【数据结构】 顺序表查找(折半查找&&差值查找)
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXSIZE 10
首先构造一个数组, 由随机数生成, 同时确保没有重复元素。(为了排序之后查找时候方便)
为了确保没有重复的元素使用了一个简单的查找函数:
用数组的0号元素来作为哨兵
化简了操作:
int search0(int *a,int length,int key)
{
int i;
a[] = key;
i = length;
while(a[i]!=key)
{
i--;
}
return i; //这样如果没有查找到元素,就会return 0;
}
int a[MAXSIZE] = {};
int i;
int find;
int rec;
srand((unsigned)time(NULL));
for(i=;i<MAXSIZE+;i++)
{
a[i] = rand()%+;
while(search0(a,i-,a[i])!=&&i!=&&i!=MAXSIZE+)
a[i]=rand()%+;
}
还需要一个函数 显示数组里所有元素:
void print_List(int *a,int length)
{
int i;
printf("List:");
for(i=;i<length+;i++)
{
printf(" %d ",a[i]);
}
printf("\n");
}
使用冒泡法进行排序:
void sort(int *a,int length)
{
int i,j;
int t;
for(i=;i<length+;i++)
{
for(j=i+;j<length+;j++)
{
if(a[i]>a[j])
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
}
}
之后是折半查找的函数:
int search_half(int *a,int length,int key)
{
int low,high,mid;
low = ;
high = length;
int n = ;
while(low<=high)
{
//mid = (low + high)/2; //折半查找
mid = low+ (high - low)*(key-a[low])/(a[high]-a[low]); //差值查找
printf("%d: low = %d high = %d mid = %d\n",n,low,high,mid);
if(key<a[mid])
high= mid - ;
else if (key>a[mid])
low = mid + ;
else
return mid;
n++;
}
return ;
}
首先需要确保是一个有序的表,这样通过比较key 和 mid的大小
如果key小于mid则说明key可能在小于mid的区域 high 调整
如果key大于mid则说明key可能在大于mid的区域 low 调整
相等就找到了
效果如图: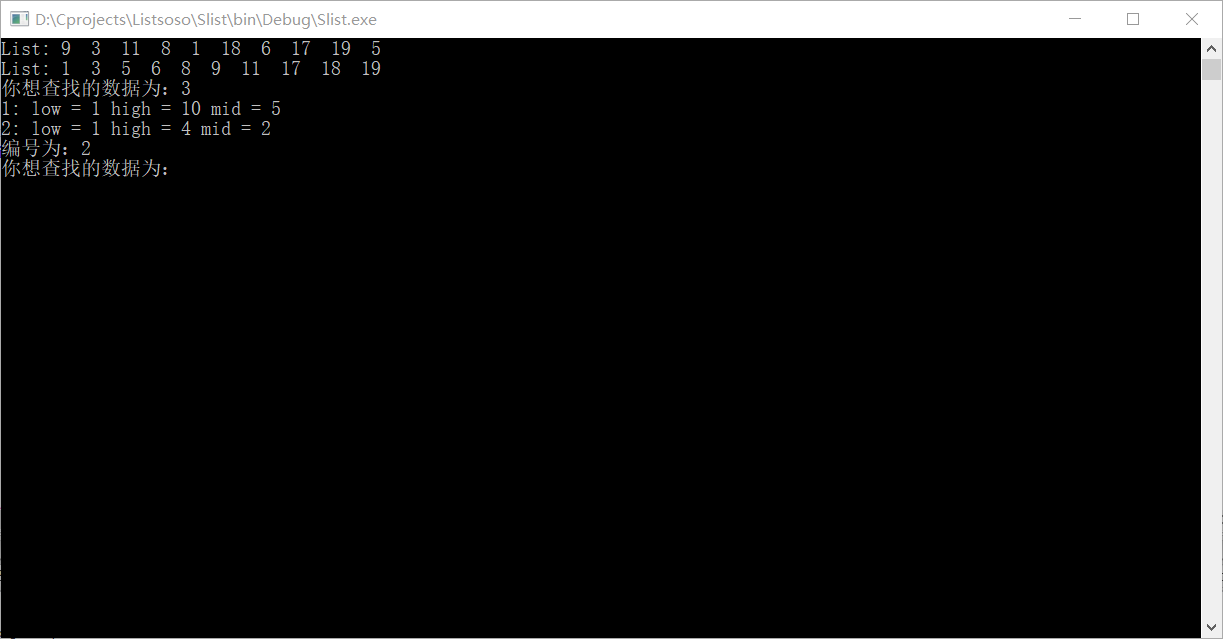
那么另一个问题出现了:为什么一定要折半呢?
