Netty基础系列(3) --彻底理解NIO
前言
上一节中我们提到了同步异步与阻塞非阻塞的区别,知道了同步并不等于阻塞。而本节的主角NIO是一种同步非阻塞的I/O模型,并且是I/O多路复用模型。NIO在java中被称为 New I/O。它并不能提高I/O处理的效率,注意我这里说的是效率,而从根本上解决的是I/O处理的并发问题。
那么NIO的本质是什么样的呢?它是怎样与事件模型结合来解放线程、提高系统吞吐的呢?
回顾五种I/O模型
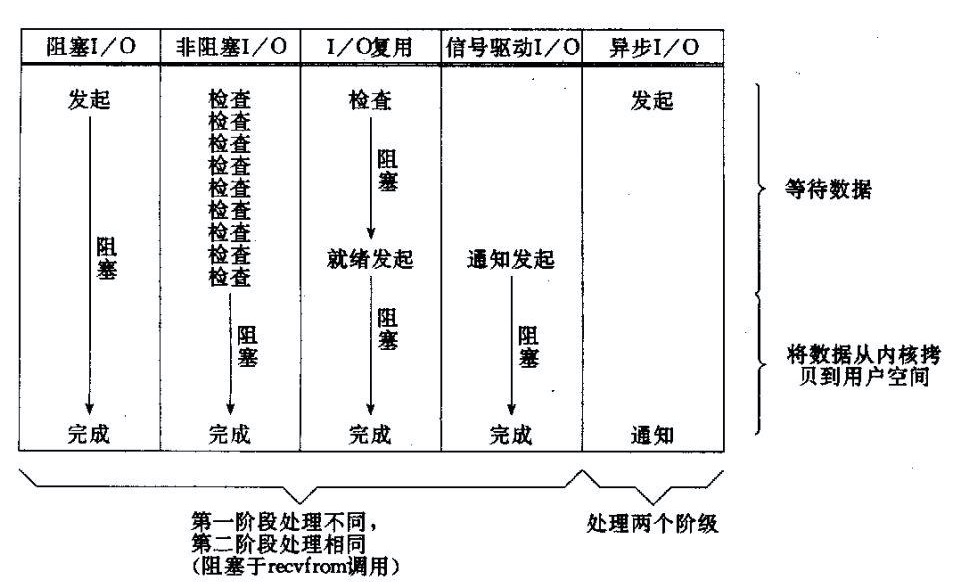
由上图可知,所有的系统I/O都分为两个阶段:等待数据和将数据从内核态复制到用户态。
举一个例子,传统的BIO中,当我们要读某块网卡接受到的网络数据的时候,程序会一直阻塞直到有数据到来,在此阶段cpu空转不干活。当监听到有数据的时候,就将数据从内核缓存区copy到用户缓存区,而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
理解I/O的这两个阶段实际意义尤其的重要。下面讲NIO之前,我们先来深入剖析一下传统同步阻塞式BIO。
同步阻塞式BIO
下面这个伪代码是一个传统BIO模型,它的作用是打印客户端发来的数据并返回数据。
public class SocketServer {
public static void main(String args[]) {
ExecutorService executor = Executors.newFixedThreadPool(100);//线程池
try {
ServerSocket ss = new ServerSocket(8888);
System.out.println("启动服务器....");
while (true) {
//阻塞等待接受客户端连接。
Socket socket = ss.accept();
System.out.println("客户端:" + socket.getInetAddress().getLocalHost() + "已连接到服务器");
executor.submit(new DataHandler(socket));
}
} catch (IOException e) {
e.printStackTrace();
}
}
static class DataHandler implements Runnable {
Socket socket;
public DataHandler(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
//阻塞操作
try {
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String mess = br.readLine();
System.out.println("客户端发来的数据:" + mess);
//返回数据
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bw.write("服务器成功打印日志\n");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
上诉代码中,总共有三处地方发生了阻塞,第一处是等待客户端连接,第二处是input操作,第三处是output操作。所以该模型必须使用多线程来操作,如果是单线程,系统必将挂死在那里。
对应上述图片,readLine()操作又有如下两个阶段(等待数据和将数据copy到用户缓存中):
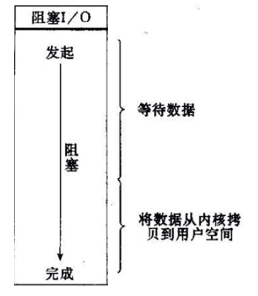
这个模型严格的来说效率是最快的,注意,我说的是效率。但是这种模型有一个缺点就是每当一个客户端发送请求的时候,服务器就会为其创建一个线程,在活动连接数不是特别高(小于1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
但是这个方式的缺点就是,一旦有客户端访问,都创建一个专属的线程去处理,即便有线程池的存在,当并发访问量上来以后,CPU使用率会迅速上升,导致系统几乎陷入不可用的状态。
NIO
接下来我们进入今天的主题:NIO。
如果是你在开发一个基于BIO模型的服务器,发现哪一天系统无法抗住庞大的并发,那么你有什么手段去优化你的服务器呢?
