Hadoop 架构初探
对流行Hadoop做了一些最基本的了解,暂时没太大感觉,恩先记点笔记吧. = =
Hadoop 基本命令及环境安装
一、下载虚拟机镜像
目前比较流行的有以下三个:
(CHD) http://www.cloudera.com
(HDP) http://hortonworks.com/
(MapR) http://www.mapr.com
本文使用HDP的沙盘
下载地址 http://hortonworks.com/products/hortonworks-sandbox/#install
我使用的是 Hyper-V 的镜像 , 配置可以查看下载地址旁边的文档
二、使用HDP沙盘
- 显示指定路径的文件和目录
注意这里显示的hdfs的文件目录不是实际机器中的文件目录hadoop fs -ls /
- 建立一个目录并下载数据
mkdir /home/bihell
wget http://www.grouplens.org/system/files/ml-100k.zip
unzip ml-100k.zip - 在Hadoop中建立目录
hadoop fs -mkdir /bihell/
hadoop fs -mkdir /bihell/movies
hadoop fs -mkdir /bihell/userinfo - Hadoop文件操作
hadoop支持两个文件系统命令fs put 命令可以把文件传送到hadoop的文件系统,而fs get 命令可以从hadoop中获取文件
hadoop fs -put u.item /bihell/movies
hadoop fs -put u.info /bihell/userinfo另外还有一个拷贝命令 fs –cp
hadoop fs -cp /bihell/movies/u.item /bihell
删除命令 fs -rm
hadoop fs -rm /bihell/u.item
拷贝多个文件
hadoop fs -mkdir /bihell/test
hadoop fs -cp /bihell/movies/u.item /bihell/userinfo/u.info /bihell/test递归删除文件
hadoop fs -rm -r -skipTrash /bihell/test
显示文件内容
hadoop fs -cat /bihell/movies/* |less
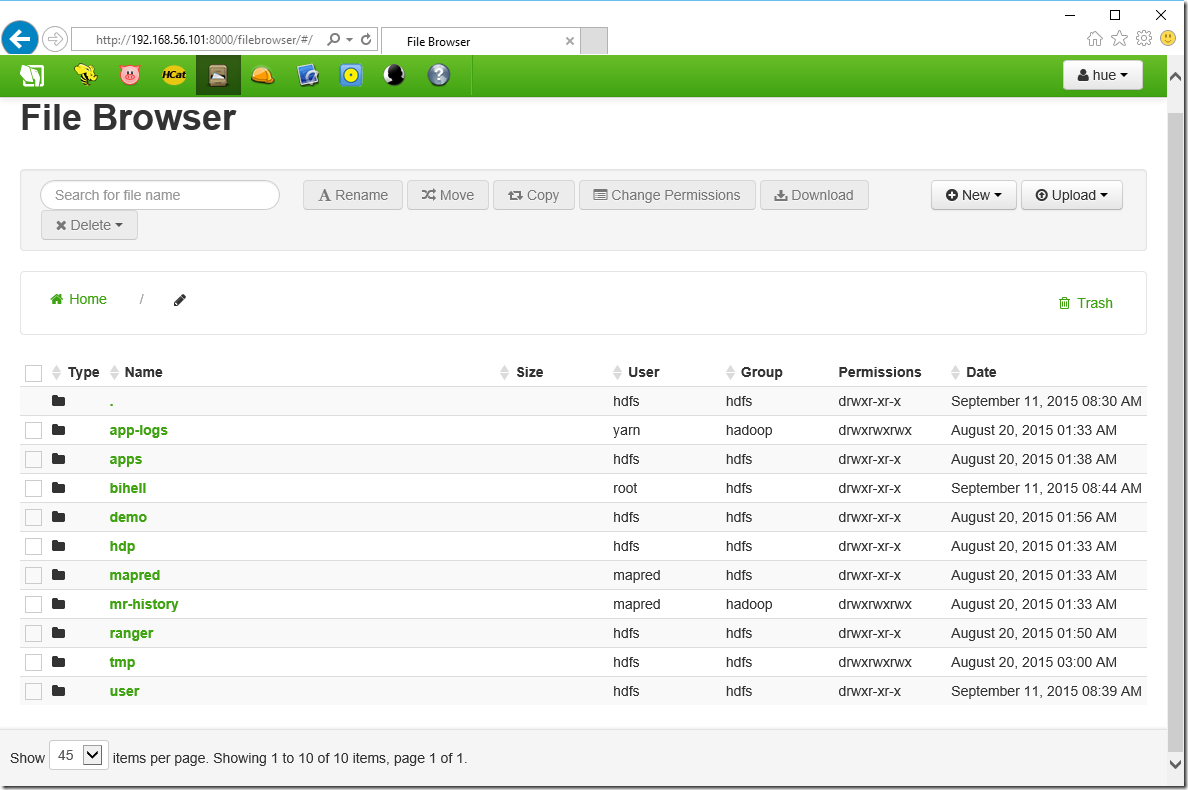
三、 使用hue ui 的文件浏览器操作文件
