开源共建 | Dinky 扩展批流统一数据集成框架 ChunJun 的实践分享
一、前言
ChunJun(原FlinkX)是一个基于 Flink 提供易用、稳定、高效的批流统一的数据集成工具,既可以采集静态的数据,比如 MySQL,HDFS 等,也可以采集实时变化的数据,比如 binlog,Kafka等。同时 ChunJun 也是一个支持原生 FlinkSql所有语法和特性的计算框架。
ChunJun 具有丰富的插件种类,多达40种,如常见的 mysql、binlog、logminer 等,大部分插件都支持 source/reader、sink/writer 及维表功能。目前很多用户在思考能否在 Dinky 上使用 ChunJun 的插件以提供更全面的能力。那本文将带来如何在 Dinky 上集成 ChunJun 丰富的插件,其实简单,那我们开始吧。
二、部署 Flink+ChunJun
编译
注意,如果需要集成 Dinky,需要将 ChunJun项目下的 chunjun-core 的pom 文件中的 logback-classic 和 logback-core 注释掉,否则容易在 Dinky 执行 sql 任务的时候报错。

然后执行:

部署
使用 ChunJun 需要先部署 Flink 集群,其部署本文不再做指导。
值得注意的是,如果你需要调用 Flinkx 的 connect jar 的话,则需要将 classloader.resolve-order 改成 parent-first。修改完成配置以后,把 Flinkx 的 jar 包复制过来,主要是 chunjun-clients-master.jar(Flinkx 现在改名 ChunJun )以及 chunjun 的其它 connector 放到 flink/lib 目录下,如图所示。

异常处理
如果启动集群时出现异常,即 Flink standalone 集群加载 flinkx-dist 里 jar 包之后,集群无法启动,日志报错:Exception in thread "main" java.lang.NoSuchFieldError: EMPTY_BYTE_ARRAY.
Exception in thread"main"java.lang.NoSuchFieldError:EMPTY_BYTE_ARRAY
at org.apache.logging.log4j.core.config.ConfigurationSource.(ConfigurationSource.java:56)
at org.apache.logging.log4j.core.config.NullConfiguration.< init>(NullConfiguration.java:32)
at org.apache.logging.log4j.core.LoggerContext.< clinit>(LoggerContext.java:85)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.log4j.LogManager.< clinit>(LogManager.java:72)
at org.slf4j.impl.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:73)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:285)
at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:305)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.< clinit>(ClusterEntrypoint.java:107)
原因:这个报错是因为 log4j 版本不统一导致的,因为 flinkx-dist 中部分插件引用的还是旧版本的 log4j 依赖,导致集群启动过程中,出现了类冲突问题;
方案:临时方案是将 flink lib 中 log4j 相关的jar包名字前加上字符 ‘a‘,使得flink standalone jvm 优先加载。
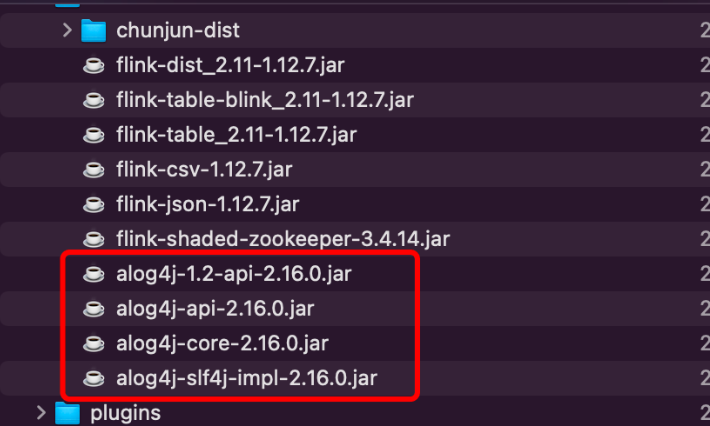
三、部署 Dinky
编译

