10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)
转载请出自出处:http://www.cnblogs.com/hd3013779515/
1.创建MySQL数据
create database solr;
use solr;
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id char(10) NOT NULL,
stu_name varchar(50) DEFAULT NULL,
stu_sex int(1) DEFAULT NULL,
stu_address varchar(200) DEFAULT NULL,
updateTime timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
isDeleted int(1) DEFAULT 0,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO student VALUES ('', '李莉', 0, '上海市中山路',default,default);
INSERT INTO student VALUES ('', 'Tom', 1, 'NewYork',default,default);
INSERT INTO student VALUES ('', '张小贝', 0, '江西省泰和县中山路',default,default);
INSERT INTO student VALUES ('', '鲍勃', 1, '北京市海淀区知春路',default,default);
INSERT INTO student VALUES ('', 'Tim', 0, 'Paris',default,default);
select * from student;
2. DIH全量从MYSQL数据库导入数据
1)配置/home/solrhome/collection1/conf/solrconfig.xml
vim /home/solrhome/collection1/conf/solrconfig.xml
在<requestHandler name="/select" class="solr.SearchHandler">前面上加上一个dataimport的处理的Handler
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
2)在同目录下添加data-config.xml
vim /home/solrhome/collection1/conf/data-config.xml
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.137.168:3306/solr" user="root" password="root" batchSize="-1" /> <document name="testDoc"> <entity name="student" pk="id" query="select * from student"> <field column="id" name="id"/> <field column="stu_name" name="stu_name"/> <field column="stu_sex" name="stu_sex"/> <field column="stu_address" name="stu_address"/> </entity> </document> </dataConfig>
说明:
dataSource是数据库数据源。
Entity就是一张表对应的实体,pk是主键,query是查询语句。
Field对应一个字段,column是数据库里的column名,后面的name属性对应着Solr的Filed的名字。
3)修改同目录下的schema.xml,这是Solr对数据库里的数据进行索引的模式
vim /home/solrhome/collection1/conf/schema.xml
<field name="stu_name" type="text_ik" indexed="true" stored="true" multiValued="false" /> <field name="stu_sex" type="int" indexed="true" stored="true" multiValued="false" /> <field name="stu_address" type="text_ik" indexed="true" stored="true" multiValued="false" />
4)拷贝关联jar
拷贝mysql-connector-java-3.1.13-bin.jar和solr-dataimporthandler-4.10.3.jar
cp /usr/local/solr-4.10.3/dist/solr-dataimporthandler-4.10.3.jar /home/tomcat6/webapps/solr/WEB-INF/lib/
cp /home/test/mysql-connector-java-3.1.13-bin.jar /home/tomcat6/webapps/solr/WEB-INF/lib/
5)重启Solr
如果配置正确就可以启动成功。
solrconfig.xml是solr的基础文件,里面配置了各种web请求处理器、请求响应处理器、日志、缓存等。
schema.xml配置映射了各种数据类型的索引方案。分词器的配置、索引文档中包含的字段也在此配置。
6)索引测试
(1)Solr控制台导入
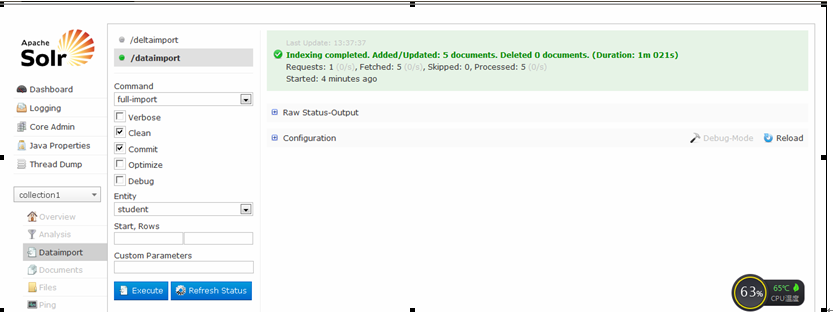

(2)HTTP方式导入
