卷积神经网络(LeNet)
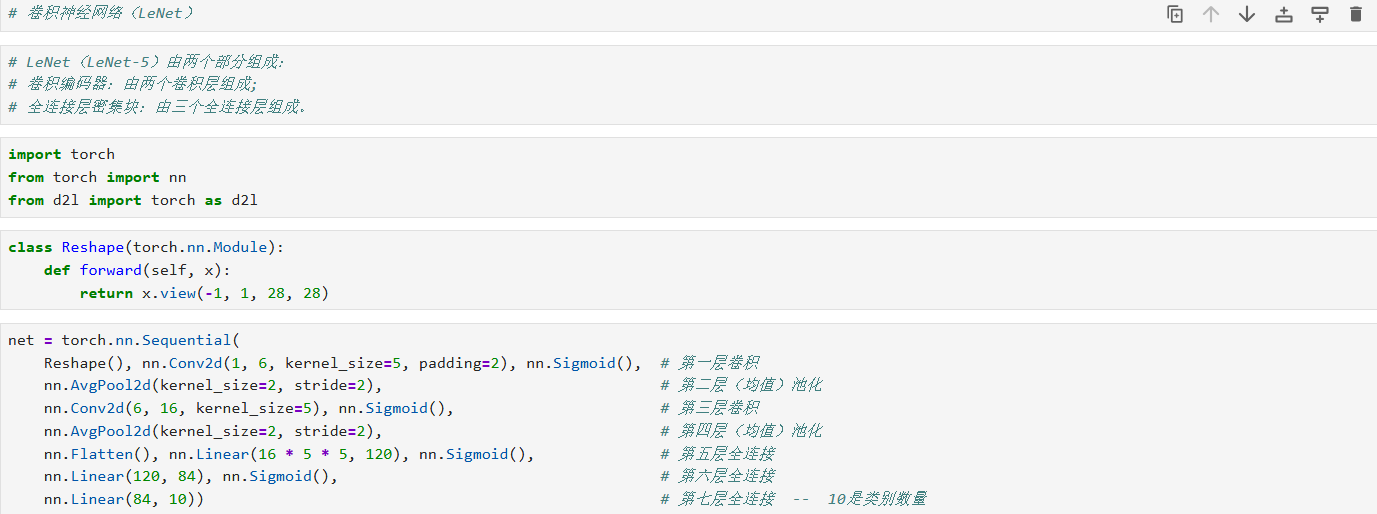


一、导入所用库
import torch
from torch import nn
from d2l import torch as d2l

二、自定义重塑层
class Reshape(nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)

三、构建 LeNet 网络

net = nn.Sequential(
Reshape(), # 将输入 (batch, 784) → (batch, 1, 28, 28)
nn.Conv2d(1, 6, kernel_size=5, padding=2), # 卷积层1:输入通道 1 → 输出通道 6,卷积核 5×5,padding=2 保持宽高不变
nn.Sigmoid(), # 激活函数:Sigmoid
nn.AvgPool2d(kernel_size=2, stride=2), # 平均池化1:kernel=2, stride=2,下采样一半
nn.Conv2d(6, 16, kernel_size=5), # 卷积层2:6→16,kernel=5×5,默认无 padding → 尺寸缩小
nn.Sigmoid(), # Sigmoid 激活
nn.AvgPool2d(kernel_size=2, stride=2), # 平均池化2
nn.Flatten(), # 展平:把多维特征图拉成一维向量
nn.Linear(16 * 5 * 5, 120), # 全连接层1:输入 16×5×5 → 输出 120
nn.Sigmoid(), # Sigmoid 激活
nn.Linear(120, 84), # 全连接层2:120 → 84
nn.Sigmoid(), # Sigmoid 激活
nn.Linear(84, 10) # 输出层:84 → 10 类别
)

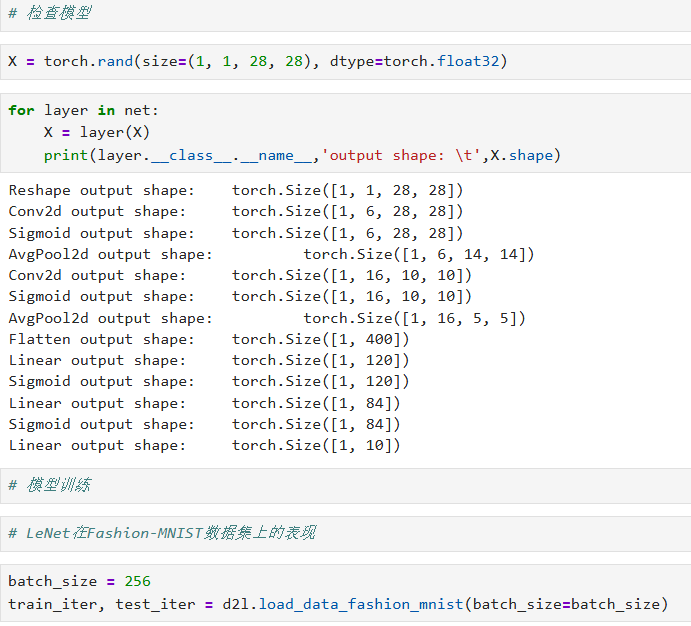
四、验证每层输出形状
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)