编译完成后的压缩包在 Dinky 根目录下的 build 文件夹下。
部署
1、上传dlink压缩包到部署服务器
2、解压

3、数据库初始化
4、把 flink 的 jar 放到 dlink 目录下

切换 Dinky 的 Flink 版本
因为目前 flinkx 的稳定版本是 1.12.7,所以我们把 dlink 默认的 client 版本修改为 1.12

lib下的目录如图:
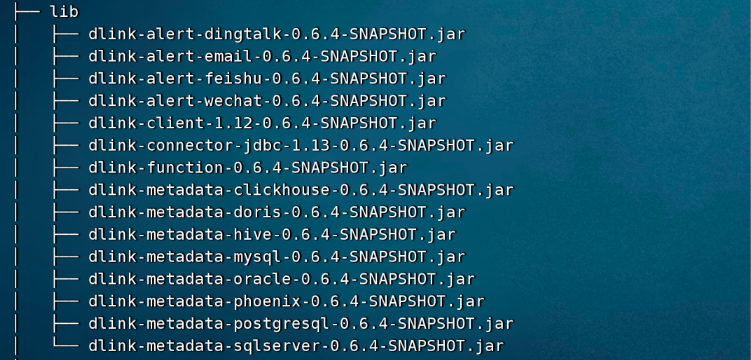
注意:因为我没有用上 dlink-connector-jdbc 的 jar 包,所以图中的 dlink-connector-jdbc-1.13-0.6.4-SNAPSHOT.jar 没有换成1.12版本的,可以去掉。
启动
启动命令

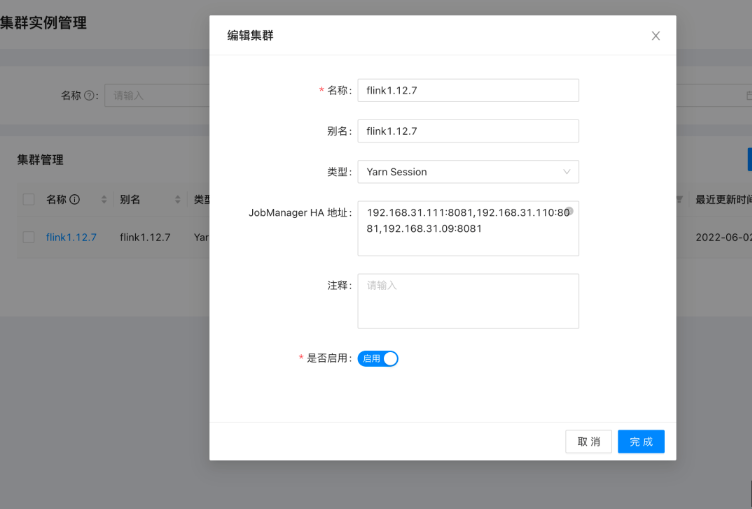
注册集群实例
在集群实例中注册已经启动的 Flink 集群。
四、示例分享
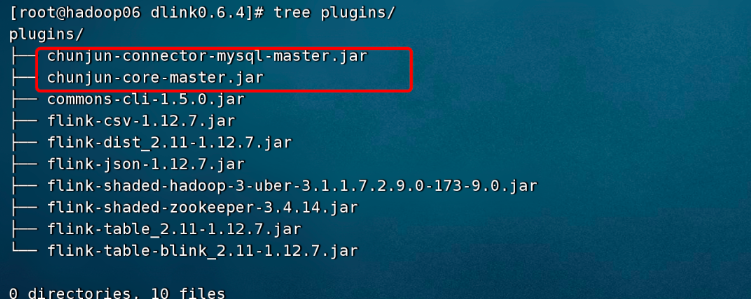
添加依赖
这里演示 mysql->mysql 的同步作业,所以需要 Flinkx 的 mysql-connector.jar 以及核心 jar。
编写作业
Mysql DDL:
CREATE TABLE datasource_classify (
id int unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
classify_code varchar(64) NOT NULL COMMENT '类型栏唯一编码',
sorted int NOT NULL DEFAULT '0' COMMENT '类型栏排序字段 默认从0开始',
classify_name varchar(64) NOT NULL COMMENT '类型名称 包含全部和常用栏',
is_deleted tinyint NOT NULL DEFAULT '0' COMMENT '是否删除,1删除,0未删除',
gmt_create datetime DEFAULT CURRENT_TIMESTAMP,
gmt_modified datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY classify_code (classify_code)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='数据源分类表';
Flink Sql:
CREATE TABLE source
(
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.101:3306/datasource?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,'scan.fetch-size' = '2'
,'scan.query-timeout' = '10'
);
CREATE TABLE sink
(
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.106:3306/test?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,'scan.fetch-size' = '2'
,'scan.query-timeout' = '10'
);
insert into sink
select *
from source u;
执行任务
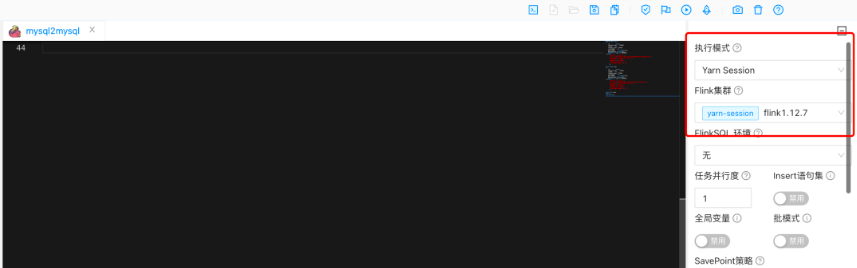
选中 Yarn Session 模式提交作业。