根据沙盘的提示访问 http://192.168.56.101:8000/filebrowser/#/ 我们可以看到刚才建立的目录。 (还是UI方便点啊)
使用Hive并且将数据导入仓库
一、先看一下Demo里面的Hive目录
hadoop fs -ls /apps/hive/warehouse
Found 3 items
drwxrwxrwx - hive hdfs 0 2015-08-20 09:05 /apps/hive/warehouse/sample_07
drwxrwxrwx - hive hdfs 0 2015-08-20 09:05 /apps/hive/warehouse/sample_08
drwxrwxrwx - hive hdfs 0 2015-08-20 08:58 /apps/hive/warehouse/xademo.db
hadoop fs -ls /apps/hive/warehouse/sample_07
Found 1 items
-rwxr-xr-x 1 hue hue 46055 2015-08-20 08:46 /apps/hive/warehouse/sample_07/sample_07
查看文件内容
hadoop fs -cat /apps/hive/warehouse/sample_07/sample_07 | less
二、使用hive命令
进入hive数据库
hive
显示hive中的数据库
show databases;
显示表格
show tables;
show tables '*08*';
清空屏幕
!clear;
进一步查看表格结构
describe sample_07;
describe extended sample_07 ;
创建数据库
create database bihell;
使用hadoop fs命令查看下hive 目录,我们刚才创建的数据库文件应该在里面了
!hadoop fs -ls /apps/hive/warehouse/;
结果如下:
Found 4 items
drwxrwxrwx - root hdfs 0 2015-09-12 08:57 /apps/hive/warehouse/bihell.db
drwxrwxrwx - hive hdfs 0 2015-08-20 09:05 /apps/hive/warehouse/sample_07
drwxrwxrwx - hive hdfs 0 2015-08-20 09:05 /apps/hive/warehouse/sample_08
