spark提交任务的流程
1.spark提交流程
sparkContext其实是与一个集群建立一个链接,当你停掉它之后
就会和集群断开链接,则属于这个资源的Excutor就会释放掉了,Driver
向Master申请资源,Master会向work分配资源,则会在wordCount里面会
构建Rdd,则它会会构建DAG,DAG又叫有向无环图,则有向无环图一旦触发Action
的时候,这个时候就会提交任务,此时,这些任务就不会经过Master,如果经过Master
则Master的压力会很大,其实Excutor一旦启动了,它就会向Driver建立连接,Excutor
它可能存在多个机器上面,则Driver不知道Excutor在哪里,但是Excutor知道Driver
在哪里(通过Mastre来知道的),则此时Excutor会和Driver进行rpc通信,则此时Driver则会
提交计算任务(以stage进行分开处理,其中stage里面是一个个并行的task),则
提交的任务在Excutor里面执行,则在Excutor里面有这些任务的执行进度,则
Excutor会向这个Master里面汇报进度,Driver就会知道它执行到了哪里,如果
执行失败,则Driver可能会执行重试,可能会例如,如果有10个项目,其中9个项目
都执行完了,但是有一个项目会很慢很慢,则此时Driver会在启动一个项目,
看这两个项目,谁快就用谁,对于catch,则Excutor只会catch属于它的的分区
2.rdd缓存
spark计算特别快的原因,就是在不同的操作中可以在内存中持久化或缓存
多个数据集
3.容量的大小
关于容量大小,一般来说我们可以这样的假设,2个字段,100万条数据,50M,如果要说
可以往后面一次计算
4.关于内存分配
在spark的计算过程中,如果我们的一台worker的内存是2g,但是我们可以给这个work
启动spark,我可以只给他分1个g的内存,就是说这个worker里面,不管在执行任何操作,
都只用这1个g的内存
5.checkpoint(检查点)
假如在进行rdd的计算的过程中,如果前面计算的结果之后,把这个结果保存在磁盘当中,
但是磁盘烧了,则此时这个里面的数据就会消失,则此时我们就会从头开始记性计算,
但是这样又有一些浪费,我们可以设置一个检查点(checkpoint),把某些计算出来的结果
存在一个地方,当磁盘损坏,我们就可以回退到这些检查点当中,很想快照的意味
(这个就一般作用于比较复杂的运用,当我们保存这个checkpoint的时候,他会主动的去寻找
这个checkpoint里面保存的值)我们可以防止检查点的公共存放目录
sc.setCheckpointDir("hdfs://192.168.109.136:9000/ck2016mypoint"),设置检查点存放的地方
则我们此时hdfs dfs -ls /,我们就可以发现这个检查点存放的目录
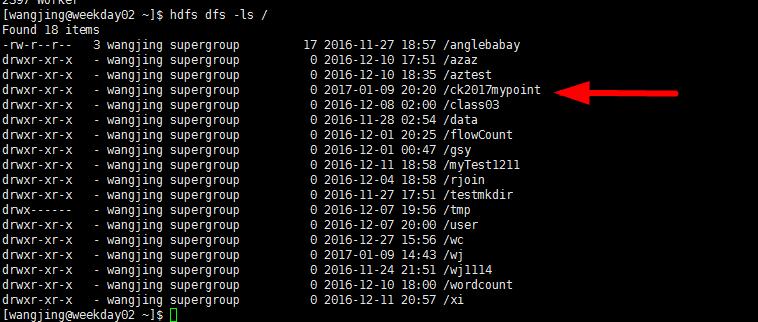
val rdd = sc.textFile("hdfs://192.168.109.136:9000/wj/input19")
rdd.checkpoint
rdd.count(运行action)
则此时回启动两个方法,第一个方法进行计算,另一个方法则把结果写到checkpoint
写到指定的目录(这个存放checkpoint的地方药可用性高,所以我们采用hdfs),
则此时把rdd的内容写到checkpoint里面
6.关于collect,cache,checkpoint的区别
collect是一个Action类型的RDD,而cache则是,当我们xxx.cache,则这个xxx的rdd在进行
Action的方法(collect),则会把这个RDD里面的内容缓存进内存,则当我们再一次进行计算的
时候,则会从内存中进行读取,而checkpoint这个值,这个是把这个rdd的值缓存进入一个公共
的目录(这个目录要有高的可用性,即使内存中丢失,这个也不会丢失)
spark提交任务的流程的更多相关文章
- spark提交任务报错: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes
spark提交任务报错: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes ...