提交后可从执行历史查看作业提交状况。

进程中可以看的 Flink 集群上批作业执行完成。
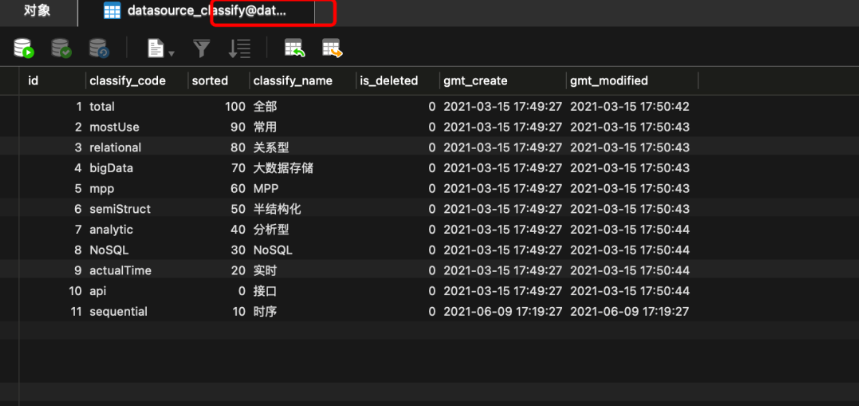
对比数据
源库:
目标库:
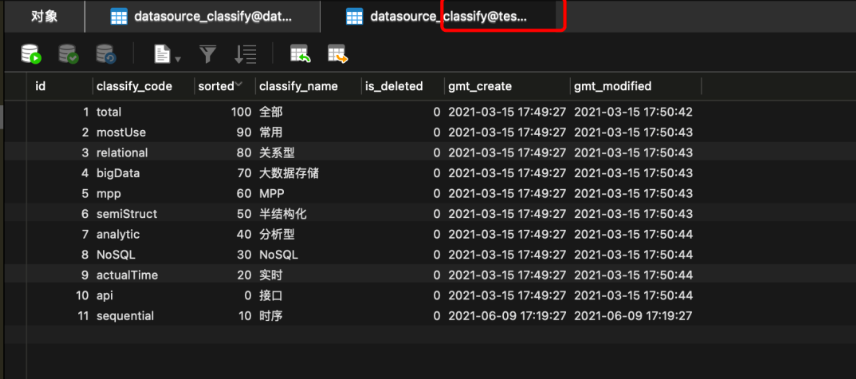
同步成功,很丝滑。
五、总结
在集成 ChunJun 的时候遇到的问题大部分都是缺包以及包冲突,所以只需要注意一下这个问题就能比较好的进行集成。
在集成服务的时候建议是,先把 Flink 和 ChunJun 进行集成,确保服务能够正常启用以后再进行 Dinky 的集成,这样有利于快速定位查找问题,如果遇到文章之外的问题,也可以查看 Dinky 官网FAQ | Dinky (dlink.top) chunjun的官网QuickStart | ChunJun 纯钧 (dtstack.github.io/chunjun/),看看是否有类似问题的解决办法作为参考。
六、用户体验
因为本人目前还是处于学习使用的过程中,所以很多功能没有好好使用,待自己研究更加透彻后希望写一篇文章,优化官网的用户手册。以下的优缺点以及建议都是目前我在使用学习的过程中遇到的问题。
优点
Dinky 最吸引我的地方应该就是 sql 编辑模版了,直接快捷键生成 sql 模版,在开发测试中屡试不爽。在集成了 ChunJun(Flinkx) 以后,能够做到多源数据的离线跑批任务及日常小批量实时任务的同步。支持各种类型的任务执行方式。
缺点
ui 上适配还有点小问题,例如:打开 F12 调整宽度后,再关闭,页面 ui 不会自适应,需要刷新。
期待改进点
1、更多的自定义异常、业务异常
2、增加新的向导模式,结合数据源,通过 webUI 可以一键引入字段或者勾选需要的字段,生成 Flink Sql 的一大部分配置
CREATE TABLE 表名
(
-- 页面勾选字段,字段从元数据直接拉取
id bigint,
classify_code STRING,
sorted int,
classify_name STRING,
is_deleted int,
gmt_create timestamp(9),
gmt_modified timestamp(9),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
-- 从选择的数据中获取
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://192.168.31.106:3306/test?useSSL=false',
'table-name' = 'datasource_classify',
'username' = 'root',
'password' = 'root'
,
-- 其它非主要配置有用户自己填写
);
3、sql 历史版本管理,目前我已经提交 Feature 并被合并到 0.6.5 版本中。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack/Taier
开源共建 | Dinky 扩展批流统一数据集成框架 ChunJun 的实践分享的更多相关文章
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- 阿里重磅开源全球首个批流一体机器学习平台Alink,Blink功能已全部贡献至Flink
11月28日,Flink Forward Asia 2019 在北京国家会议中心召开,阿里在会上发布Flink 1.10版本功能前瞻,同时宣布基于Flink的机器学习算法平台Alink正式开源,这也是 ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 数据集成工具:Teiid实践
数据集成是把不同来源.格式.特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享.数据集成的方式多种多样,这里介绍的 Teiid 是其中的一种:通过抽象和联邦技术,实现分布式数据源的 ...