drwxrwxrwx - hive hdfs 0 2015-08-20 08:58 /apps/hive/warehouse/xademo.db
三、使用建立的数据库
一直用命令行比较吃力,我们也可用ui界面
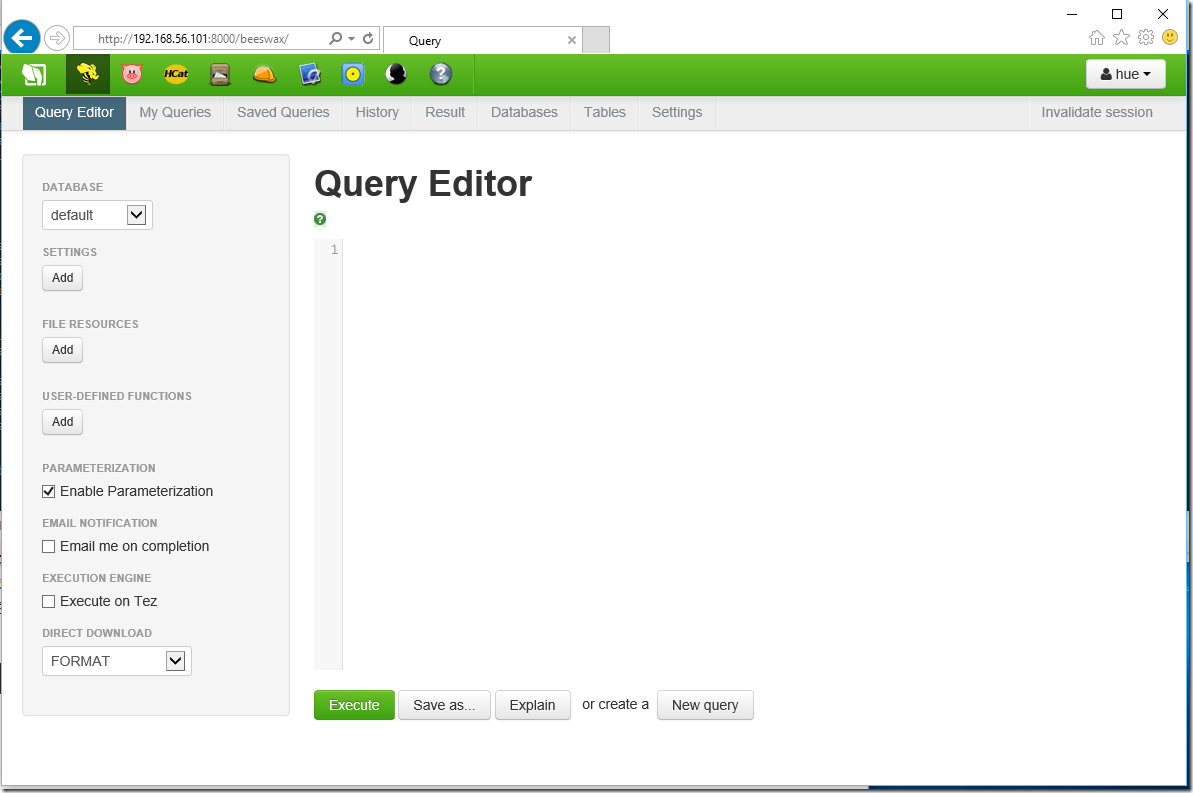
在我们新建的bihell数据库中建立表格
CREATE TABLE movies (
movie_id INT,
movie_title STRING,
release_date STRING,
video_release_date STRING,
imdb_url STRING,
unknown INT,
action INT,
adventure INT,
animation INT,
children INT,
comedy INT,
crime INT,
documentary INT,
drama INT,
fantasy INT,
film_noir INT,
horror INT,
musical INT,
mystery INT,
romance INT,
sci_fi INT,
thriller INT,
war INT,
Western INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
创建完毕以后点击Tables可以看到我们刚才创建的表格
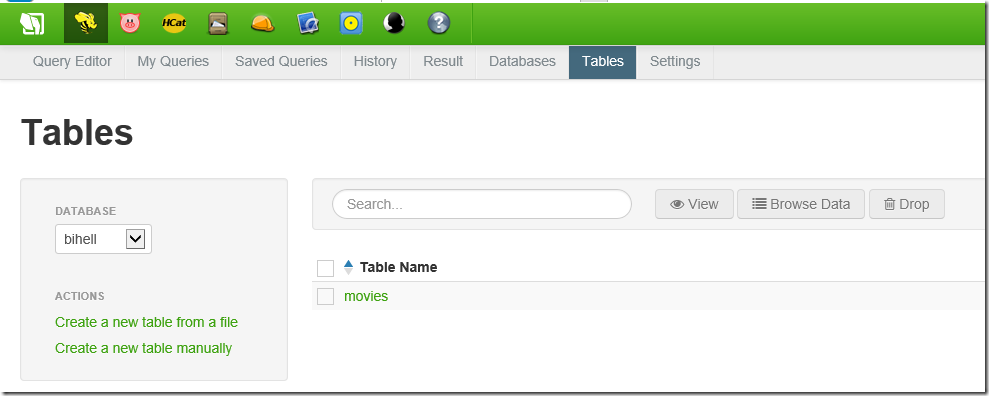
在SSH执行文件命令,我们可以看到bihell.db下面多了一个目录
hadoop fs -ls /apps/hive/warehouse/bihell.db
Found 1 items
drwxrwxrwx - hive hdfs 0 2015-09-12 09:09 /apps/hive/warehouse/bihell.db/movies
四、进入hive ,我们导入一些数据进去
导入数据
lOAD DATA INPATH '/bihell/userinfo' INTO TABLE movies;
清空数据
truncate table movies;
导入并覆盖原有数据
load data inpath '/bihell/movies' overwrite into table movies;
四、建立External表与RCFile 表
前面我们建立表以后导入数据到表中, 目录中的文件会被删除,现在我们直接建立表并指向我们所在的文件目录,建立外部表.
