用python做时间序列预测七:时间序列复杂度量化
本文介绍一种方法,帮助我们了解一个时间序列是否可以预测,或者说了解可预测能力有多强。
Sample Entropy (样本熵)
Sample Entropy是Approximate Entropy(近似熵)的改进,用于评价波形前后部分之间的混乱程度,
熵越大,乱七八糟的波动越多,越不适合预测;熵越小,乱七八糟的波动越小,预测能力越强。
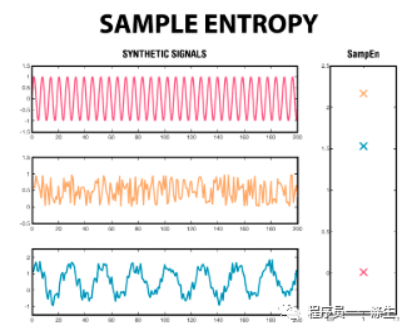
具体思想和实现如下:
- 思想
Sample Entropy最终得到一个 -np.log(A/B) ,该值越小预测难度越小,所以A/B越大,预测难度越小。
A:从0位置开始,取m+1个元素构成一个向量,然后移动一步,再取m+1个元素构成一个向量,如此继续直到最后得到一个向量集合Xa,看有多少向量彼此的距离小于容忍度r(即有多少向量彼此相似,又称自相似个数)。
B:从0位置开始,取m个元素构成一个模板向量,然后移动一步,再取m个元素构成一个模板向量,如此继续直到最后得到一个向量集合Xb,看有多少向量彼此的距离小于容忍度r(即有多少向量彼此相似,又称自相似个数)。
而实际上A总是小于等于B的,所以A/B越接近1,预测难度越小,直觉上理解,应该就是波形前后部分之间的变化不大,那么整个时间序列的波动相对来说会比较纯(这也是熵的含义,熵越小,信息越纯,熵越大,信息越混乱),或者说会具有一定的规律,而如果A和B相差很大,则时间序列波动不纯,或者说几乎没有规律可言。
比如:U = [0.2, 0.6, 0.7, 1.2, 55, 66],m=2,
那么可以计算得到:
Xa = [[0.2, 0.6, 0.7], [0.6, 0.7, 1.2], [0.7, 1.2, 55.0], [1.2, 55.0, 66.0]]
Xb = [[0.2, 0.6], [0.6, 0.7], [0.7, 1.2], [1.2, 55.0], [55.0, 66.0]]
假设Xa中相似向量的个数比Xb多,那么应该出现Xa满足r,但是Xb不满足r的情况,但是拿Xa和Xb的前两个向量来分析,如果Xa满足r,则0.2-0.6 ,0.6-0.7,0.7-1.2中的最大值应该<=r,也就是说0.2-0.6 ,0.6-0.7肯定<=r,如此推断,Xb肯定也满足r, 所以只有可能出现Xb满足r,Xa不满足r的情况。- python实现
def SampEn(U, m, r):
"""
用于量化时间序列的可预测性
:param U: 时间序列
:param m: 模板向量维数
:param r: 距离容忍度,一般取0.1~0.25倍的时间序列标准差,也可以理解为相似度的度量阈值
:return: 返回一个-np.log(A/B),该值越小预测难度越小
"""
def _maxdist(x_i, x_j):
"""
Chebyshev distance
:param x_i:
:param x_j:
:return:
"""
return max([abs(ua - va) for ua, va in zip(x_i, x_j)])
def _phi(m):
x = [[U[j] for j in range(i, i + m - 1 + 1)] for i in range(N - m + 1)]
C = [len([1 for j in range(len(x)) if i != j and _maxdist(x[i], x[j]) <= r]) for i in range(len(x))]
return sum(C)
N = len(U)
return -np.log(_phi(m + 1) / _phi(m))
if __name__ == '__main__':
_U = [0.2, 0.6, 0.7, 1.2, 55, 66]
rand_small = np.random.randint(0, 100, size=120)
rand_big = np.random.randint(0, 100, size=136)
m = 2
print(SampEn(_U, m, r=0.2 * np.std(_U)))
print(SampEn(rand_small, m, r=0.2 * np.std(rand_small)))
print(SampEn(rand_big, m, r=0.2 * np.std(rand_big)))
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
用python做时间序列预测七:时间序列复杂度量化的更多相关文章
- python做中学(七)ord() 函数
描述 ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII ...
