堆分配与栈分配---SAP C++电面(5)/FEI
一直以来总是对这个问题的认识比较朦胧,我相信很多朋友也是这样的,总是听到内存一会在栈上分配,一会又在堆上分配,那么它们之间到底是怎么的区别呢?为了说明这个问题,我们先来看一下内存内部的组织情况.

从上图可知,程序占用的内存被分了以下几部分.
1、栈区(stack)
由编译器自动分配释放 ,存放函数的参数值,局部变量的值等,内存的分配是连续的,类似于平时我们所说的栈,如果还不清楚,那么就把它想成数组,它的内存分配是连续分配的,即,所分配的内存是在一块连续的内存区域内.当我们声明变量时,那么编译器会自动接着当前栈区的结尾来分配内存.
2、堆区(heap)
一般由程序员分配释放, 若程序员不释放,程序结束时可能由操作系统回收.类似于链表,在内存中的分布不是连续的,它们是不同区域的内存块通过指针链接起来的.一旦某一节点从链中断开,我们要人为的把所断开的节点从内存中释放.
3、全局区(静态区)(static)
全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束后由系统释放
4、文字常量区
常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区
存放函数体的二进制代码。
先看一个例子.
char c; //栈上分配
char *p = new char[3]; //堆上分配,将地址赋给了p;
在 编译器遇到第一条指令时,计算其大小,然后去查找当前栈的空间是大于所需分配的空间大小,如果这时栈内空间大于所申请的空间,那么就为其分配内存空间,注 意:在这里,内在空间的分配是连续的,是接着上次分配结束后进行分配的.如果栈内空间小于所申请的空间大小,那么这时系统将揭示栈溢出,并给出相应的异常 信息.
编译器遇到第二条指令时,由于p是在栈上分配的,所以在为p分配内在空间时和上面的方法一样,但当遇到new关 键字,那么编译器都知道,这是用户申请的动态内存空间,所以就会转到堆上去为其寻找空间分配.大家注意:堆上的内存空间不是连续的,它是由相应的链表将其 空间区时的内在区块连接的,所以在接到分配内存空间的指定后,它不会马上为其分配相应的空间,而是先要计算所需空间,然后再到遍列整个堆(即遍列整个链的 节点),将第一次遇到的内存块分配给它.最后再把在堆上分配的字符数组的首地址赋给p.,这个时候,大家已经清楚了,p中现在存放的是在堆中申请的字符数组的首地址,也就是在堆中申请的数组的地址现在被赋给了在栈上申请的指针变量p.为了更加形象的说明问题,请看下图:
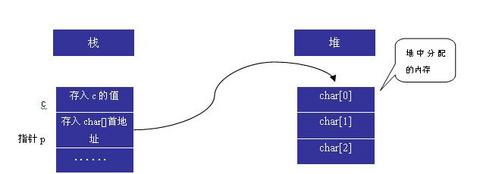
从上图可以看出,我们在堆上动态分配的数组的首地址存入了指针p所指向的内容.
请注意:在栈上所申请的内存空间,当我们出了变量所在的作用域后,系统会自动我们回收这些空间,而在堆上申请的空间,当出了相应的作用域以后,我们需要显式 的调用delete来释放所申请的内存空间,如果我们不及时得对这些空间进行释放,那么内存中的内存碎片就越来越多,从而我们的实际内存空间也就会变的越 来越少,即,孤立的内存块越来越多.在这里,我们知道,堆中的内存区域不是连续的,还是将有效的内存区域经过链表指针连接起来的,如果我们申请到了某一块 内存,那么这一块内存区将会从连续的(通过链表连接起来的)内存块上断开,如果我们在使用完后,不及时的对它进行释放,那么它就会孤立的开来,由于没有任 何指针指向它,所以这个区域将成为内存碎片,所以在使用完动态分配的内存(通过NEW申请)后,一定要显式的对它进行DELETE删除.对于这一点,一定 要切记...
上面给大家陈述了它们之间的概念,对于它们俩的使用比较方面,这里我就不能大家断续陈述了,对于这个问题,网上一网友的文章中阐述的比较详细,而且附带了专业的色彩,下面的文章是部分片断.
申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度
堆分配与栈分配---SAP C++电面(5)/FEI的更多相关文章
- 内存的堆分配和栈分配 & 字符数组,字符指针,Sizeof总结
堆和栈的区别 一个由C/C++编译的程序占用的内存分为以下几个部分1.栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.其操作方式类似于数据结构中的栈.2.堆区(heap ...
