K-means算法的实现
K-MEANS算法是一种经典的聚类算法,在模式识别得到了广泛的应用。算法中有两个关键问题需要考虑:一是如何评价对象的相似性,通常用距离来度量,距离越近越相似;另外一个是如何评价聚类的效果,通常采用误差平方和函数来作为评价准则。
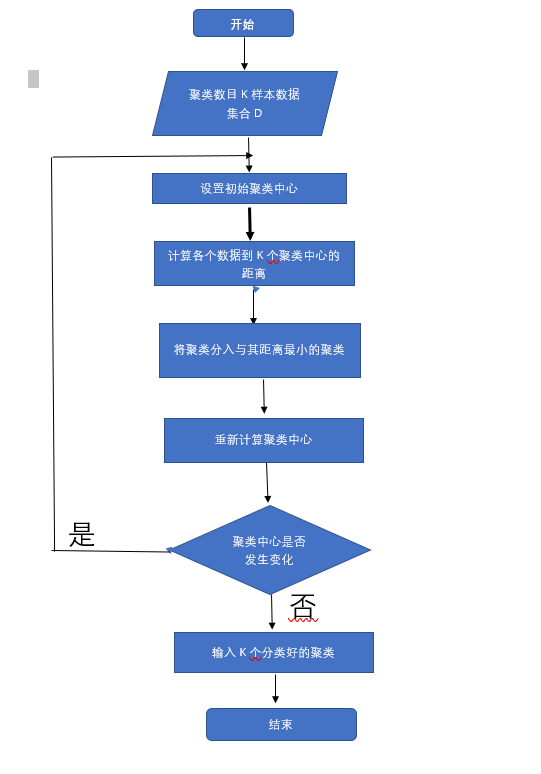
算法过程:
输入:簇的数目K和包含n个对象的数据库。
输出:K个簇,使平方误差和最小
算法步骤:
(1):为每个聚类确定一个初始聚类中心,这样就有K个初始聚类中心
(2:将样本集中的样本按照最小距离原则分配到最邻近聚类
(3);使用每个聚类中的样本均值作为新的聚类中心
(4):重复步骤(2)和(3),直到聚类中心不在变化
(5):结束,得到K个聚类
流程图
代码实现
import numpy
import random
import codecs
import copy
import re
import matplotlib.pyplot as plt
#其次计算向量vecl和向量vec2之间的欧式距离
def calcuDistance(vec1,vec2):
return numpy.sqrt(numpy.sum(numpy.square(vec1-vec2)))
#载入数据测试数据集,数据由文本保存,为二维坐标
def loadDataSet():
inFile = "F:/testSet.txt" #数据集文件
inDate = codecs.open(inFile,'r','utf-8').readlines()
dataSet = list()
for line in inDate:
line = line.strip()
strList = re.split('[ ]+',line) #删除多余的空格
#print strList[0] ,strList[1]
numList = list()
for item in strList:
num = float(item)
numList.append(num) dataSet.append(numList)
return dataSet #初始化K个聚类中心,随机获取
def initCentroids(dataSet,k):
return random.sample(dataSet,k)#从dataSe中随机获取K个数据项返回
#对每个属于dataSet的item,计算item与centrodList中K个聚类中心的欧式距离,找出
#距离最小的,并将item加入相应的簇中
def minDistance(dataSet,centroidList):
clusterDict = dict() #用dict来保存聚类的结果
for item in dataSet:
vec1 = numpy.array(item) #转换成array形式
flag = 0 #簇分类标记,记录与相应的簇距离最近的那个簇
minDis = float("inf") #初始化为最大值
for i in range(len(centroidList)):
vec2 = numpy.array(centroidList[i])
distance = calcuDistance(vec1,vec2) #计算相应的欧拉距离
if distance < minDis:
minDis = distance
flag = i #循环结束时,flag保存的是与当前item距离最近的那个簇标记
if flag not in clusterDict.keys():#簇标记不存在,进行初始化
clusterDict[flag] = list()
clusterDict[flag].append(item) #加入相应的类别中
return clusterDict #计算每列的均值,即找到聚类中心
def getCentroids(clusterDict):
#得到K个质心
centroidList = list()
for key in clusterDict.keys():
centroid = numpy.mean(numpy.array(clusterDict[key]),axis=0)
centroidList.append(centroid)
return numpy.array(centroidList).tolist()
#计算簇集合间的均方误差,将簇类中各个向量与质心的距离进行累加求和
def getVar(clusterDict,centroidList):
sum = 0.0
for key in clusterDict.keys():
vec1 = numpy.array(centroidList[key])
distance = 0.0
for item in clusterDict[key]:
vec2 = numpy.array(item)
distance += calcuDistance(vec1,vec2)
sum += distance
return sum #展示聚类结果
def showCluster(centroidList,clusterDict):
colorMark = ['or','ob','og','ok','oy','ow']
#不同簇类的标记,'or'-->'o'代表圆形,’r'代表red,‘b’:blue
centroidMark = ['dr','db','dg','dk','dy','dw'] #簇类中心标记同上‘d’代表菱形
for key in clusterDict.keys():#画簇类中心点
plt.plot(centroidList[key][0],centroidList[key][1],centroidMark[key],markersize=12)
for item in clusterDict[key]:
plt.plot(item[0],item[1],colorMark[key])#画簇类下的点
plt.show() if __name__=='__main__':
# inFile = "F:/testSet.txt" #数据集文件
dataSet = loadDataSet() #载入数据集
centroidList = initCentroids(dataSet,4) #初始化质心,设置K=4
clusterDict = minDistance(dataSet,centroidList) #第一次聚类迭代
newVar = getVar(clusterDict,centroidList) #获得均方误差值,通过新旧均方误差来获得迭代终止条件
oldVar = -0.0001 #旧均方误差值初始化为-1
print("------第一次迭代------")
print( )
print("簇类")
for key in clusterDict.keys():
print(key,'---->',clusterDict[key])
print("K个均值向量:",centroidList)
print("平方均方误差:",newVar)
print( )
showCluster(centroidList,clusterDict) #展示聚类结果
k = 2
while abs(newVar-oldVar) >= 0.0001: #当两次聚类结果小于0.0001时,迭代结束
centroidList = getCentroids(clusterDict) #获得新的质心
clusterDict = minDistance(dataSet,centroidList) #新的聚类结果
oldVar = newVar
newVar = getVar(clusterDict,centroidList)
print("----第%d次迭代结果--------" %k)
print( )
print("簇类")
for key in clusterDict.keys():
print(key, '---->', clusterDict[key])
print("K个均值向量:", centroidList)
print("平方均方误差:", newVar)
print()
showCluster(centroidList, clusterDict) # 展示聚类结果
k += 1
目前,对于聚类算法的理解还不是很深刻。正在慢慢探索中。
K-means算法的实现的更多相关文章
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- C++基础代码--20余种数据结构和算法的实现
C++基础代码--20余种数据结构和算法的实现 过年了,闲来无事,翻阅起以前写的代码,无意间找到了大学时写的一套C++工具集,主要是关于数据结构和算法.以及语言层面的工具类.过去好几年了,现在几乎已经 ...