五、加载 Fashion-MNIST 数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)

六、定义 GPU 下的准确率评估函数
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""在 GPU 上评估模型在给定数据集上的准确率"""
if isinstance(net, nn.Module):
net.eval() # 切换到评估模式,关闭 dropout、batchnorm 等
if not device:
device = next(iter(net.parameters())).device
# metric[0] 累积正确预测数;metric[1] 累积样本总数
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
X, y = X.to(device), y.to(device)
y_hat = net(X)
metric.add(d2l.accuracy(y_hat, y), y.numel())
return metric[0] / metric[1]
七、定义训练函数(带 GPU 支持)
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
# 1. 权重初始化:对每个线性层和卷积层使用 Xavier 均匀分布初始化
def init_weights(m):
if type(m) in (nn.Linear, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device) # 把模型参数搬到指定设备
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
# 可视化工具:训练过程实时画图
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
# 2. 训练循环
for epoch in range(num_epochs):
# 累积训练损失、训练正确预测数、样本数
metric = d2l.Accumulator(3)
net.train() # 切回训练模式
for i, (X, y) in enumerate(train_iter):
timer.start()
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * y.numel(), d2l.accuracy(y_hat, y), y.numel())
timer.stop()
# 每训练完一个 epoch,或者到达最后一个 batch 时更新可视化
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2], None))
# 每个 epoch 结束后计算一次测试集准确率并更新图示
test_acc = evaluate_accuracy_gpu(net, test_iter, device)
animator.add(epoch + 1, (None, None, test_acc))
# 输出整体训练速度
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {device}')

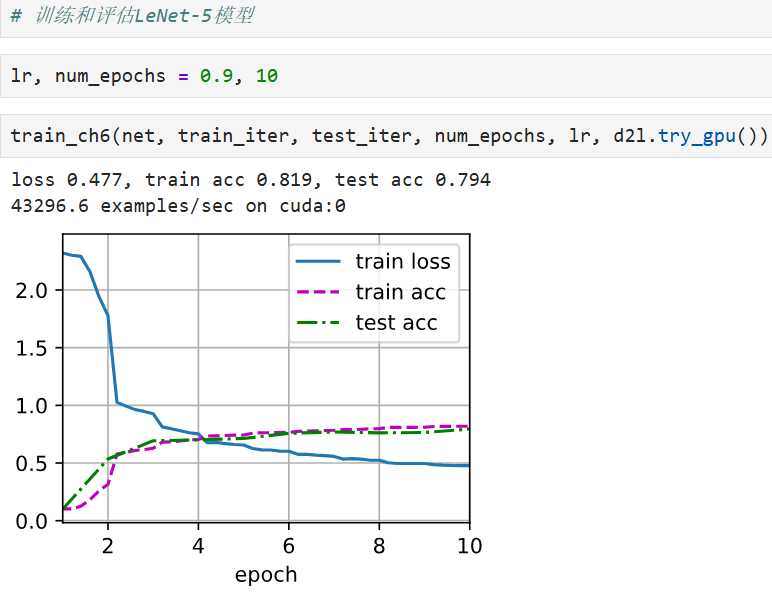
八、运行训练
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

九、总结

十、流程概览
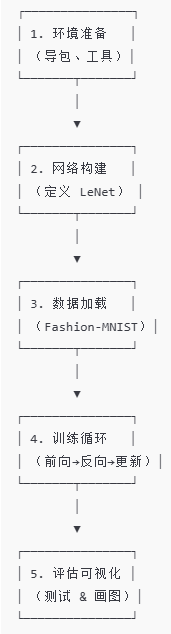
1. 环境准备

2. 网络构建

3. 数据加载

4. 训练循环
for epoch in 1…N:
for 每个 batch (X, y):
1) 前向计算 ŷ = net(X)
2) 计算损失 L = Loss(ŷ, y)
3) 反向传播 L.backward()
4) 优化器更新参数 optimizer.step()
5) 累积训练损失 & 正确率
end-for
# 每跑完一个 epoch:
- 在测试集上评估一次准确率
- 把训练损失、训练准确率、测试准确率推到“动画器”里,实时画图
end-for

