Scrapy案例01-爬取传智播客主页上的老师信息
1. 新建scrapy项目
scrapy startproject mySpider
得到了如下的文件

其内部文件结构如下:
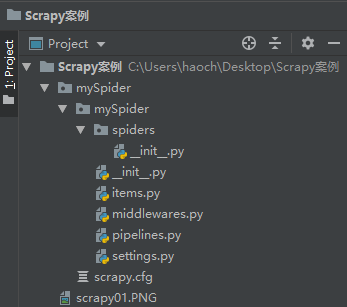
2. 爬虫文件:
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
2.1. 查看需要爬取内容存在哪里:
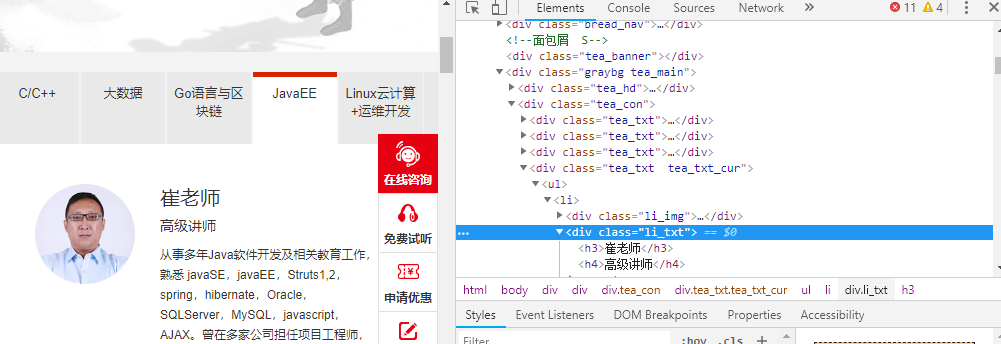
我们可以通过response.xpath提取相关内容
for each in reponse.xpath('//div[@class = "li_txt"]'):
name = each.xpath('./h3/text()')
title = each.xpath('./h4/text()')
info = each.xpath('./p/text()')
2.2. 设置item需要保存的数据变量
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
2.3. 创建爬虫文件
- 在mySpider下的spiders文件夹下创建一个新的爬虫文件命名为
itcastspider.py
import scrapy
from mySpider.items import MyspiderItem
# 创建一个爬虫
class ItcaseSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowed_domains = ['http://www.itcast.cn/']
# 爬虫开始的url
start_urls = ["http://www.itcast.cn/channel/teacher.shtml#ajavaee"]
# setting -> name -> allowed_domains ->start_urls -> request
# request -> scrapy engine -> scheduler -> downloader -> download from inetrnet(自动执行)
# Downloader -> spider ->调用parse方法
def parse(self, response):
# with open("teacher.html", 'wb') as f:
# f.write(response.body) # 读取响应文件内容
# 所有老师列表集合
teacherItem = []
for each in response.xpath('//div[@class = "li_txt"]'):
# 将我们得到的数据封装到一个 `MyspiderItem` 对象
item = MyspiderItem()
# 通过extract()转换为unicode字符串
# 不加extract()就是xpath匹配的对象而已
name = each.xpath('./h3/text()').extract() # xpath返回的都是列表,元素根据匹配规则来(e.g. text())
title = each.xpath('./h4/text()').extract()
info = each.xpath('./p/text()').extract()
item['name'] = name [0]
item['title'] = title[0]
item['info'] = info[0]
teacherItem.append(item)
# 直接返回数据,用于保存类型
return teacherItem
2.4. 保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
2.5. yield的用法
我们可以将上面的return方法换成yield为一个生成迭代器
- yield每一次都传递给一个数据给管道文件
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#items.append(item)
#将获取的数据交给pipelines
yield item
- yield传递的管道文件需要重写
import json
class ItcastPipeline(object):
# __init__可选的,初始化文件
def __init__(self):
self.filename = open("yieldmethod.json", "wb")
# 处理Item数据的,必须写的
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.filename.write(jsontext.encode("utf-8"))
return item
# 可选的,执行结束时的方法
def close_spider(self,spider):
self.filename.close()
3. 在PyCharm中运行scrapy
3.1. 方法一: 直接走PyCharm中的terminal中执行
3.2. 方法二: 新建start.py并添加到configration中
from scrapy import cmdline
cmdline.execute("scrapy crawl itcast".split())
4. 结果

Scrapy案例01-爬取传智播客主页上的老师信息的更多相关文章
- web开发流程(传智播客-方立勋老师)
1.搭建开发环境 1.1 导入项目所需的开发包 dom4j-1.6.1.jar jaxen-1.1-beta-6.jar commons-beanutils-1.8.0.jar commons-log ...
- 揭秘上海传智播客平均工资超过7k
其中一位知情人士
大学毕业生人数破700万大关.如何破解"毕业即失业"中国式的大学困境? 2014年全国高校毕业生总数将达到727万人,比被称为"史上最难就业年"的2013年再添 ...