- 用python做时间序列预测一:初识概念
利用时间序列预测方法,我们可以基于历史的情况来预测未来的情况.比如共享单车每日租车数,食堂每日就餐人数等等,都是基于各自历史的情况来预测的. 什么是时间序列? 时间序列,是指同一个变量在连续且固定的时 ...
- 用python做时间序列预测九:ARIMA模型简介
本篇介绍时间序列预测常用的ARIMA模型,通过了解本篇内容,将可以使用ARIMA预测一个时间序列. 什么是ARIMA? ARIMA是'Auto Regressive Integrated Moving ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- Kesci: Keras 实现 LSTM——时间序列预测
博主之前参与的一个科研项目是用 LSTM 结合 Attention 机制依据作物生长期内气象环境因素预测作物产量.本篇博客将介绍如何用 keras 深度学习的框架搭建 LSTM 模型对时间序列做预测. ...
- facebook开源的prophet时间序列预测工具---识别多种周期性、趋势性(线性,logistic)、节假日效应,以及部分异常值
简单使用 代码如下 这是官网的quickstart的内容,csv文件也可以下到,这个入门以后后面调试加入其它参数就很简单了. import pandas as pd import numpy as n ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- 腾讯技术工程 | 基于Prophet的时间序列预测
预测未来永远是一件让人兴奋而又神奇的事.为此,人们研究了许多时间序列预测模型.然而,大部分的时间序列模型都因为预测的问题过于复杂而效果不理想.这是因为时间序列预测不光需要大量的统计知识,更重要的是它需 ...
- 时间序列 预测分析 R语言
在对短期数据的预测分析中,我们经常用到时间序列中的指数平滑做数据预测,然后根据不同. 下面我们来看下具体的过程 x<-data.frame(rq=seq(as.Date('2016-11-15' ...
随机推荐
- Mybatis【16】-- Mybatis多对一关联查询
注:代码已托管在GitHub上,地址是:https://github.com/Damaer/Mybatis-Learning ,项目是mybatis-12-many2one,需要自取,需要配置mave ...
- CSS 变量与运算
1.变量 变量声明:变量名使用 "--" 为前缀,且区分大小写 /* 全局变量 */ :root{ --bgColor: red; } /* 布局变量 */ p{ --bgColo ...
- 【读书笔记】 深入理解JVM第三版 JVM 运行时数据区
JVM 内存管理 堆 (Heap)线程共享 方法区 (Method Area)线程共享 虚拟机栈(VM Stack) 线程私有 本地方法栈 (Native Method Stack)线程私有 程序计数 ...
- Flutter 滑动组件互相嵌套问题
滑动组件互相嵌套问题 如果listview/singlechildscrollview 嵌套gridview,将两个组件的shrinkwrap设置为true,并且gridview无法滚动 physic ...
- k8s pod重启 deployment重启
1.15版本之后可通过kubectl rollout restart deployment -n 命令来实现滚动重启POD 该命令会先创建待用POD,待新POD运行成功后,再关闭原有POD.因此需要保 ...
- Qt编写的项目作品30-录音播放控件(雨田哥作品)
一.功能特点 使用FMOD音频引擎开发,支持跨平台,虚拟频道,插件设计. 数字回放,多个声卡,多路输出,多路输入. 自定义回放延迟,网络特性. 支持类型:DLS.M3U.ASX.WAX.PLS.AIF ...
- 如何使用图片的exif信息计算相机焦距
135胶卷源于35mm高度的打孔电影胶片,1913年,德国人奥斯卡·巴纳克将其用于他发明的徕卡(Leica)牌小型照相机上,由此形成标准.35mm电影胶卷,35mm指的是胶卷的高度为35mm,由于上下 ...
- Mysql - com.mysql.jdbc.Driver与com.mysql.cj.jdbc.Driver的区别
spring常用dataSource配置如下: spring: datasource: username: root password: root url: jdbc:mysql://localhos ...
- HVV面试
linux日志管理 1. 检查系统帐号安全(1) /etc/passwd(2) /etc/shadow(3) 特权用户(uid==0)awk -F: '$3==0{print $1}' /etc/pa ...
- .NetCore依赖注入(DI)之生命周期
在 .NET Core 中,依赖注入(Dependency Injection,DI)是一种实现控制反转(Inversion of Control,IoC)的技术,它通过将依赖对象注入到需要它们的对象 ...