5. 评估与可视化

6. 通俗小结


卷积神经网络(LeNet)的更多相关文章
- TensorFlow+实战Google深度学习框架学习笔记(12)------Mnist识别和卷积神经网络LeNet
一.卷积神经网络的简述 卷积神经网络将一个图像变窄变长.原本[长和宽较大,高较小]变成[长和宽较小,高增加] 卷积过程需要用到卷积核[二维的滑动窗口][过滤器],每个卷积核由n*m(长*宽)个小格组成 ...
- 使用mxnet实现卷积神经网络LeNet
1.LeNet模型 LeNet是一个早期用来识别手写数字的卷积神经网络,这个名字来源于LeNet论文的第一作者Yann LeCun.LeNet展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当 ...
- 卷积神经网络LeNet Convolutional Neural Networks (LeNet)
Note This section assumes the reader has already read through Classifying MNIST digits using Logisti ...
- 卷积神经网络之LeNet
开局一张图,内容全靠编. 上图引用自 [卷积神经网络-进化史]从LeNet到AlexNet. 目前常用的卷积神经网络 深度学习现在是百花齐放,各种网络结构层出不穷,计划梳理下各个常用的卷积神经网络结构 ...
- 卷积神经网络详细讲解 及 Tensorflow实现
[附上个人git完整代码地址:https://github.com/Liuyubao/Tensorflow-CNN] [如有疑问,更进一步交流请留言或联系微信:523331232] Reference ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- 卷积神经网络的一些经典网络(Lenet,AlexNet,VGG16,ResNet)
LeNet – 5网络 网络结构为: 输入图像是:32x32x1的灰度图像 卷积核:5x5,stride=1 得到Conv1:28x28x6 池化层:2x2,stride=2 (池化之后再经过激活函数 ...
- 从LeNet到SENet——卷积神经网络回顾
从LeNet到SENet——卷积神经网络回顾 从 1998 年经典的 LeNet,到 2012 年历史性的 AlexNet,之后深度学习进入了蓬勃发展阶段,百花齐放,大放异彩,出现了各式各样的不同网络 ...
- LeNet - Python中的卷积神经网络
本教程将 主要面向代码, 旨在帮助您 深入学习和卷积神经网络.由于这个意图,我 不会花很多时间讨论激活功能,池层或密集/完全连接的层 - 将来会有 很多教程在PyImageSearch博客上将 ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
随机推荐
- gRPC+Proto 实现键盘记录器 —— 深度实战解析
在当今的分布式系统开发领域,RPC(Remote Procedure Call,远程过程调用) 技术犹如一颗璀璨的明星,凭借其强大的透明性和卓越的高性能,在微服务架构中占据着举足轻重的地位.本文将全方 ...
- Mybatis的*Dao.XML中的配置与其对应的接口、resultMap的运用
例子. <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC &quo ...
- 备注一下,SolidColorBrush,自定义颜色
new SolidColorBrush((Color)ColorConverter.ConvertFromString("#27212B"))
- PowerShell : 无法加载文件 xxx.ps1,因为在此系统上禁止运行脚本(npm或yarn)
1.搜索powershell,右键以管理员身份运行 2.若要在本地计算机上运行您编写的未签名脚本和来自其他用户的签名脚本,请使用以下命令将计算机上的 执行策略更改为 RemoteSigned 执行 s ...
- Linux设置每晚定时备份Oracle数据表
先新建目录 该路径:/home/oracle/backup 该名称:DATA_PATH shell脚本 export ORACLE_BASE=/home/oracle/app export ORACL ...
- 【翻译】Processing系列|(二)安卓模式的安装使用及打包发布
上一篇:[翻译]Processing系列|(一)简介及使用方法 下一篇:[翻译] Processing系列|(三)安卓项目构建 我的目的是在学习完成之后写出一个安卓程序,所以第二篇就是Processi ...
- RandomAccessFile、FileInputStream、MappedByteBuffer、FileChannel 区别及应用场景
RandomAccessFile.FileInputStream.MappedByteBuffer.FileChannel 比较 这些类都是Java中用于文件I/O操作的类,但各有特点和适用场景.下面 ...
- .net core workflow流程定义
.net core workflow流程定义 WikeFlow官网:http://www.wikesoft.com WikeFlow学习版演示地址:http://workflow.wikesoft.c ...
- 双向 和 多重 RNN
前面已经对 RNN (递归神经网络) 的变体 (主要为解决 梯度消失和梯度爆炸) 接触了两个比较流行的 LSTM 和 GRU, 其核心思想呢, 是通过其所谓 **"gate" ** ...
- the server time zone value ‘�й���ʱ��‘ is unrecognized or represents more than one time zone.
分析:数据库和系统时区差异造成 解决:在jdbc连接的url后面加上 &serverTimezone=GMT