- Spark SQL底层执行流程详解
本文目录 一.Apache Spark 二.Spark SQL发展历程 三.Spark SQL底层执行原理 四.Catalyst 的两大优化 一.Apache Spark Apache Spark是用 ...
- Spark源码分析之一:Job提交运行总流程概述
Spark是一个基于内存的分布式计算框架,运行在其上的应用程序,按照Action被划分为一个个Job,而Job提交运行的总流程,大致分为两个阶段: 1.Stage划分与提交 (1)Job按照RDD之间 ...
- spark yarn cluster模式下任务提交和计算流程分析
spark可以运行在standalone,yarn,mesos等多种模式下,当前我们用的最普遍的是yarn模式,在yarn模式下又分为client和cluster.本文接下来将分析yarn clust ...
- Spark源代码分析之中的一个:Job提交执行总流程概述
Spark是一个基于内存的分布式计算框架.执行在其上的应用程序,依照Action被划分为一个个Job.而Job提交执行的总流程.大致分为两个阶段: 1.Stage划分与提交 (1)Job依照RDD之间 ...
- Spark的任务提交和执行流程概述
1.概述 为了更好地理解调度,我们先看一下集群模式的Spark程序运行架构图,如上所示: 2.Spark中的基本概念 1.Application:表示你的程序 2.Driver:表示main函数,创建 ...
- spark 启动job的流程分析
从WordCount開始分析 编写一个样例程序 编写一个从HDFS中读取并计算wordcount的样例程序: packageorg.apache.spark.examples importorg.ap ...
- Spark streaming的执行流程
http://www.cnblogs.com/shenh062326/p/3946341.html 其实流程是从这里转载下来的,我只是在流程叙述中做了一下的标注. 当然为了自己能记住的更清楚,我没有 ...
- Spark提交任务(Standalone和Yarn)
Spark Standalone模式提交任务 Cluster模式: ./spark-submit \--master spark://node01:7077 \--deploy-mode clus ...
随机推荐
- 钢管下料问题2(剩余材料最少)lingo求解
大家好,我是小鸭酱,博客地址为:http://www.cnblogs.com/xiaoyajiang !钢管下料问题2(剩余材料最少) 题目: 钢管原料 每根19m 客户需求 4m 50根 ...
- Codeforces 461B Appleman and Tree
http://codeforces.com/problemset/problem/461/B 思路:dp,dp[i][0]代表这个联通块没有黑点的方案数,dp[i][1]代表有一个黑点的方案数 转移: ...
- LeetCode_Generate Parentheses
Given n pairs of parentheses, write a function to generate all combinations of well-formed parenthes ...
- 用keil直接生成BIN文件
1.下载hex2bin到keil的任意目录,下载地址:http://www.keil.com/download/docs/7.asp 或者 http://www.hex2bin.com/files/h ...
- cocos2d-x Loading界面实现资源加载
有时候场景中的资源加载过多的话就会引起游戏进入的时候很卡,因为那是边加载边显示.在tests例子里面有一个很好的例子叫做TextureCacheTest,里面讲解了如何写loading. #inclu ...
- zabbix 添加自定义key
vim /etc/zabbix/zabbix_agentd.conf UserParameter=zjzc.login,/bin/sh /usr/sbin/get_login.sh UserParam ...
- java 自定义鼠标图标
由于截图截不了,所以看不了图.源码如下: import java.awt.Cursor; import java.awt.Image; import java.awt.Point; import ja ...
- Android开发有用的站点
在github上面找到一个个人认为比較好的站点,好在能够方便下载开发工具.我的AndroidStudio就是在上面下载的.安装了一直在使用.该 网址主要收集整理Android开发所需的Android ...
- [Redux] Redux: Extracting Container Components -- AddTodo
Code to be refactored: const AddTodo = ({ onAddClick }) => { let input; return ( <div> < ...
- windows系统还原
windows系统还原 windows 系统还原有两种方法: 方法一.开始-控制面板-系统和安全-备份和还原 (或者开始—所有程序—附件—系统工具—系统还原) 详细请看下面的截图说明 方法二.开机的时 ...