http://192.168.137.168:8080/solr/collection1/dataimport?command=full-import&commit=true&clean=false
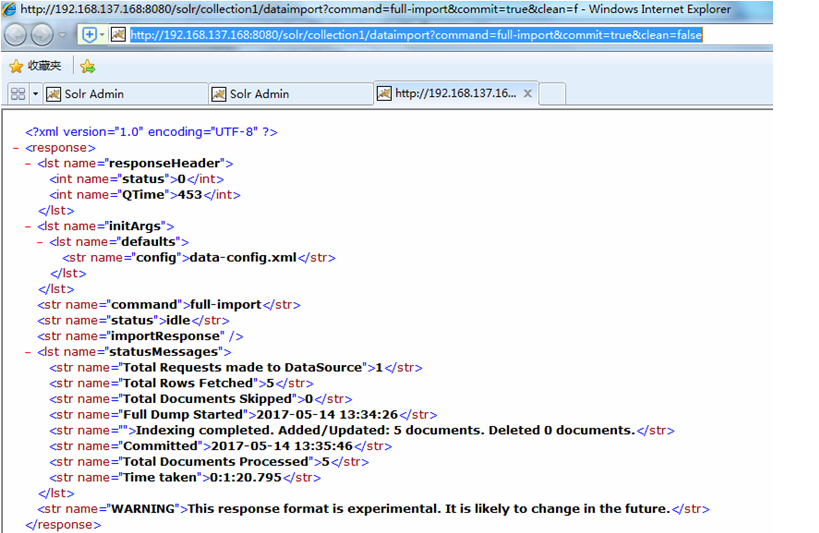
7)分批次导入数据
如果数据库数据太大,可以分批次导入数据。
vim /home/solrhome/collection1/conf/data-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.137.168:3306/solr" user="root" password="root" batchSize="-1" />
<document name="testDoc">
<entity name="student" pk="id"
query="select * from student limit ${dataimporter.request.length} offset ${dataimporter.request.offset}">
<field column="id" name="id"/>
<field column="stu_name" name="stu_name"/>
<field column="stu_sex" name="stu_sex"/>
<field column="stu_address" name="stu_address"/>
</entity>
</document>
</dataConfig>
上面主要是通过内置变量 “${dataimporter.request.length}”和 “${dataimporter.request.offset}”来设置一个批次索引的数据表记录数,请求的URL示例如下:

导入效果如下

3.DIH增量从MYSQL数据库导入数据
已经学会了如何全量导入MySQL的数据,全量导入在数据量大的时候代价非常大,一般来说都会适用增量的方式来导入数据,下面介绍如何增量导入MYSQL数据库中的数据,以及如何设置定时来做。
特别注意:DIH增量也是可以做全量数据导入,所以生产环境只要设置DIH增量方式。
1)数据库表的更改
新增一个字段updateTime,类型为timestamp,默认值为CURRENT_TIMESTAMP。有了这样一个字段,Solr才能判断增量导入的时候,哪些数据是新的。因为Solr本身有一个默认值last_index_time,记录最后一次做full import或者是delta import(增量导入)的时间,这个值存储在文件conf目录的dataimport.properties文件中。
more dataimport.properties

2)data-config.xml中必要属性的设置
vim /home/solrhome/collection1/conf/data-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.137.168:3306/solr" user="root" password="root" batchSize="-1" />
<document name="testDoc">
<entity name="student" pk="id"
query="select * from student where isDeleted=0"
deltaImportQuery="select * from student where id='${dih.delta.id}'"
deltaQuery="select id from student where updateTime> '${dataimporter.last_index_time}' and isDeleted=0"
deletedPkQuery="select id from student where isDeleted=1">
<field column="id" name="id"/>
<field column="stu_name" name="stu_name"/>
<field column="stu_sex" name="stu_sex"/>
<field column="stu_address" name="stu_address"/>
</entity>
</document>
</dataConfig>
transformer 格式转化:HTMLStripTransformer 索引中忽略HTML标签
query:查询数据库表符合记录数据
deltaQuery:增量索引查询主键ID 注意这个只能返回ID字段
deltaImportQuery:增量索引查询导入的数据
deletedPkQuery:增量索引删除主键ID查询 注意这个只能返回ID字段
增量索引的原理是从数据库中根据deltaQuery指定的SQL语句查询出所有需要增量导入的数据的ID号。
然后根据deltaImportQuery指定的SQL语句返回所有这些ID的数据,即为这次增量导入所要处理的数据。
核心思想是:通过内置变量“${dih.delta.id}”和 “${dataimporter.last_index_time}”来记录本次要索引的id和最近一次索引的时间。
如果业务中还有删除操作,可以在数据库中加一个isDeleted字段来表明该条数据是否已经被删除,这时候Solr在更新index的时候,可以根据这个字段来更新哪些已经删除了的记录的索引。
3)测试增量导入
DIH全量导入
http://192.168.137.168:8080/solr/collection1/dataimport?command=full-import&commit=true&clean=true


修改student数据
update student set stu_name="jerry" where id = '';
update student set isDeleted=1 where id = '';