没错,如果你看了之前的章节,那么你的脑海一定会出现多路复用模型,在传统BIO模型中,并发量上限的根本原因就是启动了过多的线程。
对于BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能”傻等”,即使通过各种估算,算出来操作系统没有能力进行读写,readLine()和write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数则可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(readLine()返回0或者write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
多路复用器Selector
当一个客户端请求到来的时候,我们会将其(Channel)注册到Selector上,然后Selector会不断的轮询注册在其上的Channel,如果某个Channel上面发生了读或者写事件,这个Channel就会处于就绪状态,会被Selector轮询出来,然后通过调用方法获取所有就绪Channel的集合,进行后续的操作。
一个多路复用器Selector可以同时轮询多个Channel,由于JDK使用了epoll()(Netty基础系列(1)中有介绍)代替传统的select,所以没有数量1024/2048的上限限制。这也就意味着每一个线程负责Seletor的轮询,就可以接入成千上万个客户端,这确实是非常巨大的进步。
通道Channel
可以将其想象成一个水管,一个客户端的连接成功,可以想象成这根水管一头插入了服务器,一头插入了客户端,它们之间的通信就靠的这根水管。
与传统的流不同,流只能在一个方向是移动(如上述代码,input只能写入,output只能写出)。但是Channel是全双工的,意思是能同时支持读写操作。
缓存区Buffer
在NIO库类中加入了一个Buffer对象。它区别于传统的流,能写入或者将数据直接读到Stream对象中。NIO所有数据都是基于Buffer处理的,在读取数据的时候直接读取Buffer里的数据,写数据的时候直接往Buffer里写数据。任何时候访问NIO中的数据,都是通过缓冲区进行操作的。
通常情况下,操作系统的一次写操作分为两步: 1. 将数据从用户空间拷贝到系统空间。 2. 从系统空间往网卡写。同理,读操作也分为两步: ① 将数据从网卡拷贝到系统空间; ② 将数据从系统空间拷贝到用户空间。
但是值得注意的是,如果使用了DirectByteBuffer(继承Buffer),一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
总结
本章多个角度的解释了NIO,以及NIO的基本组件。
NIO编程的代码博主没有过多的解释,因为对于NIO编程博主也是个小菜鸡。但是!Netty将NIO进行了进一步的封装,让我们能使用更简单,更高效的API来完成我们NIO操作。比直接写NIO更轻松,也不必在意操作系统之间的区别。但是有兴趣的小伙伴可以自行学习NIO编程,然后再体会对比一下与Netty编程实现相同功能的难度与代码量。你就会深深感叹,Netty真他么的强大。
最后再提醒各位一点,使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
Netty基础系列(3) --彻底理解NIO的更多相关文章
- Netty基础系列(2) --彻底理解阻塞非阻塞与同步异步的区别
引言 在进行I/O学习的时候,阻塞和非阻塞,同步和异步这几个概念常常被提及,但是很多人对这几个概念一直很模糊.要想学好Netty,这几个概念必须要掌握清楚. 同步和异步 同步与异步的区别在于,异步基于 ...
- Netty基础系列(4) --堆外内存与零拷贝详解
前言 到目前为止,我们知道Nio当中有三个最最核心的组件,分别是:Selelctor,Channel,Buffer.在Netty基础系列(3) --彻底理解NIO 这一篇文章中只是进行了大致的介绍. ...
