[ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法
回归树
决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射。
这时候就没法用信息增益、信息增益率、基尼系数来判定树的节点分裂了,那么回归树采用新的方式是预测误差,常用的有均方误差、对数误差等(损失函数)。而且节点不再是类别,而是数值(预测值),划分到叶子后的节点预测值有不同的计算方法,有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
XGBoost算法
XGBoost是由许多CART回归树集成。区别于随机森林的bagging集成,它是一种boosting集成学习(由多个相关联的决策树联合决策,下一棵决策树输入样本会与前面决策树的训练和预测相关)。它的目标是希望建立K个回归树,使得树群的预测值尽量接近真实值(准确率)而且有尽量大的泛化能力(寻求更为本质的东西)。
记w为叶子节点的权值,x为分类结果,则最终预测值 \(\hat{y}_i = \sum_j w_j x_{ij}\)。
设目标函数为 \(l(y_i,\hat{y}_i)=(y_i-\hat{y}_i)^2\)。
对于一组数值需要求平均,相当于求其期望 \(F^*(\overrightarrow{x})=argminE_{(x,y)}[L(y,F(\overrightarrow{x}))]\)
最终结果由多个弱分类器组成,集成的结果:\(\hat{y}_i = \sum_{k=1}^K f_k(x_i), \quad f_k\in F\)
XGBoost本质是提升树,也即每加一棵效果更好(目标函数更优)

定义正则化惩罚项 \(\Omega(f_t)=\gamma T+\frac{1}{2}\lambda \sum_{j=1}^T \omega_j^2\)(叶子个数 + w的L2正则项)
如何选择每一轮加入什么f(预测值->落入的叶子权值):选取使得目标函数尽量最大地降低(找到\(f_t\)来优化这一目标)
\[
\begin{split}
Obj^{(t)}&=\sum_{i=1}^n l(y_i,\hat{y}_i^{(t)})+\sum_{i=1}^n\Omega(f_i)\\
