快速比较 Kafka 与 Message Queue 的区别
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8
A super quick comparison between Kafka and Message Queues

This article’s aim is to give you a very quick overview of how Kafka relates to queues, and why you would consider using it instead.
Kafka is a piece of technology originally developed by the folks at Linkedin. In a nutshell, it’s sort of like a message queueing system with a few twists that enable it to support pub/sub, scaling out over many servers, and replaying of messages.
These are all concerns when you want to adopt a reactive programming style over an imperative programming style.
The difference between imperative programming and reactive programming
Imperative programming is the type of programming we all start out with. Something happens, in other words an event occurs, and your code is notified of that event. For example, a user clicked a button and where you handle the event in your code, you decide what that action should mean to your system. You might save records to a DB, call another service, send an email, or a combination of all of these. The important bit here, is that the event is directly coupled to specific actions taking place.
Reactive programming enables you to respond to events that occur, often in the form of streams. Multiple concerns can subscribe to the same event and let the event have it’s effect in it’s domain, regardless of what happens in other domains. In other words, it allows for loosely coupled code that can easily be extended with more functionality. It’s possible that various big down-stream systems coded in different stacks are affected by an event, or even a whole bunch of serverless functions executing somewhere in the cloud.
From queues to Kafka
To understand what Kafka will bring to your architecture, let’s start by talking about message queues. We’ll start here, because we will talk about it’s limitations and then see how Kafka solves them.
A message queue allows a bunch of subscribers to pull a message, or a batch of messages, from the end of the queue. Queues usually allow for some level of transaction when pulling a message off, to ensure that the desired action was executed, before the message gets removed.
Not all queueing systems have the same functionality, but once a message has been processed, it gets removed from the queue. If you think about it, it’s very similar to imperative programming, something happened, and the originating system decided that a certain action should occur in a downstream system.
Even though you can scale out with multiple consumers on the queue, they will all contain the same functionality, and this is done just to handle load and process messages in parallel, in other words, it doesn’t allow you to kick off multiple independent actions based on the same event. All the processors of of the queue messages will execute the same type of logic in the same domain. This means that the messages in the queue are actually commands, which is suited towards imperative programming, and not an event, which is suited towards reactive programming.

With queues, you generally execute the same logic in the same domain for every message on the queue
With Kafka on the other hand, you publish messages/events to topics, and they get persisted. They don’t get removed when consumers receive them. This allows you to replay messages, but more importantly, it allows a multitude of consumers to process logic based on the same messages/events.
You can still scale out to get parallel processing in the same domain, but more importantly, you can add different types of consumers that execute different logic based on the same event. In other words, with Kafka, you can adopt a reactive pub/sub architecture.
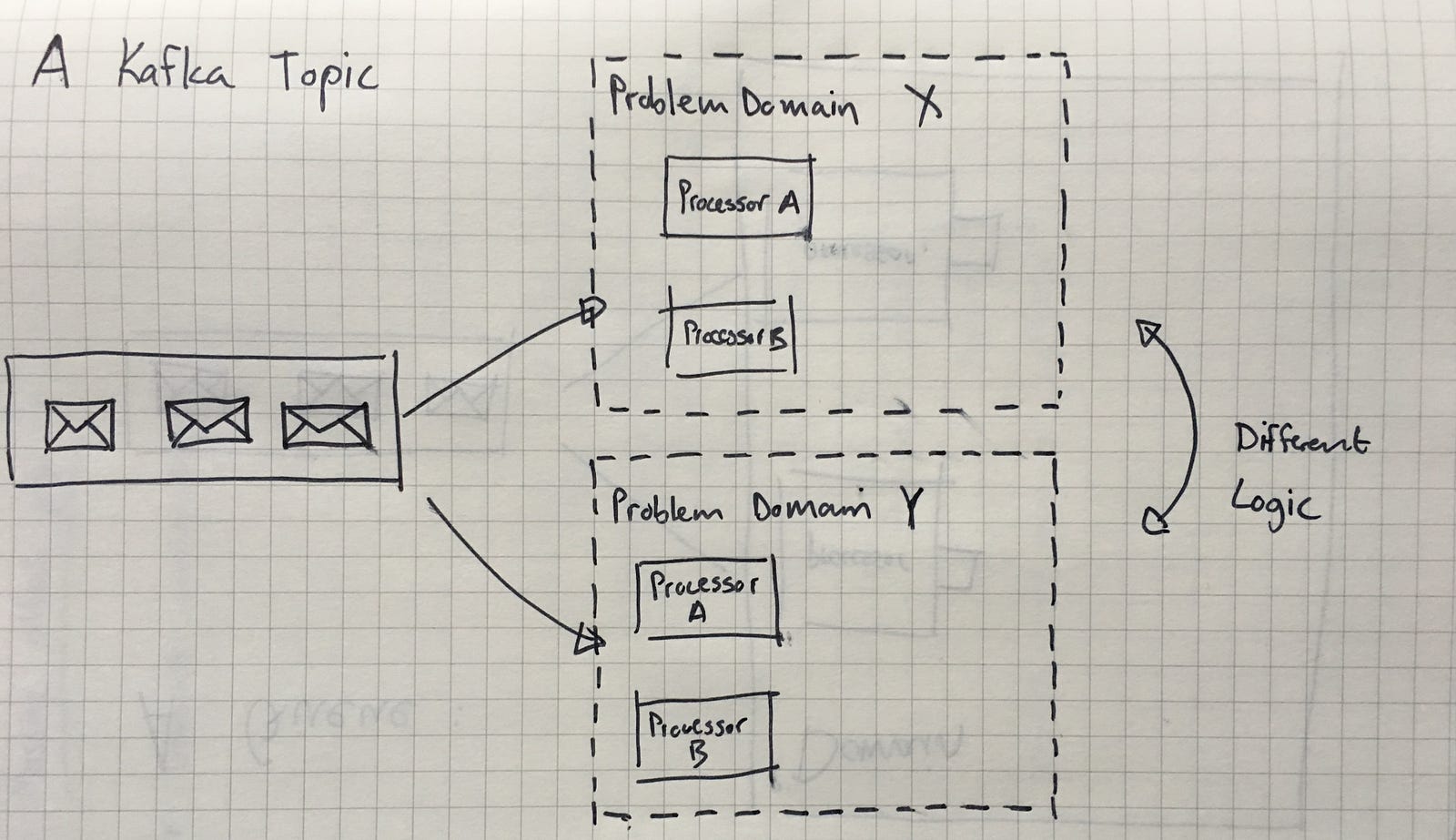
Different logic can be executed by different systems based on the same events
This is possible with Kafka due to the fact that messages are retained and the concept of consumer groups. Consumer groups in Kafka identify themselves to Kafka when they ask for messages on a topic. Kafka will record which messages (offset) were delivered to which consumer group, so that it doesn’t serve it up again. Actually, it is a bit more complex than that, because you have a bunch of configuration options available to control this, but we don’t need to explore the options fully just to understand Kafka at a high level.
