':
line = line.replace(separator, '\t')
# first get the category
category = line.split()[classColumn]
data.setdefault(category, [])
data[category].append(line)
# initialize the buckets
buckets = []
for i in range(numberOfBuckets):
buckets.append([])
# now for each category put the data into the buckets
for k in data.keys():
#randomize order of instances for each class
random.shuffle(data[k])
bNum = 0
# divide into buckets
for item in data[k]:
buckets[bNum].append(item)
bNum = (bNum + 1) % numberOfBuckets # write to file
for bNum in range(numberOfBuckets):
f = open("%s-%02i" % (bucketName, bNum + 1), 'w')
for item in buckets[bNum]:
f.write(item)
f.close() # example of how to use this code
buckets("pimaSmall.txt", 'pimaSmall',',',8)
2、十折交叉验证
#
#
# Nearest Neighbor Classifier for mpg dataset
# class Classifier:
def __init__(self, bucketPrefix, testBucketNumber, dataFormat): """ a classifier will be built from files with the bucketPrefix
excluding the file with textBucketNumber. dataFormat is a string that
describes how to interpret each line of the data files. For example,
for the mpg data the format is: "class num num num num num comment"
""" self.medianAndDeviation = [] # reading the data in from the file self.format = dataFormat.strip().split('\t')
self.data = []
# for each of the buckets numbered 1 through 10:
for i in range(1, 11):
# if it is not the bucket we should ignore, read in the data
if i != testBucketNumber:
filename = "%s-%02i" % (bucketPrefix, i)
f = open(filename)
lines = f.readlines()
f.close()
for line in lines[1:]:
fields = line.strip().split('\t')
ignore = []
vector = []
for i in range(len(fields)):
if self.format[i] == 'num':
vector.append(float(fields[i]))
elif self.format[i] == 'comment':
ignore.append(fields[i])
elif self.format[i] == 'class':
classification = fields[i]
self.data.append((classification, vector, ignore))
self.rawData = list(self.data)
# get length of instance vector
self.vlen = len(self.data[0][1])
# now normalize the data
for i in range(self.vlen):
self.normalizeColumn(i) ##################################################
###
### CODE TO COMPUTE THE MODIFIED STANDARD SCORE def getMedian(self, alist):
"""return median of alist"""
if alist == []:
return []
blist = sorted(alist)
length = len(alist)
if length % 2 == 1:
# length of list is odd so return middle element
return blist[int(((length + 1) / 2) - 1)]
else:
# length of list is even so compute midpoint
v1 = blist[int(length / 2)]
v2 =blist[(int(length / 2) - 1)]
return (v1 + v2) / 2.0 def getAbsoluteStandardDeviation(self, alist, median):
"""given alist and median return absolute standard deviation"""
sum = 0
for item in alist:
sum += abs(item - median)
return sum / len(alist) def normalizeColumn(self, columnNumber):
"""given a column number, normalize that column in self.data"""
# first extract values to list
col = [v[1][columnNumber] for v in self.data]
median = self.getMedian(col)
asd = self.getAbsoluteStandardDeviation(col, median)
#print("Median: %f ASD = %f" % (median, asd))
self.medianAndDeviation.append((median, asd))
for v in self.data:
v[1][columnNumber] = (v[1][columnNumber] - median) / asd def normalizeVector(self, v):
"""We have stored the median and asd for each column.
We now use them to normalize vector v"""
vector = list(v)
for i in range(len(vector)):
(median, asd) = self.medianAndDeviation[i]
vector[i] = (vector[i] - median) / asd
return vector
###
### END NORMALIZATION
################################################## def testBucket(self, bucketPrefix, bucketNumber):
"""Evaluate the classifier with data from the file
bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber)
f = open(filename)
lines = f.readlines()
totals = {}
f.close()
for line in lines:
data = line.strip().split('\t')
vector = []
classInColumn = -1
for i in range(len(self.format)):
if self.format[i] == 'num':
vector.append(float(data[i]))
elif self.format[i] == 'class':
classInColumn = i
theRealClass = data[classInColumn]
classifiedAs = self.classify(vector)
totals.setdefault(theRealClass, {})
totals[theRealClass].setdefault(classifiedAs, 0)
totals[theRealClass][classifiedAs] += 1
return totals def manhattan(self, vector1, vector2):
"""Computes the Manhattan distance."""