INSERT INTO student VALUES ('', 'Tim11', 0, 'Paris',default,default);
DIH增量导入数据
http://192.168.137.168:8080/solr/collection1/dataimport?command=delta-import


4)设置增量导入为定时执行的任务
可以用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题。
但是更方便,更加与Solr本身集成度高的是利用其自身的定时增量导入功能。
1.增加关联jar
cp /home/test/apache-solr-dataimportscheduler.jar /home/tomcat6/webapps/solr/WEB-INF/lib/
2、修改solr的WEB-INF目录下面的web.xml文件:
vim /home/tomcat6/webapps/solr/WEB-INF/web.xml
为<web-app>元素添加一个子元素
<listener> <listener-class> org.apache.solr.handler.dataimport.scheduler.ApplicationListener </listener-class> </listener>
3、新建配置文件dataimport.properties:
在SOLR_HOME\solr目录下面新建一个目录conf(注意不是SOLR_HOME\solr\collection1下面的conf)
mkdir /home/solrhome/conf
vim /home/solrhome/conf/dataimport.properties
下面是最终我的自动定时更新配置文件内容:
################################################# # # # dataimport scheduler properties # # # ################################################# # to sync or not to sync # 1 - active; anything else - inactive syncEnabled=1 # which cores to schedule # in a multi-core environment you can decide which cores you want syncronized # leave empty or comment it out if using single-core deployment # syncCores=game,resource syncCores=collection1 # solr server name or IP address # [defaults to localhost if empty] server=192.168.137.168 # solr server port # [defaults to 80 if empty] port=8080 # application name/context # [defaults to current ServletContextListener's context (app) name] webapp=solr # URLparams [mandatory] # remainder of URL #http://localhost:8983/solr/collection1/dataimport?command=delta-import&clean=false&commit=true params=/dataimport?command=delta-import&clean=false&commit=true # schedule interval # number of minutes between two runs # [defaults to 30 if empty] interval=1 # 重做索引的时间间隔,单位分钟,默认7200,即1天; # 为空,为0,或者注释掉:表示永不重做索引 reBuildIndexInterval=2 # 重做索引的参数 reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true # 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000; # 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期 reBuildIndexBeginTime=03:10:00
4、测试
重启tomcat
一般来说要在你的项目中引入Solr需要考虑以下几点:
1、数据更新频率:每天数据增量有多大,及时更新还是定时更新
2、数据总量:数据要保存多长时间
3、一致性要求:期望多长时间内看到更新的数据,最长允许多长时间延迟
4、数据特点:数据源包括哪些,平均单条记录大小
5、业务特点:有哪些排序要求,检索条件
6、资源复用:已有的硬件配置是怎样的,是否有升级计划
参考http://www.cnblogs.com/luxiaoxun/p/4442770.html
10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)的更多相关文章
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
- Canal——增量同步MySQL数据到ElasticSearch
1.准备 1.1.组件 JDK:1.8版本及以上: ElasticSearch:6.x版本,目前貌似不支持7.x版本: Kibana:6.x版本: Canal.deployer:1 ...
