hadoop-hbase单机和集群搭建
1.下载 http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz 最新版
解压: tar -zxvf hadoop-2.7.1.tar.gz
2.配置环境变量
user@EBJ1023.local:/Users/user> vim ~/.bash_profile
export HADOOP_HOME=/usr/local/flume_kafka_stom/hadoop_2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.单机版测试
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,即将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
user@EBJ1023.local:/Users/user> cd /usr/local/flume_kafka_stom/hadoop_2.7.1
mkdir input
cp ./etc/hadoop/*.xml input # 将配置文件作为输入文件.user@EBJ1023.local:/usr/local/flume_kafka_stom/hadoop_2.7.1> ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'cat ./output/*
查看运行结果:


表示单机版的安装成功。
4.伪分布式安装与配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。
Hadoop 的配置文件位于 /usr/local/flume_kafka_stom/hadoop_2.7.1/etc/hadoop 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (vim /usr/local/flume_kafka_stom/hadoop_2.7.1/etc/hadoop/core-site.xml),将当中的
<configuration> </configuration>
修改如下:
<configuration>
<property>
<name>hadoop_2.7.1.tmp.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/flume_kafka_stom/hadoop_2.7.1/tmp/dfs/data</value>
</property> </configuration>
虽 然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 namenode 的格式化:
bin/hdfs namenode -format
结果如下:
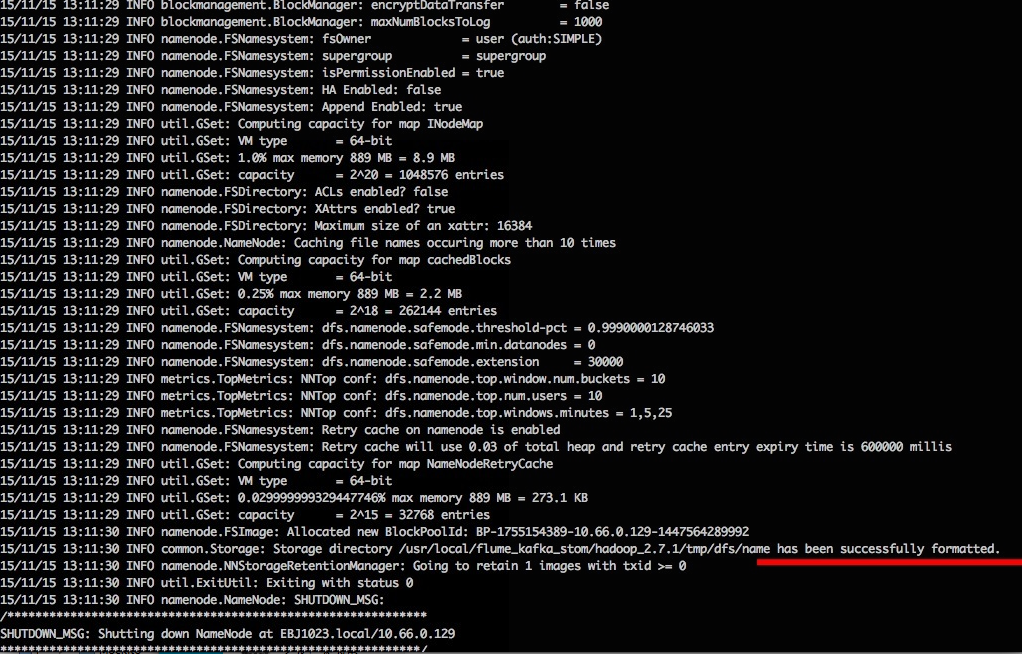
成功的话,会看到 successfully formatted 的提示,且倒数第5行的提示如下,Exitting with status 0 表示成功,若为 Exitting with status 1 则是出错。若出错(不该如此,请仔细检查之前步骤),可试着加上 sudo, 既 sudo bin/hdfs namenode -format 再试试看。
接着开启 NaneNode 和 DataNode 守护进程。
sbin/start-dfs.sh
启动碰到以下问题:连接localhost port 22 Connection 由于本机是mac
解决办法:http://blog.csdn.net/jymn_chen/article/details/39931469

重启正常:

若你使用的是 Hadoop 2.7.1 64位,则此时可能会出现一连串的warn提示,如 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 这个提示,这些warn提示可以忽略,不会影响正常使用。
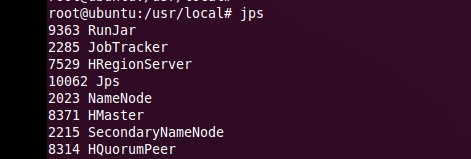
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: NameNode、DataNode和SecondaryNameNode。(如果SecondaryNameNode没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试;如果 NameNode 或 DataNode 没有启动,请仔细检查之前步骤)。
查看进程
jps

有时 Hadoop 无法正确启动,如 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,注意几点:
- 启动时会提示形如 “DBLab-XMU: starting namenode, logging to /usr/local/flume_kafka_stom/hadoop_2.7.1/logs”,其中 DBLab-XMU 对应你的机器名,但其实启动日志信息是记录在/usr/local/flume_kafka_stom/hadoop_2.7.1/logs 中,所以应该查看这个后缀为 .log 的文件;
- 每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,看下记录的时间就知道了。
- 一般出错的提示在最后面,也就是写着 Fatal、Error 或者 Java Exception 的地方。
- 可以在网上搜索一下出错信息,看能否找到一些相关的解决方法。
成功启动后,可以访问 Web 界面 http://localhost:50070 来查看 Hadoop 的信息。
说明安装成功。
hbase 单机+伪分布环境搭建学习
1、单机模式:
(1)编辑hbase-env.sh
user@EBJ1023.local:/usr/local/flume_kafka_stom/hbase_1.1.2> vim conf/hbase-env.sh
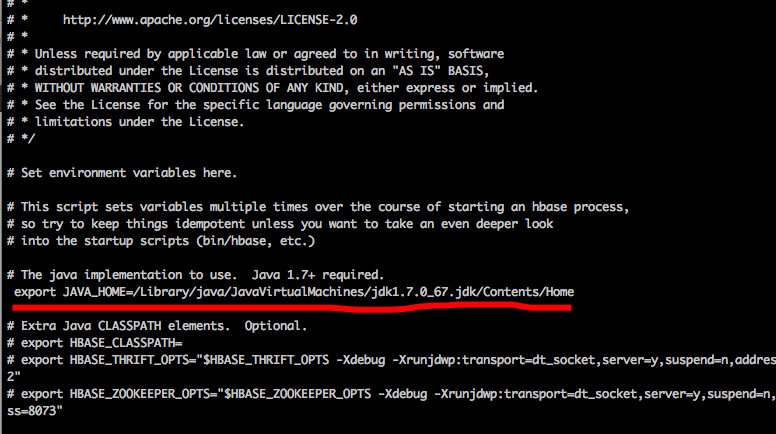
(2)编辑hbase-site.xml
user@EBJ1023.local:/usr/local/flume_kafka_stom/hbase_1.1.2> vim conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/flume_kafka_stom/hbase_1.1.2/tmp/hbase/data</value>
</property>
</configuration>
(3)、启动hbase
$ bin/start-hbase.sh

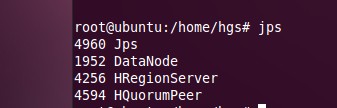
jps 查看后 出现Hmaster就是启动成功 然后就可以进入shell进行对hbase的操作。
$ bin/hbase shell
可以操作hbase数据库了。
1、伪分布式模式:
user@EBJ1023.local:/usr/local/flume_kafka_stom/hbase_1.1.2> vim conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
因为我们采用的是伪分布模式,这里需要将HBase的数据存储到之前的Hadoop的HDFS上,hbase.rootdir的值便是HDFS上 HBase数据存储的位置,值中的主机名和端口号要和之前Hadoop的 core-site.xml中的fs.default.name的值相同,比如上一篇文章中的 hdfs://localhost:9000 。
bin/start-hbase.sh
jps