return sum(map(lambda v1, v2: abs(v1 - v2), vector1, vector2)) def nearestNeighbor(self, itemVector):
"""return nearest neighbor to itemVector"""
return min([ (self.manhattan(itemVector, item[1]), item)
for item in self.data]) def classify(self, itemVector):
"""Return class we think item Vector is in"""
return(self.nearestNeighbor(self.normalizeVector(itemVector))[1][0]) def tenfold(bucketPrefix, dataFormat):
results = {}
for i in range(1, 11):
c = Classifier(bucketPrefix, i, dataFormat)
t = c.testBucket(bucketPrefix, i)
for (key, value) in t.items():
results.setdefault(key, {})
for (ckey, cvalue) in value.items():
results[key].setdefault(ckey, 0)
results[key][ckey] += cvalue # now print results
categories = list(results.keys())
categories.sort()
print( "\n Classified as: ")
header = " "
subheader = " +"
for category in categories:
header += category + " "
subheader += "----+"
print (header)
print (subheader)
total = 0.0
correct = 0.0
for category in categories:
row = category + " |"
for c2 in categories:
if c2 in results[category]:
count = results[category][c2]
else:
count = 0
row += " %2i |" % count
total += count
if c2 == category:
correct += count
print(row)
print(subheader)
print("\n%5.3f percent correct" %((correct * 100) / total))
print("total of %i instances" % total) tenfold("mpgData/mpgData/mpgData", "class num num num num num comment")
3、K近邻
#
# K Nearest Neighbor Classifier for Pima dataset
# import heapq
import random class Classifier:
def __init__(self, bucketPrefix, testBucketNumber, dataFormat, k): """ a classifier will be built from files with the bucketPrefix
excluding the file with textBucketNumber. dataFormat is a string that
describes how to interpret each line of the data files. For example,
for the mpg data the format is: "class num num num num num comment"
""" self.medianAndDeviation = []
self.k = k
# reading the data in from the file self.format = dataFormat.strip().split('\t')
self.data = []
# for each of the buckets numbered 1 through 10:
for i in range(1, 11):
# if it is not the bucket we should ignore, read in the data
if i != testBucketNumber:
filename = "%s-%02i" % (bucketPrefix, i)
f = open(filename)
lines = f.readlines()
f.close()
for line in lines[1:]:
fields = line.strip().split('\t')
ignore = []
vector = []
for i in range(len(fields)):
if self.format[i] == 'num':
vector.append(float(fields[i]))
elif self.format[i] == 'comment':
ignore.append(fields[i])
elif self.format[i] == 'class':
classification = fields[i]
self.data.append((classification, vector, ignore))
self.rawData = list(self.data)
# get length of instance vector
self.vlen = len(self.data[0][1])
# now normalize the data
for i in range(self.vlen):
self.normalizeColumn(i) ##################################################
###
### CODE TO COMPUTE THE MODIFIED STANDARD SCORE def getMedian(self, alist):
"""return median of alist"""
if alist == []:
return []
blist = sorted(alist)
length = len(alist)
if length % 2 == 1:
# length of list is odd so return middle element
return blist[int(((length + 1) / 2) - 1)]
else:
# length of list is even so compute midpoint
v1 = blist[int(length / 2)]
v2 =blist[(int(length / 2) - 1)]
return (v1 + v2) / 2.0 def getAbsoluteStandardDeviation(self, alist, median):
"""given alist and median return absolute standard deviation"""
sum = 0
for item in alist:
sum += abs(item - median)
return sum / len(alist) def normalizeColumn(self, columnNumber):
"""given a column number, normalize that column in self.data"""
# first extract values to list
col = [v[1][columnNumber] for v in self.data]
median = self.getMedian(col)
asd = self.getAbsoluteStandardDeviation(col, median)
#print("Median: %f ASD = %f" % (median, asd))
self.medianAndDeviation.append((median, asd))
for v in self.data:
v[1][columnNumber] = (v[1][columnNumber] - median) / asd def normalizeVector(self, v):
"""We have stored the median and asd for each column.