Summary
There is a bunch more to Kafka, for example how it manages scaling out (partitions), configuration options for reliable messaging, etc. But my hope is that this article was good enough to let you understand why you would consider adopting Kafka over good ‘ol message queues.
快速比较 Kafka 与 Message Queue 的区别的更多相关文章
- 为什么要用Message Queue
摘录自博客:http://dataunion.org/9307.html?utm_source=tuicool&utm_medium=referral 为什么要用Message Queue 解 ...
- Message Queue的使用目的
为什么要用Message Queue 摘录自博客:http://dataunion.org/9307.html?utm_source=tuicool&utm_medium=referral ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- 消息队列(Message Queue)基本概念(转)
背景 之前做日志收集模块时,用到flume.另外也有的方案,集成kafaka来提升系统可扩展性,其中涉及到消息队列当时自己并不清楚为什么要使用消息队列.而在我自己提出的原始日志采集方案中不适用消息队列 ...
- Top 10 Uses For A Message Queue
We’ve been working with, building, and evangelising message queues for the last year, and it’s no se ...
- MSMQ(Microsoft Message Queue)
http://www.cnblogs.com/sk-net/archive/2011/11/25/2232341.html 利用 MSMQ(Microsoft Message Queue),应用程序开 ...
- 快速理解Kafka分布式消息队列框架
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ ==是什么 == 简单的说,K ...
- [转载] 快速理解Kafka分布式消息队列框架
转载自http://blog.csdn.net/xiaolang85/article/details/18048631 ==是什么 == 简单的说,Kafka是由Linkedin开发的一个分布式的消息 ...
- 消息队列(Message Queue)简介及其使用
消息队列(Message Queue)简介及其使用 摘要:利用 MSMQ(Microsoft Message Queue),应用程序开发人员可以通过发送和接收消息方便地与应用程序进行快速可靠的通信.消 ...
随机推荐
- 从Scratch到Python——Python生成二维码
# Python利用pyqrcode模块生成二维码 import pyqrcode import sys number = pyqrcode.create('从Scratch到Python--Pyth ...
- react native 项目使用 expo 二维码扫描失败
今天学习react native,需使用expo在移动端进行调试. npm start 运行项目后,使用expo扫描二维码,始终没有反应.于是决定采用这个方法: 连上手机打开usb调试后,按下‘a’, ...
- 删除List集合中的元素方法
List集合是我们平时使用的最多的集合了,一般用来存放从数据库中查询的对象数据,但有时我们会从中筛选不需要的数据,第一次使用这种方式: 使用增强for循环遍历,使用list的remove方法删除不符合 ...
- npm ERR! File exists: /XXX/xxx npm ERR! Move it away, and try again.
今天抽空将我的静态服务 ks-server 之前留下的 bug(在node低版本情况下报错)维护了一下. 当我重新 npm link 时,如下错误: npm WARN ks-server@1.0.2 ...
- Mac 下eclipse安装Lombok插件
在官网下载最新版本的 JAR 包. 将 lombok.jar 放在eclipse安装目录下,和 eclipse.ini 文件平级的. 注意,mac操作系统下eclipse的安装路径下有两个eclips ...
- Hadoop之HDFS的Shell操作
1.基本语法 bin/hadoop fs 具体命令 或者 bin/hdfs dfs 具体命令 dfs 是 fs 的实现类. 2.命令大全 [hadoop@hadoop102 hadoop-]$ bin ...
- java.lang.NoClassDefFoundError: org/apache/juli/logging/LogFactory的解决
java.lang.NoClassDefFoundError: org/apache/juli/logging/LogFactory的解决 博客分类: 问题 ApacheJavaTo ...
- hadoop 安装之 hadoop、hive环境配置
总结了一下hadoop的大致安装过程,按照master . slave的hadoop主从类别,以及root和hadoop集群用户两种角色,以职责图的方式展现,更加清晰一些
- Python操作MongoDB和Redis
1. python对mongo的常见CURD的操作 1.1 mongo简介 mongodb是一个nosql数据库,无结构化.和去中心化. 那为什么要用mongo来存呢? 1. 首先.数据关系复杂,没有 ...
- winfrom导出DataGridView为Excel方法
声明:此方法需要电脑安装Excel软件 需要类库:Microsoft.Office.Interop.Excel.dll 可百度自行下载 方法代码: /// <summary> /// 导出 ...