复原文件
!hadoop fs -put /home/bihell/ml-100k/u.user /bihell/userinfo;
建立另外一个表格,注意有指定路径
CREATE EXTERNAL TABLE users (
user_id INT,
age INT,
gender STRING,
occupation STRING,
zip_code STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION '/bihell/userinfo';
查看users的schema
describe formatted users;
查询表
SELECT * FROM users limit 100;
创建 RCFile 表格
CREATE TABLE occupation_count
STORED AS RCFile
AS SELECT COUNT(*), occupation FROM users GROUP BY occupation;
引用另外一个表创建一个空表
CREATE TABLE occupation2 LIKE occupation_count;
Hive 查询语言
我们之前已经用了部分hive查询,现在深入一下
一、复杂类型
Arrays – ARRAY<data_type>
Maps -- MAP<primitive,data_type>
Struct -- STRUCT<col_name:data_type[COMMENT col_comment],…>
Union Type – UNIONYTPE<data_type,data_type,…>
create table movies (
movie_name string,
participants ARRAY <string>,
release_dates MAP <string,timestamp>,
studio_addr STRUCT <state:string,city:string,zip:string,streetnbr:int,streetname:string,unit:string>,
complex_participants MAP<string,STRUCT<address:string,attributes MAP<string,string>>>
misc UNIONTYPE <int,string,ARRAY<double>>
);
查询方式
select movie_name,
participants[0],
release_dates[“USA”],
studio_addr.zip,
complex_participants[“Leonardo DiCaprio”].attributes[“fav_color”],
misc
from movies;
二、Partitioned Tables
这个章节主要讲述加载与管理Hive中的数据
前面我们使用了CREATE TABLE 以及 CREATE EXTERNAL TABLE 本文我们要看下Table Partitions
创建分区表:
CREATE TABLE page_views( eventTime STRING, userid STRING)
PARTITIONED BY (dt STRING, applicationtype STRING)
STORED AS TEXTFILE;
数据库文件默认地址 :
/apps/hive/warehouse/page_views
当你每次导入数据的时候都会为你建立partition ,比如
LOAD DATA INPATH ‘/mydata/android'/Aug_10_2013/pageviews/’
INTO TABLE page_views
PARTITION (dt = ‘2013-08-10’, applicationtype = ‘android’);
生成分区如下:
/apps/hive/warehouse/page_views/dt=2013-08-10/application=android
当然我们也可以覆盖导入
LOAD DATA INPATH ‘/mydata/android'/Aug_10_2013/pageviews/’
OVERWRITE INTO TABLE page_views
PARTITION (dt = ‘2013-08-10’, applicationtype = ‘android’);
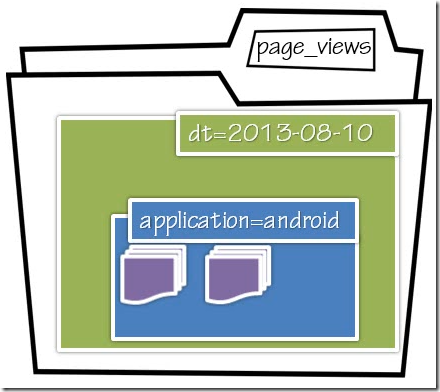
创建语句中dt和applicationtype 是virtual partition columns. 如果你describe table,会发现所有字段显示和正常表一样
eventTime STRING
userid STRING
page STRING
dt STRING
applicationtype STRING
可以直接用于查询
select dt as eventDate,page,count(*) as pviewCount From page_views
where applicationtype = ‘iPhone’;
三、External Partitioned Tables
相比分区表,只是多了一个EXTERNAL ,我们注意到这里没有指定location ,添加文件的时候才需要指定
CREATE EXTERNAL TABLE page_views( eventTime STRING, userid STRING)
PARTITIONED BY (dt STRING, applicationtype STRING)
STORED AS TEXTFILE;
添加文件
ALTER TABLE page_views ADD PARTITION ( dt = ‘2013-09-09’, applicationtype = ‘Windows Phone 8’)
LOCATION ‘/somewhere/on/hdfs/data/2013-09-09/wp8’; ALTER TABLE page_view ADD PARTITION (dt=’2013-09-09’,applicationtype=’iPhone’)
LOCATION ‘hdfs://NameNode/somewhere/on/hdfs/data/iphone/current’; ALTER TABLE page_views ADD IF NOT EXSTS