We now use them to normalize vector v"""
vector = list(v)
for i in range(len(vector)):
(median, asd) = self.medianAndDeviation[i]
vector[i] = (vector[i] - median) / asd
return vector
###
### END NORMALIZATION
################################################## def testBucket(self, bucketPrefix, bucketNumber):
"""Evaluate the classifier with data from the file
bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber)
f = open(filename)
lines = f.readlines()
totals = {}
f.close()
for line in lines:
data = line.strip().split('\t')
vector = []
classInColumn = -1
for i in range(len(self.format)):
if self.format[i] == 'num':
vector.append(float(data[i]))
elif self.format[i] == 'class':
classInColumn = i
theRealClass = data[classInColumn]
#print("REAL ", theRealClass)
classifiedAs = self.classify(vector)
totals.setdefault(theRealClass, {})
totals[theRealClass].setdefault(classifiedAs, 0)
totals[theRealClass][classifiedAs] += 1
return totals def manhattan(self, vector1, vector2):
"""Computes the Manhattan distance."""
return sum(map(lambda v1, v2: abs(v1 - v2), vector1, vector2)) def nearestNeighbor(self, itemVector):
"""return nearest neighbor to itemVector"""
return min([ (self.manhattan(itemVector, item[1]), item)
for item in self.data]) def knn(self, itemVector):
"""returns the predicted class of itemVector using k
Nearest Neighbors"""
# changed from min to heapq.nsmallest to get the
# k closest neighbors
neighbors = heapq.nsmallest(self.k,
[(self.manhattan(itemVector, item[1]), item)
for item in self.data])
# each neighbor gets a vote
results = {}
for neighbor in neighbors:
theClass = neighbor[1][0]
results.setdefault(theClass, 0)
results[theClass] += 1
resultList = sorted([(i[1], i[0]) for i in results.items()], reverse=True)
#get all the classes that have the maximum votes
maxVotes = resultList[0][0]
possibleAnswers = [i[1] for i in resultList if i[0] == maxVotes]
# randomly select one of the classes that received the max votes
answer = random.choice(possibleAnswers)
return( answer) def classify(self, itemVector):
"""Return class we think item Vector is in"""
# k represents how many nearest neighbors to use
return(self.knn(self.normalizeVector(itemVector))) def tenfold(bucketPrefix, dataFormat, k):
results = {}
for i in range(1, 11):
c = Classifier(bucketPrefix, i, dataFormat, k)
t = c.testBucket(bucketPrefix, i)
for (key, value) in t.items():
results.setdefault(key, {})
for (ckey, cvalue) in value.items():
results[key].setdefault(ckey, 0)
results[key][ckey] += cvalue # now print results
categories = list(results.keys())
categories.sort()
print( "\n Classified as: ")
header = " "
subheader = " +"
for category in categories:
header += "% 2s " % category
subheader += "-----+"
print (header)
print (subheader)
total = 0.0
correct = 0.0
for category in categories:
row = " %s |" % category
for c2 in categories:
if c2 in results[category]:
count = results[category][c2]
else:
count = 0
row += " %3i |" % count
total += count
if c2 == category:
correct += count
print(row)
print(subheader)
print("\n%5.3f percent correct" %((correct * 100) / total))
print("total of %i instances" % total) print("SMALL DATA SET")
tenfold("pimaSmall/pimaSmall/pimaSmall",
"num num num num num num num num class", 3) print("\n\nLARGE DATA SET")
tenfold("pima/pima/pima",
"num num num num num num num num class", 3)
(数据挖掘-入门-6)十折交叉验证和K近邻的更多相关文章
- 十折交叉验证10-fold cross validation, 数据集划分 训练集 验证集 测试集
机器学习 数据挖掘 数据集划分 训练集 验证集 测试集 Q:如何将数据集划分为测试数据集和训练数据集? A:three ways: 1.像sklearn一样,提供一个将数据集切分成训练集和测试集的函数 ...