&=\sum_{i=1}^n l(y_i,\hat{y}_i^{(t-1)}+f_t(x_i))+ \Omega(f_t)+constant\\
&=\sum_{i=1}^n (y_i-(\hat{y}_i^{(t-1)}+f_t(x_i))^2+ \Omega(f_t)+constant\\
&=\sum_{i=1}^n [2(\hat{y}_i^{(t-1)}-y_i)f_t(x_i)+f_t(x_i)^2]+ \Omega(f_t)+constant\\
\end{split}
\]
用\(\hat{y}_i^{(t-1)}-y_i\) 描述前t-1棵的总预测值与真实值之间的差异(残差),因此梯度提升决策树也称残差决策树。
目标函数Obj是一个队树结构进行打分的函数(结构分数 structure score),分数越小代表树结构越好。用泰勒展开近似求解:
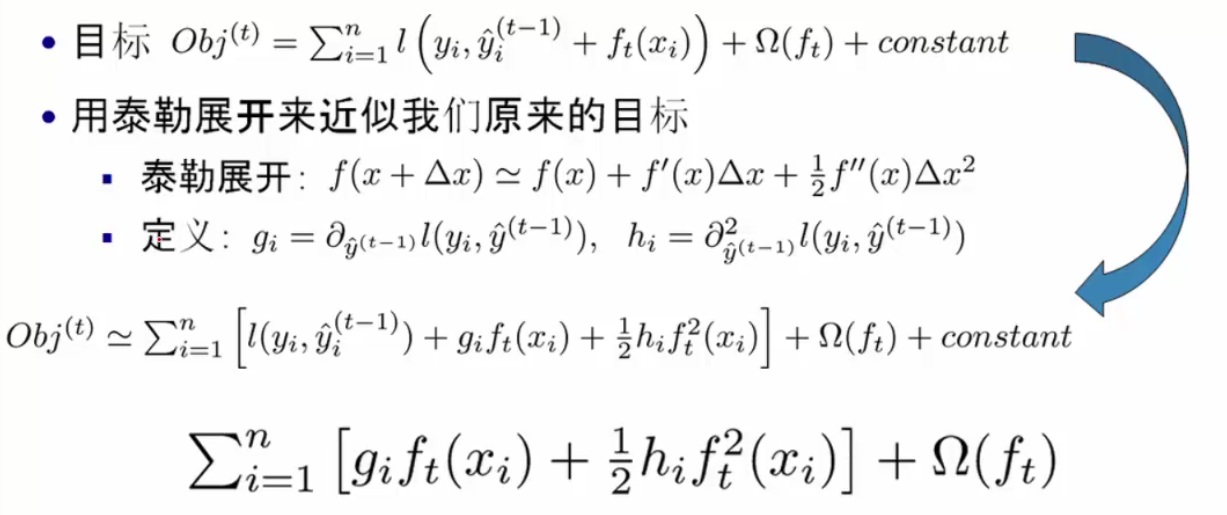
由对样本的遍历变换为对叶节点的遍历
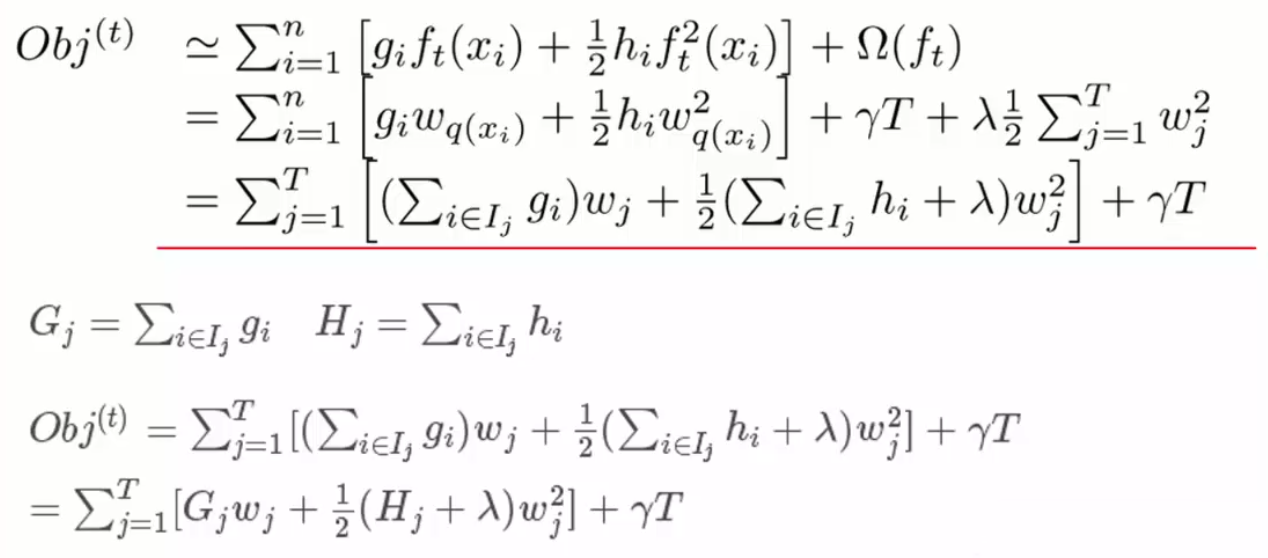

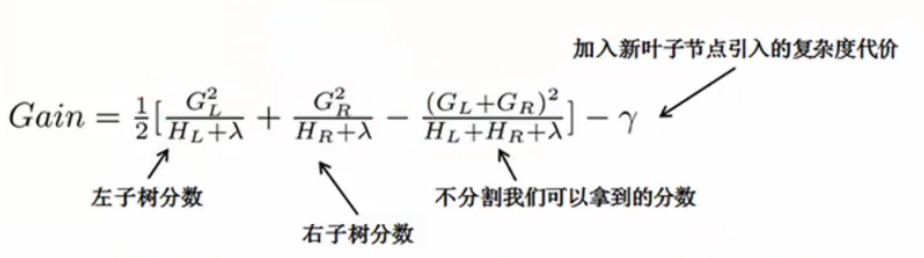
单节点怎么切分(分叉):枚举所有可能的分割方案,假设要枚举所有x<a这样的条件,对于某个特性的分割a,分别计算切割前和分割后的差值以求增益。
推荐阅读:
- 陈天奇博士的文章 Introduction to Boosted Trees (附:原PPT地址、中文笔记博客)
[ML学习笔记] XGBoost算法的更多相关文章
- [ML学习笔记] 朴素贝叶斯算法(Naive Bayesian)
[ML学习笔记] 朴素贝叶斯算法(Naive Bayesian) 贝叶斯公式 \[P(A\mid B) = \frac{P(B\mid A)P(A)}{P(B)}\] 我们把P(A)称为"先 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- [ML学习笔记] 回归分析(Regression Analysis)
[ML学习笔记] 回归分析(Regression Analysis) 回归分析:在一系列已知自变量与因变量之间相关关系的基础上,建立变量之间的回归方程,把回归方程作为算法模型,实现对新自变量得出因变量 ...