- Mysql备份系列(3)--innobackupex备份mysql大数据(全量+增量)操作记录
在日常的linux运维工作中,大数据量备份与还原,始终是个难点.关于mysql的备份和恢复,比较传统的是用mysqldump工具,今天这里推荐另一个备份工具innobackupex.innobacku ...
- Mysql备份系列(4)--lvm-snapshot备份mysql数据(全量+增量)操作记录
Mysql最常用的三种备份工具分别是mysqldump.Xtrabackup(innobackupex工具).lvm-snapshot快照.前面分别介绍了:Mysql备份系列(1)--备份方案总结性梳 ...
- paip.将数据导入到在英语语音数据库mysql道路解决空原则问题
paip.将数据导入到在英语语音数据库mysql道路解决空原则问题 #---原因:mysql 导入工具bug #---解决:不要使用双引号括注音. 笔者 老哇爪 Attilax 艾龙. EMAIL: ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- Mysql备份系列(2)--mysqldump备份(全量+增量)方案操作记录
在日常运维工作中,对mysql数据库的备份是万分重要的,以防在数据库表丢失或损坏情况出现,可以及时恢复数据. 线上数据库备份场景:每周日执行一次全量备份,然后每天下午1点执行MySQLdump增量备份 ...
随机推荐
- while和if的区别
while用于循环语句,而if用于判断和分支语句.由于你并没有指明是什么程序,只能泛泛而谈了.if 语句中,常用格式为:if(判断条件){执行语句}上面的结构,只是进行一次判断.if与else结合,就 ...
- 漫画 | Java多线程与并发(一)
1.什么是线程? 2.线程和进程有什么区别? 3.如何在Java中实现线程? 4.Java关键字volatile与synchronized作用与区别? volatile修饰的变量不保留拷贝,直接访问主 ...
- Spring 概念
spring概念 1.spring是一个开源的轻量级的开源框架. 2.spring的核心主要分为两部分: (1)aop:面向切面编程,扩展功能不是修改源代码实现. (2)ioc:控制反转,比如有一个类 ...
- 阿里云数据库配置学习笔记(二):下载并配置MySQL数据库
参考资料:阿里云官方文档 2018-02-20 一.MySQL数据库的下载 在Ubuntu环境下安装MySQL数据库十分简单 在命令行中输入 sudo apt-get update(更新软件源,预防出 ...
- mysql count(*) vs count(1)
perfer count(*) 官方文档: _InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way ...
- php面向对象精要(3)
1,final关键字定义的方法,不能被重写 由于final修饰了show方法,子类中重写show方法会报错 <?php class MyClass { final function show() ...
- HDU4704(SummerTrainingDay04-A 欧拉降幂公式)
Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Submi ...
- win7游戏窗口设置
在开始搜索框输入regedit打开注册表,定位到HKEY_LOCAL_MACHINE------SYSTEM------ControlSet001-------Control-------Graphi ...
- redis下载地址
redisgithub下载地址:https://github.com/MicrosoftArchive/redis进入之后,如下所示进行下载. 进入页面进行选择版本下载. ,下载好之后,在本地解压如下 ...
- [WPF 基础知识系列] —— 绑定中的数据校验Vaildation
前言: 只要是有表单存在,那么就有可能有对数据的校验需求.如:判断是否为整数.判断电子邮件格式等等. WPF采用一种全新的方式 - Binding,来实现前台显示与后台数据进行交互,当然数据校验方式也 ...