- Tapdata x 轻流,为用户打造实时接入轻流的数据高速通道
在全行业加速布局数字化的当口,如何善用工具,也是为转型升级添薪助力的关键一步. 那么当轻量的异构数据实时同步工具,遇上轻量的数字化管理工具,将会收获什么样的新体验?此番 Tapdata 与轻流 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- DataPipeline CTO 陈肃:我们花了3年时间,重新定义数据集成
目前,中国企业在大数据流通.交换.利用等方面仍处于起步阶段,但是企业应用数据集成市场却是庞大的.根据 Forrester 数据看来,2017 年全球数据应用集成市场纯软件规模是 320 亿美元,如果包 ...
随机推荐
- maven知识理解和生命周期
学习的技能/知识 运动 提升 不足 强化了maven的知识理解和生命周期 3公里日常跑,其中1公里破之前的记录达到3分40 没有赖床,嗯:写完的博客自己阅读又温习了一遍 下午没课,但都用来休息了.. ...
- 元模型对AI的哲学意义:让机器真正"懂"世界
元模型对AI的哲学意义:让机器真正"懂"世界 (用日常语言和比喻解释) 1. 传统AI像"死记硬背的学生" 问题:现在的ChatGPT就像背了无数词典的人,能对 ...
- 开发app步骤总结
以下是用IDEA后端Java开发(如Spring Boot)与Android Studio前端开发app的逻辑实现步骤详解: 一.技术选择 通信协议:推荐使用RESTful API(HTTP/HTTP ...
- 小白必看的java完整下载攻略!(在Typora中有图片参考)
Java下载 在浏览器上搜索JDK(2024年最新版是22,本人下载的是21) 点击官网下载,会跳到Oracle官网,需要注册账号才可下载 根据自己的电脑型号选择下载(本人下载的是64的) 正常情况下 ...
- 【MathJax】语法总结
基础语法 1.显示公式 在行中显示的 (inline mode),就用 $...$ 单独一行显示 (display mode),则用 $$...$$ 2.希腊字母 要显示希腊字母,可以用 \alpha ...
- 【硬件】认识和选购多核CPU
2.1 认识和选购多核CPU CPU在电脑系统中就像人的大脑一样,是整个电脑系统的指挥中心,电脑的所有工作都由CPU进行控制和计算.它的主要功能是负责执行系统指令,包括数据存储.逻辑运算.传输控制.输 ...
- 【SpringCloud】SpringCloud Alibaba Sentinel实现熔断与限流
SpringCloud Alibaba Sentinel实现熔断与限流 限流与降级 限流 blockHandler 降级 fallback 降级需要运行时出现异常才会触发,而限流一旦触发,你连运行的机 ...
- Redis 持久化——混合持久化
1.Redis 持久化--混合持久化 RDB 和 AOF 持久化各有利弊,RDB 可能会导致一定时间内的数据丢失,而 AOF 由于文件较大则会影响 Redis 的启动速度,为了能同时使用 RDB 和 ...
- react项目vite报错:UnhandledPromiseRejectionWarning: SyntaxError: Unexpected token '??='
问题: vite报错:UnhandledPromiseRejectionWarning: SyntaxError: Unexpected token '??=' 今天clone一个vite的项目,安装 ...
- mac使用pptp的正确方式
环境:macos mojave 10.14.6 尝试的解决方案: mac自带vpn 结论:已经不支持pptp协议 使用shimo 结论:无用,连接的时候没反应 为了解决不能连接的问题,某老外写的ppt ...