Scrapy案例01-爬取传智播客主页上的老师信息
1. 新建scrapy项目
scrapy startproject mySpider
得到了如下的文件

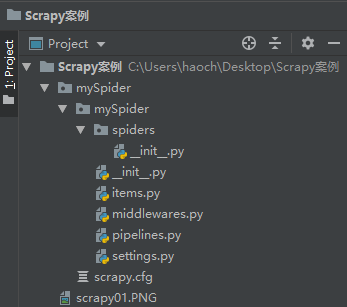
其内部文件结构如下:
2. 爬虫文件:
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
2.1. 查看需要爬取内容存在哪里:
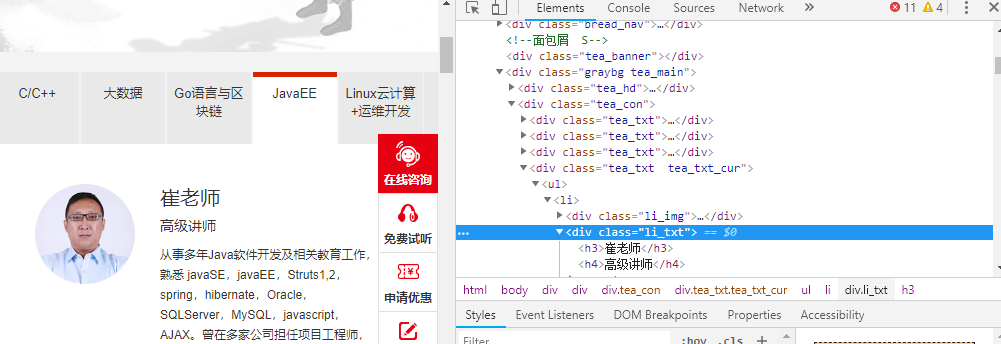
我们可以通过response.xpath提取相关内容
for each in reponse.xpath('//div[@class = "li_txt"]'):
name = each.xpath('./h3/text()')
title = each.xpath('./h4/text()')
info = each.xpath('./p/text()')
2.2. 设置item需要保存的数据变量
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
2.3. 创建爬虫文件
- 在mySpider下的spiders文件夹下创建一个新的爬虫文件命名为
itcastspider.py
import scrapy
from mySpider.items import MyspiderItem
# 创建一个爬虫
class ItcaseSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowed_domains = ['http://www.itcast.cn/']
# 爬虫开始的url
start_urls = ["http://www.itcast.cn/channel/teacher.shtml#ajavaee"]
# setting -> name -> allowed_domains ->start_urls -> request
# request -> scrapy engine -> scheduler -> downloader -> download from inetrnet(自动执行)
# Downloader -> spider ->调用parse方法
def parse(self, response):
# with open("teacher.html", 'wb') as f:
# f.write(response.body) # 读取响应文件内容
# 所有老师列表集合
teacherItem = []
for each in response.xpath('//div[@class = "li_txt"]'):
# 将我们得到的数据封装到一个 `MyspiderItem` 对象
item = MyspiderItem()
# 通过extract()转换为unicode字符串
# 不加extract()就是xpath匹配的对象而已
name = each.xpath('./h3/text()').extract() # xpath返回的都是列表,元素根据匹配规则来(e.g. text())
title = each.xpath('./h4/text()').extract()
info = each.xpath('./p/text()').extract()
item['name'] = name [0]
item['title'] = title[0]
item['info'] = info[0]
teacherItem.append(item)
# 直接返回数据,用于保存类型
return teacherItem
2.4. 保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
2.5. yield的用法
我们可以将上面的return方法换成yield为一个生成迭代器
- yield每一次都传递给一个数据给管道文件
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
- yield传递的管道文件需要重写
import json
class ItcastPipeline(object):
# __init__可选的,初始化文件
def __init__(self):
self.filename = open("yieldmethod.json", "wb")
# 处理Item数据的,必须写的
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.filename.write(jsontext.encode("utf-8"))
return item
# 可选的,执行结束时的方法
def close_spider(self,spider):
self.filename.close()
3. 在PyCharm中运行scrapy
3.1. 方法一: 直接走PyCharm中的terminal中执行
3.2. 方法二: 新建start.py并添加到configration中
from scrapy import cmdline
cmdline.execute("scrapy crawl itcast".split())
4. 结果

Scrapy案例01-爬取传智播客主页上的老师信息的更多相关文章
- web开发流程(传智播客-方立勋老师)
1.搭建开发环境 1.1 导入项目所需的开发包 dom4j-1.6.1.jar jaxen-1.1-beta-6.jar commons-beanutils-1.8.0.jar commons-log ...
- 揭秘上海传智播客平均工资超过7k
其中一位知情人士
大学毕业生人数破700万大关.如何破解"毕业即失业"中国式的大学困境? 2014年全国高校毕业生总数将达到727万人,比被称为"史上最难就业年"的2013年再添 ...
- 揭秘传智播客班级毕业薪资超7k的内幕系列 之三 ----国企慕名而来,将未毕业学员“抢走”,传智播客又一次定义“被就业”
前面文章提及Java六期学员张同学提前就业某国企,入职薪资6.3k,各种福利齐全.作为班级首位就业同学,他的就业也成为了班级其它同学就业的风向标.但事实上张同学的就业属于"被就业" ...