- c#基础系列3---深入理解ref 和out
"大菜":源于自己刚踏入猿途混沌时起,自我感觉不是一般的菜,因而得名"大菜",于自身共勉. 扩展阅读 c#基础系列1---深入理解 值类型和引用类型 c#基础系 ...
- Netty基础系列(1) --linux网路I/O模型
引言 我一直认为对于java的学习,掌握基础的性价比要远远高于使用框架,而基础知识中对于网络相关知识的掌握也是重中之重.对于一个java程序来说,无论是工作中还是面试,对于Netty的掌握都是及其重要 ...
- c#基础系列2---深入理解 String
"大菜":源于自己刚踏入猿途混沌时起,自我感觉不是一般的菜,因而得名"大菜",于自身共勉. 扩展阅读:深入理解值类型和引用类型 基本概念 string(严格来说 ...
- c#基础系列1---深入理解值类型和引用类型
"大菜":源于自己刚踏入猿途混沌拾起,自我感觉不是一般的菜,因而得名"大菜",于自身共勉. 不知不觉已经踏入坑已10余年之多,对于c#多多少少有一点自己的认识, ...
- Netty基础系列(5) --零拷贝彻底分析
前言 上一节(堆外内存与零拷贝)当中我们从jvm堆内存的视角解释了一波零拷贝原理,但是仅仅这样还是不够的. 为了彻底搞懂零拷贝,我们趁热打铁,接着上一节来继续讲解零拷贝的底层原理. 感受一下NIO的速 ...
- Netty入门系列(1) --使用Netty搭建服务端和客户端
引言 前面我们介绍了网络一些基本的概念,虽然说这些很难吧,但是至少要做到理解吧.有了之前的基础,我们来正式揭开Netty这神秘的面纱就会简单很多. 服务端 public class PrintServ ...
- SQL Server-字字珠玑,一纸详文,完全理解SERIALIZABLE最高隔离级别(基础系列收尾篇)
前言 对于上述锁其实是一个老生常谈的话题了,但是我们是否能够很明确的知道在什么情况下会存在上述各种锁类型呢,本节作为SQL Server系列末篇我们 来详细讲解下. Range-Lock 上述关于Ra ...
随机推荐
- python 实现redis订阅发布功能
redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- sqlite3 数据库命令操作
SQLite 数据库,是一个非常轻量级自包含(lightweight and self-contained)的DBMS,它可移植性好,很容易使用,很小,高效而且可靠. SQLite嵌入到使用它的应用程 ...
- 阿里云rds 磁盘空间满导致实例锁定
1.RDS 数据日志已经快满了, 导致数据库不能写入,只读. 2. Binlog日志的保存及清理规则 MySQL实例的空间内默认清理binlog日志的规则如下: 实例空间内默认会保存最近18个小时内的 ...
- WordPress函数wp_page_menu详解
说明 该标签显示带有链接的WordPress页面列表,并且可以选择将 Home(主页)自动显示为列表中的一员.该标签是自定义侧边栏和标题栏的好帮手,同时还可以用在其它模板中. WordPress教程 ...
- nGrinder性能测试平台的安装部署
1.从GitHub下载war包: https://github.com/naver/ngrinder/releases 2.把ngrinder-controller-3.4.2.war重命名为ngri ...
- Java实现斗地主发牌(Collections工具类的应用)
package com.doudou_01; import java.util.ArrayList; import java.util.Collections; import java.util.Li ...
- Hbase基本用法
hbase 一些重要的解释(杂) 访问habse三种方式 访问hbase table中的行,只有三种方式: 1 通过单个row key访问 2 通过row key的range 3 全表扫描 Row k ...
- tensorflow-gpu在win10下的安装
参考:https://blog.csdn.net/gyp2448565528/article/details/79451212 按照原博主的方法在自己的机器上会有一点小错误,下面的方法略有不同 环境: ...
- Ubuntu 16.04安装tensorflow_gpu的方法
参考资料: Ubuntu 16.04安装tensorflow_gpu 1.9.0的方法 装Tensorflow,运行项目报错: module compiled against API version ...
- centos7 --ngnix 常用命令:
配置命令 随服务器启动 # systemctl enable nginx.service 重启 nginx 服务 # systemctl restart nginx.service 停止 nginx ...