- S折交叉验证(S-fold cross validation)
S折交叉验证(S-fold cross validation) 觉得有用的话,欢迎一起讨论相互学习~Follow Me 仅为个人观点,欢迎讨论 参考文献 https://blog.csdn.net/a ...
- 10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)、分层采样(Stratification)
10折交叉验证 我们构建一个分类器,输入为运动员的身高.体重,输出为其从事的体育项目-体操.田径或篮球. 一旦构建了分类器,我们就可能有兴趣回答类似下述的问题: . 该分类器的精确率怎么样? . 该分 ...
- 十倍交叉验证 10-fold cross-validation
10-fold cross-validation,用来测试算法准确性.是常用的测试方法.将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验.每次试验都会得出相应的正确 ...
- sklearn的K折交叉验证函数KFold使用
K折交叉验证时使用: KFold(n_split, shuffle, random_state) 参数:n_split:要划分的折数 shuffle: 每次都进行shuffle,测试集中折数的总和就是 ...
- k折交叉验证
原理:将原始数据集划分为k个子集,将其中一个子集作为验证集,其余k-1个子集作为训练集,如此训练和验证一轮称为一次交叉验证.交叉验证重复k次,每个子集都做一次验证集,得到k个模型,加权平均k个模型的结 ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
- cross_val_score 交叉验证与 K折交叉验证,嗯都是抄来的,自己作个参考
因为sklearn cross_val_score 交叉验证,这个函数没有洗牌功能,添加K 折交叉验证,可以用来选择模型,也可以用来选择特征 sklearn.model_selection.cross ...
- 小白学习之pytorch框架(7)之实战Kaggle比赛:房价预测(K折交叉验证、*args、**kwargs)
本篇博客代码来自于<动手学深度学习>pytorch版,也是代码较多,解释较少的一篇.不过好多方法在我以前的博客都有提,所以这次没提.还有一个原因是,这篇博客的代码,只要好好看看肯定能看懂( ...
随机推荐
- [CEOI2008]order --- 最小割
[CEOI2008]order 题目描述: 有N个任务,M种机器,每种机器你可以租或者买过来. 每个工作包括若干道工序,每道工序需要某种机器来完成,你可以通过购买或租用机器来完成. 现在给出这些参数, ...
- JSOI2018R2题解
D1T1:潜入行动 裸的树上DP.f[i][j][0/1][0/1]表示以i为根的子树放j个设备,根有没有放,根有没有被子树监听,的方案数.转移显然. #include<cstdio> # ...
- eclipse转idea, 快捷键设置
设置快捷键的途径: 打开idea的配置,找到Keymap,设置为eclipse 另外还要手动设置某些快捷键 上下移动 点击类打开 代码提示 查询 重命名 快速实现接口 回到上一次光标处
- hdu 3879 方案选择
每日一水--- #include <cstdio> #include <cstring> #include <vector> #define oo 0x3f3f3f ...
- the elements of computing systems 的读书笔记1
想转职程序猿,还真不是说懂一门语言就够的了,想要继续进步,必须懂其相关实现原理,比如这些底层的构造.最近看的就是这一本计算机入门级的书,但是对我这个纯自学的人来说真是能学到很多. 这本书从最基本的Na ...
- Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置(转)
原文地址:http://www.cnblogs.com/xiaoluo501395377/archive/2013/04/07/3003278.html 如果要在Linux上做j2ee开发,首先得搭建 ...
- IO流-复制多极文件夹(递归实现)
package com.io.test; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import ...
- USB Mass Storage大容量存储 The Thirteen Class章节的理解
http://blog.csdn.net/xgbing/article/details/7002558 USB Mass Storage 6.7 The Thirteen Class章节的理解 Cas ...
- 关于ANDROID模拟器的一些事
转载请注明本文出自大苞米的博客(http://blog.csdn.net/a396901990),谢谢支持! 继上一篇Android Studio VS Eclipse的文章后接着来分享AnDevCo ...
- Linux下open与fopen的区别
int open(const char *path, int access,int mode) path 要打开的文件路径和名称 access 访问模式,宏定义和含义如下: ...