- 揭秘传智播客班级毕业薪资超7k的内幕系列 之三 ----国企慕名而来,将未毕业学员“抢走”,传智播客又一次定义“被就业”
前面文章提及Java六期学员张同学提前就业某国企,入职薪资6.3k,各种福利齐全.作为班级首位就业同学,他的就业也成为了班级其它同学就业的风向标.但事实上张同学的就业属于"被就业" ...
- 传智播客JDBC视频教程
视频介绍: 一些视频教程通过浅显案例来让刚開始学习的人感到轻松,可是课程中编写的代码不能直接应用于项目中:而本套视频教程正好相反,视频解说者李勇老师以技术见长.性格朴实无华.不善于幽默搞笑.李勇老师编 ...
- 揭秘传智播客毕业班的超级薪水7k内幕系列II----Offer工资表5.7k,为什么不能让老师就业就业
在上海传智播客宋学生Java六期学员.在班级尚未毕业阶段,私自投递简历,而且逃课去面试,获得某国企的Offer.入职薪资5.7K,,兼有五险一金.饭补等齐全福利,因就业老师要求班级同学未毕业不要急于就 ...
- 成都传智播客JDBC视频及讲师介绍
成都传智播客java讲师,也许,你跟他很熟,你或者听过他的课,或者跟他争论过什么,又或者你们在一起共事,再者你们只是偶尔擦肩而过.在小编的印象中郭老师完全没有架子,和他相处会让你觉得不是面对一个老师, ...
- 揭秘传智播客班级毕业薪资超7k的内幕系列之四----汽车工的华丽转身
---不是本科毕业?不是计算机专业?做过电子厂?做过数控?看传智中专生侃项目,"侃晕"项目经理.从流水线上华丽转身,8.5k高薪再就业 系列三承诺写写上海传智J ...
- 传智播客C语言视频第二季(第一季基础上增加诸多C语言案例讲解,有效下载期为10.5-10.10关闭)
卷 backup 的文件夹 PATH 列表卷序列号为 00000025 D4A8:14B0J:.│ 1.txt│ c语言经典案例效果图示.doc│ ├─1传智播客_尹成_C语言从菜鸟到高手_第一 ...
- 传智播客张孝祥java邮件开发随笔01
01_传智播客张孝祥java邮件开发_课程价值与目标介绍 02_传智播客张孝祥java邮件开发_邮件方面的基本常识 03_传智播客张孝祥java邮件开发_手工体验smtp和pop3协议 第3课时 关于 ...
随机推荐
- BBS论坛(十)
10.1.客户端权限验证功能完成 (1)cms/cms_profile 显示当前用户的角色和权限 <tr> <td>角色:</td> <td> {% f ...
- metasploit无法连接postgresql
注:倒数两条可以不做. 问题地址:https://askubuntu.com/questions/50621/cannot-connect-to-postgresql-on-port-5432 设置好 ...
- 如何写好css系列之button
现代前端行业的发展,如果你在css的时候,还没有利用一些预编译工具,是否觉得自己太low了.但你是否考虑过搭建一套自己前端框架.可能你会想这是否有必要,因为基础有boostrap,组件库有:easyu ...
- 并发编程(十六)——java7 深入并发包 ConcurrentHashMap 源码解析
以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容 ...
- Python爬虫入门教程 19-100 51CTO学院IT技术课程抓取
写在前面 从今天开始的几篇文章,我将就国内目前比较主流的一些在线学习平台数据进行抓取,如果时间充足的情况下,会对他们进行一些简单的分析,好了,平台大概有51CTO学院,CSDN学院,网易云课堂,慕课网 ...
- kubernetes进阶之一:简单例子
kubernetes 从一个简单例子开始 参考 <kubernetes 权威指南>一节的 从一个简单例子开始,操作实录. 一.Java Web 应用结构 二.启动MySql服务 1.首先为 ...
- 解读经典《C#高级编程》最全泛型协变逆变解读 页127-131.章4
前言 本篇继续讲解泛型.上一篇讲解了泛型类的定义细节.本篇继续讲解泛型接口. 泛型接口 使用泛型可定义接口,即在接口中定义的方法可以带泛型参数.然后由继承接口的类实现泛型方法.用法和继承泛型类基本没有 ...
- Linux之部署前后端分离项目
首先得看我前两个博客,把python3,虚拟环境,mariadb数据库,redis数据库,nginx安装好. 一.创建一个虚拟环境 1,创建虚拟环境 mkvirtualenv zijin #创建了一个 ...
- JS_正则表达式_获取指定字符之后指定字符之前的字符串
一个常见的场景,获取:标签背景图片链接: 如字符串:var bgImg = "url(\"https://img30.360buyimg.com/sku/jfs/t26203/26 ...
- C# 合并Excel工作表
文档合并.拆分是实现文档管理的一种有效方式.在工作中,我们可能会遇到需要将多个文档合并的情况,那如何来实现呢,本文将进一步介绍.关于拆分Excel工作表,可参见这篇文章——C#如何拆分EXCEL工作表 ...