PARTITION (dt=’2013-09-09’,applicationtype=’iPhone’) LOCATION ‘/somewhere/on/hdfs/data/iphone/current’;
PARTITION (dt=’2013-09-08’,applicationtype=’iPhone’) LOCATION ‘/somewhere/on/hdfs/data/prev1/iphone;
PARTITION (dt=’2013-09-07’,applicationtype=’iPhone’) LOCATION ‘/somewhere/on/hdfs/data/iphone/prev2;
四、实际操作
EXTERNAL PARTITION TABLE
--建立目录
hadoop fs -mkdir /bihell/logs/pv_ext/somedatafor_7_11 /bihell/logs/pv_ext/2013/08/11/log/data --建立EXTERNAL TABLE
CREATE EXTERNAL TABLE page_views_ext (logtime STRING, userid INT, ip STRING, page STRING, ref STRING, os STRING, os_ver STRING, agent STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/bihell/logs/pv_ext/'; --查看表格详细信息
DESCRIBE FORMATTED page_views_ext; --查看执行计划
EXPLAIN SELECT * FROM page_views_ext WHERE userid = 13; --删除表
DROP TABLE page_views_ext; --创建EXTERNAL Partition Table
CREATE EXTERNAL TABLE page_views_ext (logtime STRING, userid INT, ip STRING, page STRING, ref STRING, os STRING, os_ver STRING, agent STRING)
PARTITIONED BY (y STRING, m STRING, d STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/bihell/logs/pv_ext/'; --将日志传送至Hadoop目录
!hadoop fs -put /media/sf_VM_Share/LogFiles/log_2013711_155354.log /bihell/logs/pv_ext/somedatafor_7_11 --因为是partition table 所以此时查询该表是没有任何内容的
SELECT * FROM page_views_ext; --添加文件
ALTER TABLE page_views_ext ADD PARTITION (y='2013', m='07', d='11')
LOCATION '/bihell/logs/pv_ext/somedatafor_7_11'; --再次查询
SELECT * FROM page_views_ext LIMIT 100; --describe table
DESCRIBE FORMATTED page_views_ext; --再次查看执行计划
我们发现predicate还是13, 并没有加上 m,d
EXPLAIN SELECT * FROM page_views_ext WHERE userid=13 AND m='07'AND d='11' LIMIT 100; --再添加一个文件
!hadoop fs -put /media/sf_VM_Share/LogFiles/log_2013811_16136.log /bihell/logs/pv_ext/2013/08/11/log/data
ALTER TABLE page_views_ext ADD PARTITION (y='2013', m='08', d='11')
LOCATION '/bihell/logs/pv_ext/2013/08/11/log/data'; --查询
SELECT COUNT(*) as RecordCount, m FROM page_views_ext WHERE d='11' GROUP BY m; --另一种方式添加数据
!hadoop fs -put /media/sf_VM_Share/LogFiles/log_2013720_162256.log /bihell/logs/pv_ext/y=2013/m=07/d=20/data.log
SELECT * FROM page_views_ext WHERE m='07' AND d='20' LIMIT 100;
MSCK REPAIR TABLE page_views_ext;
SELECT * FROM page_views_ext WHERE m='07' AND d='20' LIMIT 100;
PARTITION TABLE
CREATE TABLE page_views (logtime STRING, userid INT, ip STRING, page STRING, ref STRING, os STRING, os_ver STRING, agent STRING)
PARTITIONED BY (y STRING, m STRING, d STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'; LOAD DATA LOCAL INPATH '/media/sf_VM_Share/LogFiles/log_2013805_16210.log'
OVERWRITE INTO TABLE page_views PARTITION (y='2013', m='08', d='05'); !hadoop fs -ls /apps/hive/warehouse/bihell.db/page_views/;
批量插入及动态分区表插入
Multiple Inserts
--Syntax
FROM form_statement