- 学习笔记 - Manacher算法
Manacher算法 - 学习笔记 是从最近Codeforces的一场比赛了解到这个算法的~ 非常新奇,毕竟是第一次听说 \(O(n)\) 的回文串算法 我在 vjudge 上开了一个[练习],有兴趣 ...
- ML学习笔记之Anaconda中命令形式安装XGBoost(pip install)
0x00 概述 在没有安装XGBoost之前,import xgboot会出错,如下: # ModuleNotFoundError: No module named ‘xgboost’ 0x01 安装 ...
- ML学习笔记之XGBoost实现对鸢尾花数据集分类预测
import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import tra ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 学习笔记-KMP算法
按照学习计划和TimeMachine学长的推荐,学习了一下KMP算法. 昨晚晚自习下课前粗略的看了看,发现根本理解不了高端的next数组啊有木有,不过好在在今天系统的学习了之后感觉是有很大提升的了,起 ...
随机推荐
- Java 并发编程常识 —— by 梁飞
参考 :梁飞 并发编程常识
- 使用VS2013 + EF6 连接Mysql数据库
使用VS2013 + EF6 + .NET4.5 连接Mysql数据库 1.安装插件 在使用Visual Studio 2013添加ADO.NET实体数据模型新建连接时,默认是没有Mysql选项的.此 ...
- Java并发编程:什么是线程安全,以及并发必须知道的几个概念
废话 众所周知,在Java的知识体系中,并发编程是非常重要的一环,也是面试的必问题,一个好的Java程序员是必须对并发编程这块有所了解的.为了追求成为一个好的Java程序员,我决定从今天开始死磕Jav ...
- css优化,提高性能
CSS 优化主要是四个方面: 加载性能比如不要用 @import 等等,@import会影响css文件的加载速度,考虑加载性能时,主要是从减少文件体积.减少阻塞加载.提高并发方面入手,任何 hint ...
- Software-Defined Networking A Comprehensive Survey --阅读_day2
3. 什么是SDN?(WHAT IS SOFTWARE-DEFINED NETWORKING?) The term SDN was originally coined to represent the ...
- JPA、ORM
JPA:全称:Java Persistence API 解释:Java持久层API (接口规范) ORM映射元数据 JPA支持XML和JDK5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系 ...
- H5 页面下拉加载更多
1.html页面: <body onload="index_roll()"> ... </body> 2.js <script type=" ...
- 【代码笔记】iOS-自定义选择框(高底强弱)
一,效果图 二,代码. ViewController.h #import <UIKit/UIKit.h> @interface ViewController : UIViewControl ...
- 【代码笔记】iOS-performSelectorOnMainThread
代码: RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController : UIViewControl ...
- 将textarea实现自适应高度及IE下滚动条不出现的bug
1.<el-table-column label="备注" width="180"> <template scope="scope& ...