bin/start-hbase.sh

可以操作数据库了。
hadoop+zookeeper+hbase集群配置
1.快速单机安装:在单机安装Hbase的方法。会引导你通过shell创建一个表,插入一行,然后删除它,最后停止Hbase。只要10分钟就可以完成以下的操作。 1.1下载解压最新版本选择一个 Apache 下载镜像:http://www.apache.org/dyn/closer.cgi/hbase/,下载一个releases版本的,目前是0.94.8.然后下载后缀为 .tar.gz 的文件; 例如 hbase-0.94.8.tar.gz.$ tar xfz hbase-0.94.8.tar.gz 现在你已经可以启动Hbase了。但是你可能需要先编辑 conf/hbase-site.xml 去配置hbase.rootdir,来选择Hbase将数据写到哪个目录 .
将 DIRECTORY 替换成你期望写文件的目录. 默认 hbase.rootdir 是指向 /tmp/hbase-${user.name} ,也就说你会在重启后丢失数据(重启的时候操作系统会清理/tmp目录) 1.2. 启动 HBase现在启动Hbase: $ ./bin/start-hbase.sh starting Master, logging to logs/hbase-user-master-example.org.out 现在你运行的是单机模式的Hbaes。所以的服务都运行在一个JVM上,包括Hbase和Zookeeper。Hbase的日志放在 1.3. Hbase Shell 练习用shell连接你的Hbase $ ./bin/hbase shell HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version: 0.90.0, r1001068, Fri Sep 24 13:55:42 PDT 2010 hbase(main):001:0> 输入 help 然后 <RETURN> 可以看到一列shell命令。这里的帮助很详细,要注意的是表名,行和列需要加引号。 创建一个名为 hbase(main):003:0> create 'test', 'cf' 0 row(s) in 1.2200 seconds hbase(main):003:0> list 'table' test 1 row(s) in 0.0550 seconds hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1' 0 row(s) in 0.0560 seconds hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2' 0 row(s) in 0.0370 seconds hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3' 0 row(s) in 0.0450 seconds 以上我们分别插入了3行。第一个行key为 检查插入情况. Scan这个表,操作如下 hbase(main):007:0> scan 'test' ROW COLUMN+CELL row1 column=cf:a, timestamp=1288380727188, value=value1 row2 column=cf:b, timestamp=1288380738440, value=value2 row3 column=cf:c, timestamp=1288380747365, value=value3 3 row(s) in 0.0590 seconds Get一行,操作如下 hbase(main):008:0> get 'test', 'row1' COLUMN CELL cf:a timestamp=1288380727188, value=value1 1 row(s) in 0.0400 seconds disable 再 drop 这张表,可以清除你刚刚的操作 hbase(main):012:0> disable 'test' 0 row(s) in 1.0930 seconds hbase(main):013:0> drop 'test' 0 row(s) in 0.0770 seconds 关闭shell hbase(main):014:0> exit 1.4. 停止 HBase运行停止脚本来停止HBase. $ ./bin/stop-hbase.sh stopping hbase............... 2 Hbase集群安装前注意1) Java:(hadoop已经安装了) 2) Hadoop 1.2.0 已经正确安装,并且可以启动 HDFS 系统, 可参考的Hadoop安装文档:hadoop+zookeeper+hbase集群配置(一)http://blog.csdn.net/jpiverson/article/details/9130447 3) NTP:集群的时钟要保证基本的一致。稍有不一致是可以容忍的,但是很大的不一致会 造成奇怪的行为。 运行 NTP 或者其他什么东西来同步你的时间. 如果你查询的时候或者是遇到奇怪的故障,可以检查一下系统时间是否正确! 设置集群各个节点时钟:date -s “2012-02-13 14:00:00”
Base是数据库,会在同一时间使用很多的文件句柄。大多数linux系统使用的默认值1024是不能满足的,会导致FAQ: Why do I see "java.io.IOException...(Too manyopen files)" in my logs?异常。还可能会发生这样的异常 2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: ExceptionincreateBlockOutputStream java.io.EOFException 2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient:Abandoning block blk_-6935524980745310745_1391901 所以你需要修改你的最大文件句柄限制。可以设置到10k. 你还需要修改 hbase 用户的 nproc,如果过低会造成 OutOfMemoryError异常。 [2] [3]. 需要澄清的,这两个设置是针对操作系统的,不是Hbase本身的。有一个常见的错误是Hbase运行的用户,和设置最大值的用户不是一个用户。在Hbase启动的时候,第一行日志会现在ulimit信息,所以你最好检查一下。 设置