INSERT OVERWRITE TABLE table1 [PARTITION(partcol1=val1,partcol2=val2)] select_statement1
INSERT INTO TABLE table2 [PARTITION(partcol1=val1,partcol2=val2)[IF NOT EXISTS]] select_statements2
INSERT OVERWRITE DIRECTORY ‘path’ select_statement3;
-- 提取操作
FROM movies
INSERT OVERWRITE TABLE horror_movies SELECT * WHERE horror = 1 AND release_date=’8/23/2013’
INSERT INTO action_movies SELECT * WHERE action = 1 AND release_date = ‘8/23/2013’; FROM (SELECT * FROM movies WHERE release_date =’8/23/2013’) src
INSERT OVERWRITE TABLE horror_movies SELECT * WHERE horror =1
INSERT INTO action_movies SELECT * WHERE action = 1;
Dynamic Partition Inserts
CREATE TABLE views_stg (eventTime STRING, userid STRING)
PARTITIONED BY(dt STRING,applicationtype STRING,page STRING); FROM page_views src
INSERT OVERWRITE TABLE views_stg PARTITION (dt=’2013-09-13’,applicationtype=’Web’,page=’Home’)
SELECT src.eventTime,src.userid WHERE dt=’2013-09-13’ AND applicationtype=’Web’,page=’Home’
INSERT OVERWRITE TABLE views_stg PARTITION (dt=’2013-09-14,applicationtype=’Web’,page=’Cart’)
SELECT src.eventTime,src.userid WHERE dt=’2013-09-14’ AND applicationtype=’Web’,page=’Cart’
INSERT OVERWRITE TABLE views_stg PARTITION (dt=’2013-09-15’,applicationtype=’Web’,page=’Checkout’)
SELECT src.eventTime,src.userid WHERE dt=’2013-09-15’ AND applicationtype=’Web’,page=’Checkout’ FROM page_views src
INSERT OVERWRITE TABLE views_stg PARTITION (applicationtype=’Web’,dt,page)
SELECT src.eventTime,src.userid,src.dt,src.page WHERE applicationtype=’Web’
实例
!hadoop fs -mkdir /bihell/logs/multi_insert; !hadoop fs -put /media/sf_VM_Share/LogFiles/log_2012613_161117.log /media/sf_VM_Share/LogFiles/log_2013803_15590.log /bihell/logs/multi_insert -- 创建EXTERNAL TABLE
CREATE EXTERNAL TABLE staging (logtime STRING, userid INT, ip STRING, page STRING, ref STRING, os STRING, os_ver STRING, agent STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/bihell/logs/multi_insert'; --批量插入 PARTITION
INSERT INTO TABLE page_views PARTITION (y, m, d)
SELECT logtime, userid, ip, page, ref, os, os_ver, agent, substr(logtime, 7, 4), substr(logtime, 1, 2), substr(logtime, 4, 2)
FROM staging; SET hive.exec.dynamic.partition.mode=nonstrict; INSERT INTO TABLE page_views PARTITION (y, m, d)
SELECT logtime, userid, ip, page, ref, os, os_ver, agent, substr(logtime, 7, 4), substr(logtime, 1, 2), substr(logtime, 4, 2)
FROM staging; SELECT * FROM page_views WHERE y='2012' LIMIT 100; select regexp_replace(logtime, '/', '-') from staging;
select substr(logtime, 7, 4), substr(logtime, 1, 2), substr(logtime, 4, 2) from staging;
Hadoop 架构初探的更多相关文章
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Hadoop架构的初略总结(2)
Hadoop架构的初略总结(2) 回顾一下前文,我们总结了以下几个方面.我们为什么需要Hadoop:Hadoop2.0生态系统的构成:Hadoop1.0中HDFS和MapReduce的结构模型. 我们 ...