比如说在0~1000内查找5 折半就很不明智了吧。
最初的公式可以理解为:
mid = (low+high)/2 = low+1/2*(high - low)
即 在low这个基础数值上附加了一个数值 (这里是选择区间数值的一半), 如果我们想改进这个公式, 显然应该改进那个附加值 改为与key 相关
mid = low+(key-a[low])/(a[high]-a[low])*(highj - low)
比如说还是在 0~1000个内寻找5
第一次的mid 修改为 mid = 0+(5-0)/(1000-0)*1000 = 5 显然能看出 当插值明显很小(或者很大) mid 的取值取决于key在整体的大小趋势, 这样mid也会明显变小(或者很大)
测试, 将MAXSIZE 增大为20
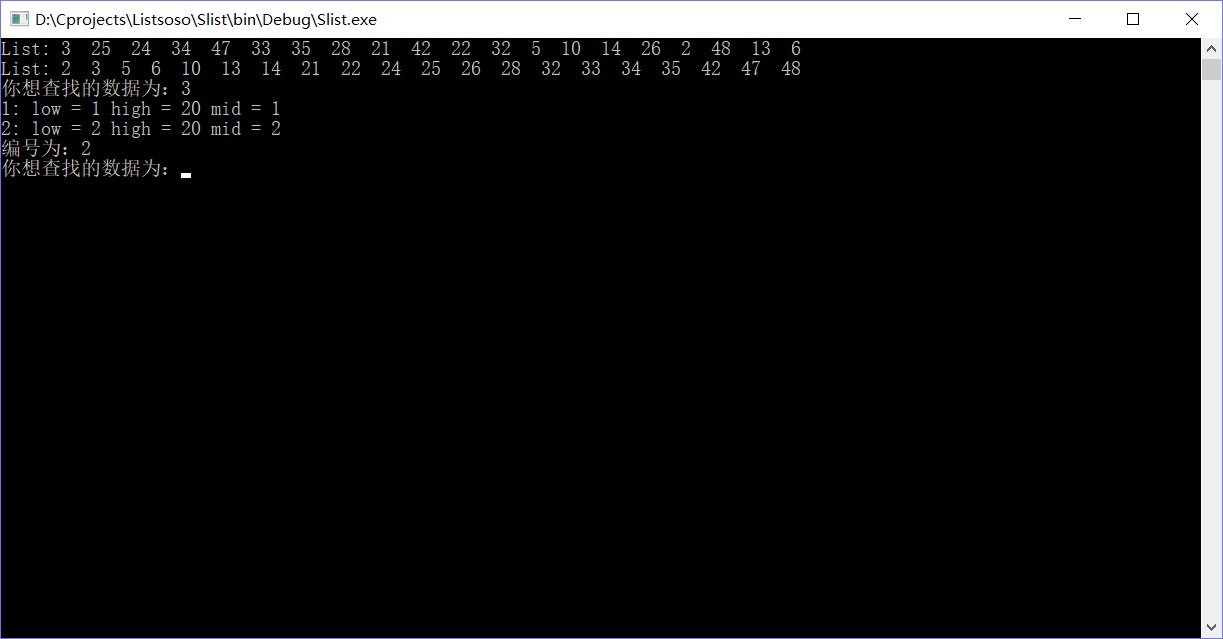
比常规的折半相比, 速度更快了。
完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXSIZE 20
void print_List(int *a,int length)
{
int i;
printf("List:");
for(i=;i<length+;i++)
{
printf(" %d ",a[i]);
}
printf("\n");
} void sort(int *a,int length)
{
int i,j;
int t;
for(i=;i<length+;i++)
{
for(j=i+;j<length+;j++)
{
if(a[i]>a[j])
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
}
}
int search0(int *a,int length,int key)
{
int i;
a[] = key;
i = length;
while(a[i]!=key)
{
i--;
}
return i;
}
int search_half(int *a,int length,int key)
{
int low,high,mid;
low = ;
high = length;
int n = ;
while(low<=high)
{
//mid = (low + high)/2; //折半查找
mid = low+ (high - low)*(key-a[low])/(a[high]-a[low]); //差值查找
printf("%d: low = %d high = %d mid = %d\n",n,low,high,mid);
if(key<a[mid])
high= mid - ;
else if (key>a[mid])
low = mid + ;
else
return mid;
n++;
}
return ;
}
int main()
{
int a[MAXSIZE] = {};
int i;
int find;
int rec;
srand((unsigned)time(NULL));
for(i=;i<MAXSIZE+;i++)
{
a[i] = rand()%+;
while(search0(a,i-,a[i])!=&&i!=&&i!=MAXSIZE+)
a[i]=rand()%+;
}
print_List(a,MAXSIZE);
sort(a,MAXSIZE);
print_List(a,MAXSIZE);
while()
{
printf("你想查找的数据为:");
scanf("%d",&find);
rec=search_half(a,MAXSIZE,find);
if(rec != )
printf("编号为:%d\n",rec);
else
printf("没找到\n");
}
return ;
}
【数据结构】 顺序表查找(折半查找&&差值查找)的更多相关文章
- hrbustoj 1545:基础数据结构——顺序表(2)(数据结构,顺序表的实现及基本操作,入门题)
基础数据结构——顺序表(2) Time Limit: 1000 MS Memory Limit: 10240 K Total Submit: 355(143 users) Total Accep ...