- Python八大算法的实现,插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序。
Python八大算法的实现,插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得 ...
- 图像数据到网格数据-2——改进的SMC算法的实现
概要 本篇接上一篇继续介绍网格生成算法,同时不少内容继承自上篇.上篇介绍了经典的三维图像网格生成算法MarchingCubes,并且基于其思想和三角形表实现了对样例数据的网格构建.本篇继续探讨网格生成 ...
- Bug2算法的实现(RobotBASIC环境中仿真)
移动机器人智能的一个重要标志就是自主导航,而实现机器人自主导航有个基本要求--避障.之前简单介绍过Bug避障算法,但仅仅了解大致理论而不亲自动手实现一遍很难有深刻的印象,只能说似懂非懂.我不是天才,不 ...
- Canny边缘检测算法的实现
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波.我们知道微分运算是求信号的变化率,具有加强高频分量的作用.在空域运算中来说,对图像的锐化就是计算微分.由于数字图像的离散信号, ...
- SSE图像算法优化系列十三:超高速BoxBlur算法的实现和优化(Opencv的速度的五倍)
在SSE图像算法优化系列五:超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现) 一文中,我曾经说过优化后的ExpBlur比BoxBlur还要快,那个时候我比较的BoxBlur ...
- 详解Linux内核红黑树算法的实现
转自:https://blog.csdn.net/npy_lp/article/details/7420689 内核源码:linux-2.6.38.8.tar.bz2 关于二叉查找树的概念请参考博文& ...
- 详细MATLAB 中BP神经网络算法的实现
MATLAB 中BP神经网络算法的实现 BP神经网络算法提供了一种普遍并且实用的方法从样例中学习值为实数.离散值或者向量的函数,这里就简单介绍一下如何用MATLAB编程实现该算法. 具体步骤 这里 ...
- Python学习(三) 八大排序算法的实现(下)
本文Python实现了插入排序.基数排序.希尔排序.冒泡排序.高速排序.直接选择排序.堆排序.归并排序的后面四种. 上篇:Python学习(三) 八大排序算法的实现(上) 1.高速排序 描写叙述 通过 ...
随机推荐
- WPF Combobox选中事件
/// <summary> /// 选中事件 /// </summary> /// <param name="sender"></para ...
- 了解Python内存管理机制,让你的程序飞起来
引用: 语言的内存管理是语言设计的一个重要方面.它是决定语言性能的重要因素.无论是C语言的手工管理,还是Java的垃圾回收,都成为语言最重要的特征.这里以Python语言为例子,说明一门动态类型的.面 ...
- python tkinter chk
视频过程中的练习, 可以在python2.7下运行. 001: hello,world: 1 2 3 4 5 6 from Tkinter import Label, Tk root = Tk() t ...
- django之paginator
class Paginator(object):#分页器 def __init__(self, object_list, per_page, orphans=0, allow_empty_first_ ...
- Python linux 上的管理工具 pyenv 安装, pip 使用, python项目(版本分割, 项目分割, 虚拟环境创建)
01: 假设你有一个最小环境安装的 centos-6.x 的linux操作系统 02: 安装 git => yum -y install git 03: 安装依赖 => yum -y in ...
- oracle PL/SQL的介绍
转自:http://blog.sina.com.cn/s/blog_4c302f060101i4o1.html 一 PL/SQL的介绍 1 PL/SQL是什么? PL/SQL(procedural l ...
- MySQL 创建自定义函数
语法:Create function function_name(参数列表)returns返回值类型 函数体 函数名,应合法的标识符,不应与系统关键字冲突. 一个函数应该属于某个数据库,可以使用db_ ...
- setTimeout闭包常见问题
经常会遇到这样的问题,setTimeout按序输出循环数字,而不是最后输出同一个数字: 题目: for (var i = 0; i < 5; i++) { setTimeout(function ...
- linux 不同服务器之间复制文件
----------------------拷贝文件夹---------------------------------------------- 把当前文件夹tempA拷贝到 目标服务器10.127 ...
- R-CNN 学习记录
CNN是一个运用卷积神经网络进行图片分类的开山之作.RCNN是第一个把图片分类和目标检测连接起来的作品. RCNN主要解决的问题是: 1.怎样用深度神经网络进行目标定位:2.怎样用小批量的标注数据来训 ...