- Hadoop架构的初略总结(1)
Hadoop架构的初略总结(1) Hadoop是一个开源的分布式系统基础架构,此架构可以帮助用户可以在不了解分布式底层细节的情况下开发分布式程序. 首先我们要理清楚几个问题. 1.我们为什么需要Had ...
- OceanBase 架构初探
OceanBase 架构初探 原创衣舞晨风 发布于2018-11-13 08:44:14 阅读数 1417 收藏 展开 1.设计思路 OceanBase的目标是支持数百TB的数据量以及数十万TPS. ...
- 云原生时代, Kubernetes 多集群架构初探
为什么我们需要多集群? 近年来,多集群架构已经成为“老生常谈”.我们喜欢高可用,喜欢异地多可用区,而多集群架构天生就具备了这样的能力.另一方面我们也希望通过多集群混合云来降低成本,利用到不同集群各自的 ...
- Hadoop 架构与原理
1.1. Hadoop架构 Hadoop1.0版本两个核心:HDFS+MapReduce Hadoop2.0版本,引入了Yarn.核心:HDFS+Yarn+Mapreduce Yarn是资源调度框 ...
- Hadoop架构及集群
Hadoop是一个由Apache基金会所开发的分布式基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了 ...
- Hadoop架构: 流水线(PipeLine)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 流水线(PipeLine),简单地理解就是客户端向DataNode传输数据(Packet)和接收Dat ...
- Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 首先,我们要提出HDFS存储特点: 1.高容错 2.一个文件被切成块(新版本默认128MB一个块)在不 ...
随机推荐
- click through rate prediction
包括内容如下图: 使用直接估计法,置信区间置信率的估计: 1.使用二项分布直接估计 $p(0.04<\hat{p}<0.06) = \sum_{0.04n\leq k \leq 0.06n ...
- 【Spring MVC系列】--(4)返回JSON
[Spring MVC系列]--(4)返回JSON 摘要:本文主要介绍如何在控制器中将数据生成JSON格式并返回 1.导入包 (1)spring mvc 3.0不需要任何其他配置,添加一个jackso ...
- php技能考试每日一练
PHP技術者認定 1, [日本語文字のメール送信] (2016年10月31日)以下のコードは桃家タローさん宛てにメールを送るためのものである.コード内の[(1)]に入る正しいものを1つ次の記述の中から ...
- aui
#encoding:utf-8import wximport wx.auiclass MyFrame(wx.Frame): def __init__(self, *args, **kwargs): w ...
- Sublime-text 自己定义快捷键攻略
好吧.我承认今天非常悲剧,本来上午就写好了这篇博文,公布之后,在自己的博文里怎么也找不到. 所以如今又又一次写了一份.希望大家能顶一下吧...Nothing is better than your s ...
- PHP自学4——通过mail函数将feedback界面用户填写表单信息发送至指定邮箱
这一讲的内容依旧简单(谁叫PO主水平菜,依旧是个弱鸡ORZ),通过PHP的内置mail函数将一个反馈界面的信息发送到指定邮箱.在Windows平台不能直接需要使用该函数,需要下载一个sendmail并 ...
- MSSQL查询连接数
SELECT * FROM [Master].[dbo].[SYSPROCESSES] WHERE [DBID] IN ( SELECT [DBID] FROM [Master].[dbo].[SYS ...
- Fedora 20忘记root密码
1.忘记root密码的情况下.用sudo账户$sudo su就行了. 2.直接sudo passwd root就重置了roor密码了.
- C# DataTable 详解
添加引用 using System.Data; 创建表 //创建一个空表 DataTable dt = new DataTable(); //创建一个名为"Table_New"的空 ...
- 后缀数组的一些性质----height数组
height数组:定义 height[i] = suffix[i-1] 和 suffix[i] 的最长公共前缀,也就是排名相邻的两个后缀的最长公共前缀.那么对于 j 和 k 不妨设 Rank[j] & ...