- hrbust-1545-基础数据结构——顺序表(2)
http://acm.hrbust.edu.cn/index.php?m=ProblemSet&a=showProblem&problem_id=1545 基础数据结构——顺序表(2) ...
- 数据结构---顺序表(C++)
顺序表 是用一段地址连续的存储单元依次存储线性表的数据元素. 通常用一维数组来实现 基本操作: 初始化 销毁 求长 按位查找 按值查找 插入元素 删除位置i的元素 判空操作 遍历操作 示例代码: // ...
- 数据结构——顺序表(sequence list)
/* sequenceList.c */ /* 顺序表 */ /* 线性表的顺序存储是指在内存中用地址连续的一块存储空间顺序存放线性表中的各项数据元素,用这种存储形式的线性表称为顺序表. */ #in ...
- 数据结构 - 顺序表 C++ 实现
顺序表 此处实现的顺序表为**第一个位置为 data[0] **的顺序表 顺序表的定义为 const int MAX = 50; typedef int ElemType; typedef struc ...
- python算法与数据结构-顺序表(37)
1.顺序表介绍 顺序表是最简单的一种线性结构,逻辑上相邻的数据在计算机内的存储位置也是相邻的,可以快速定位第几个元素,中间不允许有空,所以插入.删除时需要移动大量元素.顺序表可以分配一段连续的存储空间 ...
- 数据结构顺序表中Sqlist *L,&L,Sqlist *&L
//定义顺序表L的结构体 typedef struct { Elemtype data[MaxSize]: int length; }SqList; //建立顺序表 void CreateList(S ...
- c数据结构 顺序表和链表 相关操作
编译器:vs2013 内容: #include "stdafx.h"#include<stdio.h>#include<malloc.h>#include& ...
- 数据结构顺序表删除所有特定元素x
顺序表类定义: template<class T> class SeqList : { public: SeqList(int mSize); ~SeqList() { delete[] ...
随机推荐
- vue 监听对象里的特定数据
vue 监听对象里的特定数据变化 通常是这样写的,只能监听某一个特定数据 watch: { params: function(val) { console.log(val) this.$ajax.g ...
- HTML&&css面试题
HTML&css相关问题 1.XHTML和HTML有什么区别 HTML是一种基本的WEB网页设计语言,XHTML是一个基于XMl的置标语言 最主要的不同 XHTML元素必须被正确地嵌套. XH ...
- Redis configuration
官方2.6配置如下: # Redis configuration file example # Note on units: when memory size is needed, it is pos ...
- window.location.replace
有3个页面 a,b,c 如果当前页面是c页面,并且c页面是这样跳转过来的:a->b->c 1:b->c 是通过window.location.replace("..xx/c ...
- Rails中activeAdmin的使用
一.开始ActiveAdmin Active Admin是一个发布在RAILS3中使用的Gem. 1.我们为了快速开始我们对Active Admin的了解,我们首先安装它: 在你GemFile中添加g ...
- centos 6.5安装docker
安装linux,需要系统内核为3.x以上,如果centos版本为7以下,先升级系统内核 1.关闭selinux setenforce 0 sed -i '/^SELINUX=/c\SELINUX=di ...
- ssh连接工具中文乱码问题
在终端运行: export LC_ALL=zh_CN.GB2312;export LANG=zh_CN.GB2312
- 面试6 在c#中如何声明一个类不能被继承
C#通过关键字 sealed 可以声明一个类型不能被继承. 设计中应该为所有不被作为基类的类型添加sealed关键字,用以避免各种来自继承的易产生的错误.
- 【基于初学者的SSH】struts2 环境配置
01:导入Jar包 下载地址:http://struts.apache.org/ 将下好的jar包放导WEB-INF下的lib文件夹下 02:创建Action:com.action.LoginActi ...
- Hibernate中查询优化策略
Hibernate查询优化策略 ² 使用延迟加载等方式避免加载多余数据 ² 通过使用连接查询,配置二级缓存.查询缓存等方式减少select语句数目 ² 结合缓存机制,使用iterate()方法减少查询 ...