- 传智播客JDBC视频教程
视频介绍: 一些视频教程通过浅显案例来让刚開始学习的人感到轻松,可是课程中编写的代码不能直接应用于项目中:而本套视频教程正好相反,视频解说者李勇老师以技术见长.性格朴实无华.不善于幽默搞笑.李勇老师编 ...
- 揭秘传智播客毕业班的超级薪水7k内幕系列II----Offer工资表5.7k,为什么不能让老师就业就业
在上海传智播客宋学生Java六期学员.在班级尚未毕业阶段,私自投递简历,而且逃课去面试,获得某国企的Offer.入职薪资5.7K,,兼有五险一金.饭补等齐全福利,因就业老师要求班级同学未毕业不要急于就 ...
- 成都传智播客JDBC视频及讲师介绍
成都传智播客java讲师,也许,你跟他很熟,你或者听过他的课,或者跟他争论过什么,又或者你们在一起共事,再者你们只是偶尔擦肩而过.在小编的印象中郭老师完全没有架子,和他相处会让你觉得不是面对一个老师, ...
- 揭秘传智播客班级毕业薪资超7k的内幕系列之四----汽车工的华丽转身
---不是本科毕业?不是计算机专业?做过电子厂?做过数控?看传智中专生侃项目,"侃晕"项目经理.从流水线上华丽转身,8.5k高薪再就业 系列三承诺写写上海传智J ...
- 传智播客C语言视频第二季(第一季基础上增加诸多C语言案例讲解,有效下载期为10.5-10.10关闭)
卷 backup 的文件夹 PATH 列表卷序列号为 00000025 D4A8:14B0J:.│ 1.txt│ c语言经典案例效果图示.doc│ ├─1传智播客_尹成_C语言从菜鸟到高手_第一 ...
- 传智播客张孝祥java邮件开发随笔01
01_传智播客张孝祥java邮件开发_课程价值与目标介绍 02_传智播客张孝祥java邮件开发_邮件方面的基本常识 03_传智播客张孝祥java邮件开发_手工体验smtp和pop3协议 第3课时 关于 ...
随机推荐
- Webpack+Vue如何导入Jquery和Jquery的第三方插件
创建一个jquery-vendor.js文件 import $ from 'jQuery'; console.log($); window.$ = $; window.jQuery = $; expo ...
- Python爬虫入门教程 4-100 美空网未登录图片爬取
美空网未登录图片----简介 上一篇写的时间有点长了,接下来继续把美空网的爬虫写完,这套教程中编写的爬虫在实际的工作中可能并不能给你增加多少有价值的技术点,因为它只是一套入门的教程,老鸟你自动绕过就可 ...
- 从锅炉工到AI专家(5)
图像识别基本原理 从上一篇开始,我们终于进入到了TensorFlow机器学习的世界.采用第一个分类算法进行手写数字识别得到了一个91%左右的识别率结果,进展可喜,但成绩尚不能令人满意. 结果不满意的原 ...
- 菜鸟系列docker——docker基本概念(1)
docker基本概念 1.准备 这里先介绍容器技术,后续再介绍docker.docker是容器的一种,除docker以外,还存在coreos.不过在当前趋势下容器和docker基本上可以划为等号了. ...
- DHTMLX 常用技术
GRID的行设置前景色和背景色 $dataItem->set_row_color("red"); // 设置背景色 $dataItem->set_row_style(& ...
- 【.NET Core项目实战-统一认证平台】第十五章 网关篇-使用二级缓存提升性能
[.NET Core项目实战-统一认证平台]开篇及目录索引 一.背景 首先说声抱歉,可能是因为假期综合症(其实就是因为懒哈)的原因,已经很长时间没更新博客了,现在也调整的差不多了,准备还是以每周1-2 ...
- .Net语言 APP开发平台——Smobiler学习日志:在应用中添加WeiXin组件
最前面的话:Smobiler是一个在VS环境中使用.Net语言来开发APP的开发平台,也许比Xamarin更方便 控件说明 WeiXin组件. 效果演示 1. 分享好友 2. 分享朋友圈 图1 图2 ...
- 分享一些 Windows 平台上的神器
下面分享一些 Windows 平台上日常开发使用的软件,有些软件我自认为是神器,可以大大提高效率. 编辑器类软件 IntelliJ IDEA IntelliJ IDEA 内部集成 Java 开发环境, ...
- 面向对象的一小步:添加ActiveRecord的Scope功能
问题场景 我们用Yii2的ActiveRecord功能非常的方便,假如我们有个Model叫Student,那么ActiveQuery可以通过这种方式轻便地获得: $query = Student::f ...
- 浏览器与Node的事件循环(Event Loop)有何区别?
前言 本文我们将会介绍 JS 实现异步的原理,并且了解了在浏览器和 Node 中 Event Loop 其实是不相同的. 一.线程与进程 1. 概念 我们经常说 JS 是单线程执行的,指的是一个进程里 ...