在文件 /etc/security/limits.conf 添加一行,如: hadoop - nofile 32768 可以把 hadoop 替换成你运行Hbase和Hadoop的用户。如果你用两个用户,你就需要配两个。还有配nproc hard 和 softlimits. 如: hadoop soft/hard nproc 32000 在 /etc/pam.d/common-session 加上这一行: session required pam_limits.so 否则在 /etc/security/limits.conf上的配置不会生效. 还有注销再登录,这些配置才能生效! 7 )修改Hadoop HDFS Datanode同时处理文件的上限: 一个 Hadoop HDFS Datanode 有一个同时处理文件的上限. 这个参数叫 xcievers (Hadoop的作者把这个单词拼错了). 在你加载之前,先确认下你有没有配置这个文件conf/hdfs-site.xml里面的xceivers参数,至少要有4096: <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property> 对于HDFS修改配置要记得重启. 如果没有这一项配置,你可能会遇到奇怪的失败。你会在Datanode的日志中看到xcievers exceeded,但是运行起来会报 missing blocks错误。例如: 02/12/1220:10:31 INFO hdfs.DFSClient: Could not obtain blockblk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node: java.io.IOException: No livenodes contain current block. Will get new block locations from namenode andretry... 8)继承hadoop安装的说明: 每个机子/etc/hosts 192.168.10.203 node1 (master) 192.168.10.204 node2 (slave) 192.168.10.205 node3 (slave) 9) 继续使用hadoop用户安装 Chown –R hadoop /usr/local/hbase 3 分布式模式配置3.1配置
|
hadoop-hbase单机和集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- hbase完整分布式集群搭建
简介: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop2.8 ha 集群搭建 hbase完整分布式集群搭建 hadoop完整集群遇到问题汇总 Hb ...
- HBase HA分布式集群搭建
HBase HA分布式集群搭建部署———集群架构 搭建之前建议先学习好HBase基本构架原理:https://www.cnblogs.com/lyywj170403/p/9203012.html 集群 ...
- HBase完全分布式集群搭建
HBase完全分布式集群搭建 hbase和hadoop一样也分为单机版,伪分布式版和完全分布式集群版,此文介绍如何搭建完全分布式集群环境搭建.hbase依赖于hadoop环境,搭建habase之前首先 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- Zookeeper,Hbase 伪分布,集群搭建
工作中一般使用的都是zookeeper和Hbase的分布式集群. more /etc/profile cd /usr/local zookeeper-3.4.5.tar.gz zookeeper在安装 ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
随机推荐
- 初识GO语言--并发
- sqli-labs Less 2-4 攻略
sqli-labs Less 2-4 的解题与Less1思路相同,只在闭合类型上存在少量区别,故直接提供解题过程,不再作详细解释. 对sql注入基本原理尚不了解的可以参考我的上一篇博客基于sqli-l ...
- 内网渗透之不出网上线CobaltStrike技巧
目录 前言 smb beacon上线 tcp listener转发上线 http代理上线 tcp beacon正向连接上线 题外话 - cs和msf的权限传递 cs派生给msf msf派生给cs 前言 ...
- golang之json.RawMessage
RawMessage 具体来讲是 json 库中定义的一个类型.它实现了 Marshaler 接口以及 Unmarshaler 接口,以此来支持序列化的能力.注意上面我们引用 官方 doc 的说明. ...
- golang模板库之fasttemplate
简介 fasttemplate是一个比较简单.易用的小型模板库.fasttemplate的作者valyala另外还开源了不少优秀的库,如大名鼎鼎的fasthttp,前面介绍的bytebufferpoo ...
- golang之测试testing
01 介绍 我们使用 Golang 语言开发的项目,怎么保证逻辑正确和性能要求呢?也就是说我们如何测试我们的 Golang 代码呢?在 Golang 语言中,可以使用标准库 testing 包编写单 ...
- uniapp 样式篇
1.全局变量 项目根目录的 uni.scss 文件是uni-app内置的常用样式变量,这个文件会自动引入,开发者可直接引用这个变了 文件默认已经定义了常用的变量,开发者也可以在此基础上继续添加 /* ...
- ant 组件全局设置中文 vue
//引入中文组件import zhCN from 'ant-design-vue/es/locale/zh_CN';//定义 const locale = zhCN //包裹根组件 <a- ...
- 基于 C# 编写的 Visual Studio 文件编码显示与修改扩展插件
前言 在软件开发过程中,尤其是在处理跨平台或来自不同来源的项目时,文件的编码格式往往会成为一个不可忽视的问题.不同的操作系统.编程语言和编辑器可能对文件编码有不同的支持和默认设置,这可能导致在打开一个 ...
- VLC web(http)控制 (2) 状态获取
VLC 状态通过http://127.0.0.1:8080/requests/status.xml获取.(IP地址自行更换) 内容如下: <root> <fullscreen> ...