- 如何限制一个类只在堆上分配和栈上分配(StackOnly HeapOnly)
[本文链接] http://www.cnblogs.com/hellogiser/p/stackonly-heaponly.html [题目] 如何限制一个类只在堆上分配和栈上分配? [代码] C+ ...
- U3D的结构体堆分配栈分配
ST ot;//分配在栈上 ST[] arrt = new ST[2];//分配在堆上,因为数组是引用
- Java中堆内存与栈内存分配浅析
Java把内存划分成两种:一种是栈内存,另一种是堆内存.在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配,当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间, ...
- JVM存储位置分配——java中局部变量、实例变量和静态变量在方法区、栈内存、堆内存中的分配
Java中的变量根据不同的标准可以分为两类,以其引用的数据类型的不同来划分可分为“原始数据类型变量和引用数据类型变量”,以其作用范围的不同来区分可分为“局部变量,实例变量和静态变量”. 根据“Java ...
- new 的对象如何不分配在堆而分配在栈上(方法逃逸等)
当能够明确对象不会发生逃逸时,就可以对这个对象做一个优化,不将其分配到堆上,而是直接分配到栈上,这样在方法结束时,这个对象就会随着方法的出栈而销毁,这样就可以减少垃圾回收的压力. 如方法逃逸. 逃逸分 ...
- Java中局部变量、实例变量和静态变量在方法区、栈内存、堆内存中的分配
转自:https://blog.csdn.net/leunging/article/details/80599282 感谢CSDN博主「leunging」的总结分享 ———————————————— ...
- (转)java内存分配分析/栈内存、堆内存
转自(http://blog.csdn.net/qh_java/article/details/9084091) java内存分配分析/栈内存.堆内存 java内存分配分析 本文将由浅入深详细介绍Ja ...
- Java基本类型的内存分配在栈还是堆
我们都知道在Java里面new出来的对象都是在堆上分配空间存储的,但是针对基本类型却有所区别,基本类型可以分配在栈上,也可以分配在堆上,这是为什么? 在这之前,我们先看下Java的基本类型8种分别是: ...
随机推荐
- iOS 开发常用设置
1. iOS设置app应用程序文件共享 设置流程 xcode 打开项目----在 info.plist 文件,添加 UIFileSharingEnabled 并设置属性为 YES, 在app内部,将您 ...
- visibleViewController和topViewController 获取当前显示的页面
原文:http://blog.sina.com.cn/s/blog_881ed8500102vo38.html UINavigationController 中有visibleViewControll ...
- The encryption certificate of the relying party trust identified by thumbprint is not valid
CRM2013部署完ADFS后通过url在浏览器中訪问測试是否成功,成功进入登陆界面但在登陆界面输入username和password后始终报身份验证失败,系统中的报错信息例如以下:Microsoft ...
- MessageQueue
MessageQueue myQueue = new MessageQueue(".\\private$\\myQueue"); try { Message myMessage = ...
- SharePoint webpart中悬浮窗口的webconfig路径
SharePoint webpart中悬浮窗口的webconfig路径在.../_layouts/15/下.
- Android 数据适配器
把复杂的数据(数组.链表.数据库.集合等)填充到指定的视图界面上. arrayAdapter(数组适配器): 用于绑定一些格式单一的数据,数据源:数据或者集合. private Li ...
- Android 数据库ORM框架GreenDao学习心得及使用总结<一>
转: http://www.it165.net/pro/html/201401/9026.html 最近在对开发项目的性能进行优化.由于项目里涉及了大量的缓存处理和数据库运用,需要对数据库进行频繁的读 ...
- ArrayList与LinkedList时间复杂度之对比
package ArrayList; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections ...
- lint使用简介
LINT工具是一种软件质量保证工具,许多国外的大型专业软件公司,如微软公司,都把它作为程序检查工具,在程序合入正试版本或交付测试之前一定要保证通过了LINT检查,他们要求软件工程师在使用LINT时要打 ...
- MiniSD卡是什么
Mini SD卡比目前主流的普通SD卡(如DC或DV上使用的SD卡),在外形上更加小巧,重量仅有3克左右,体积只有21.5x20x1.4mm,比普通SD卡足足节省了60%的空间.别小看这么小的外形,它 ...