js反爬-从入门到精通webdriver
地址:http://openlaw.cn/login.jsp
需要登陆,Form data
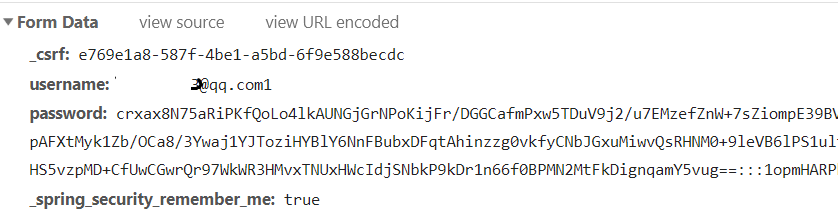
找到_csrf和password,_csrf,在登陆页面

找加密password的js代码,ctrl+F搜索password,重新填入input
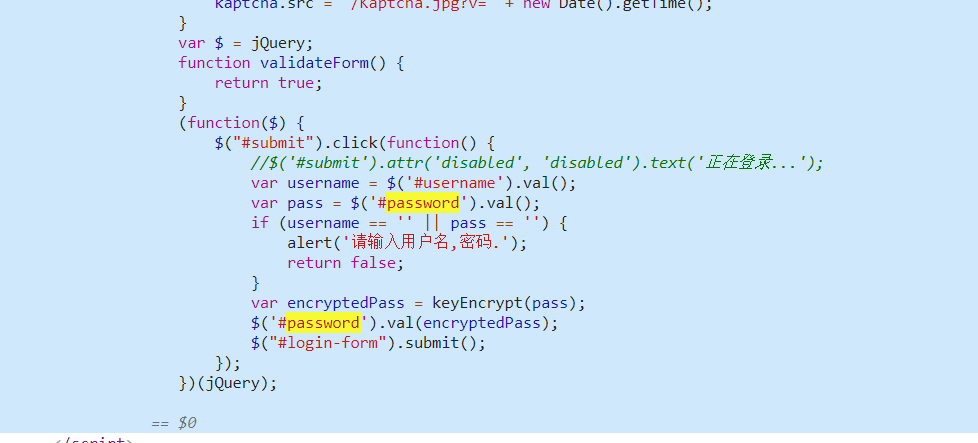
找到加密函数KeyEncrypt
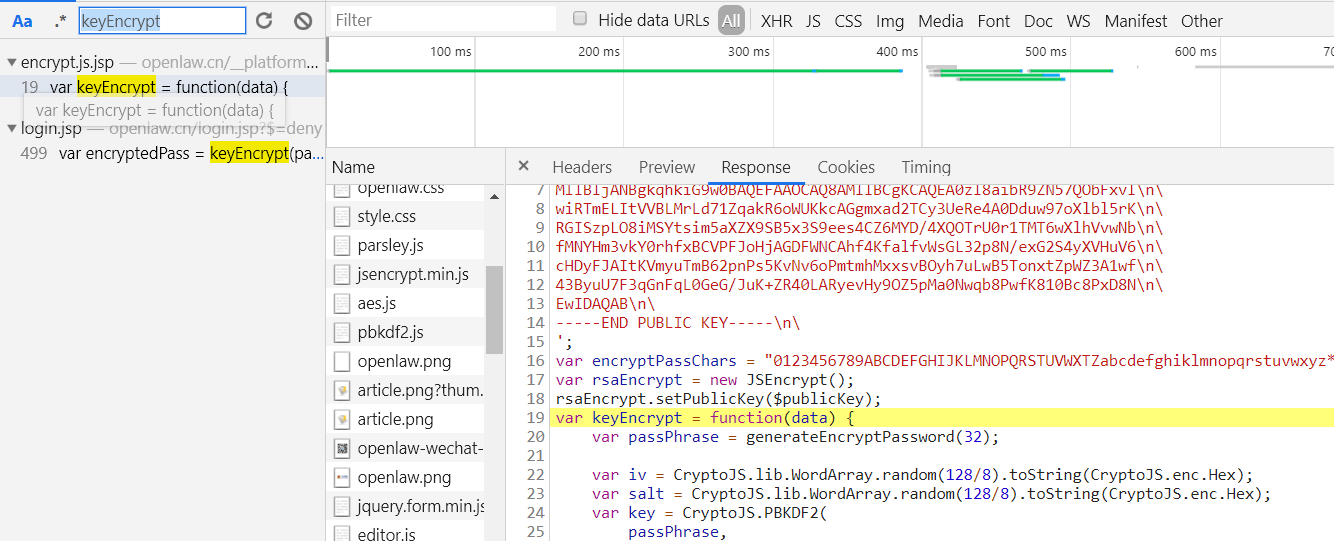
找到JSEncrypt,CryptoJs
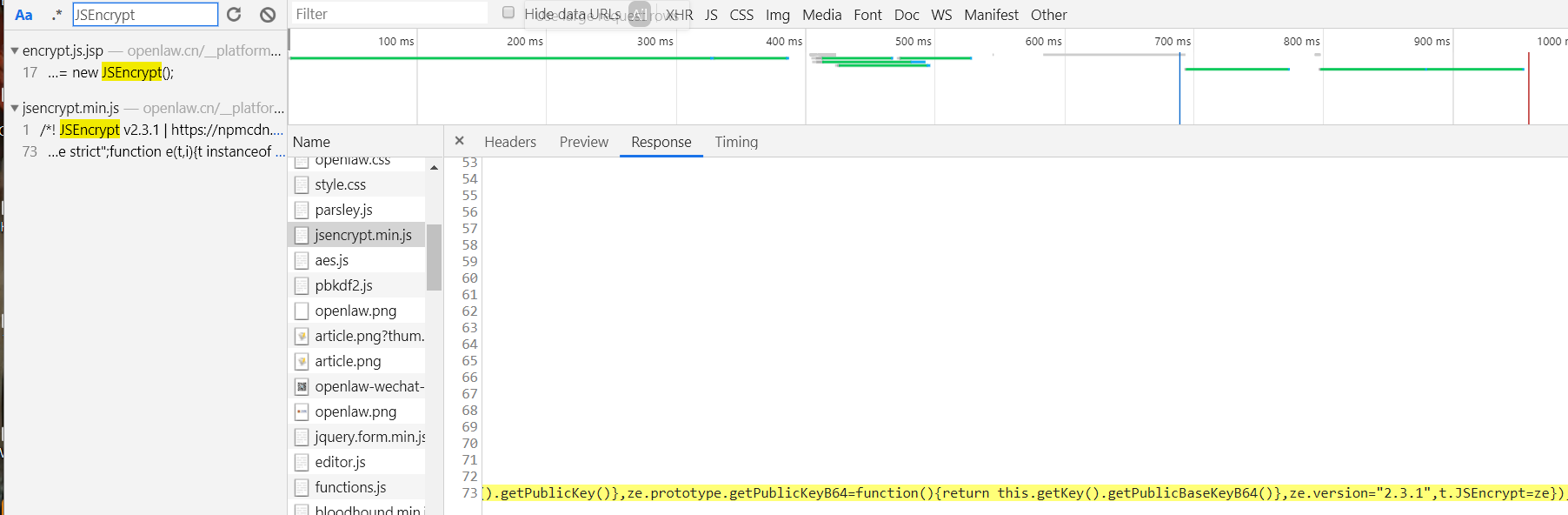
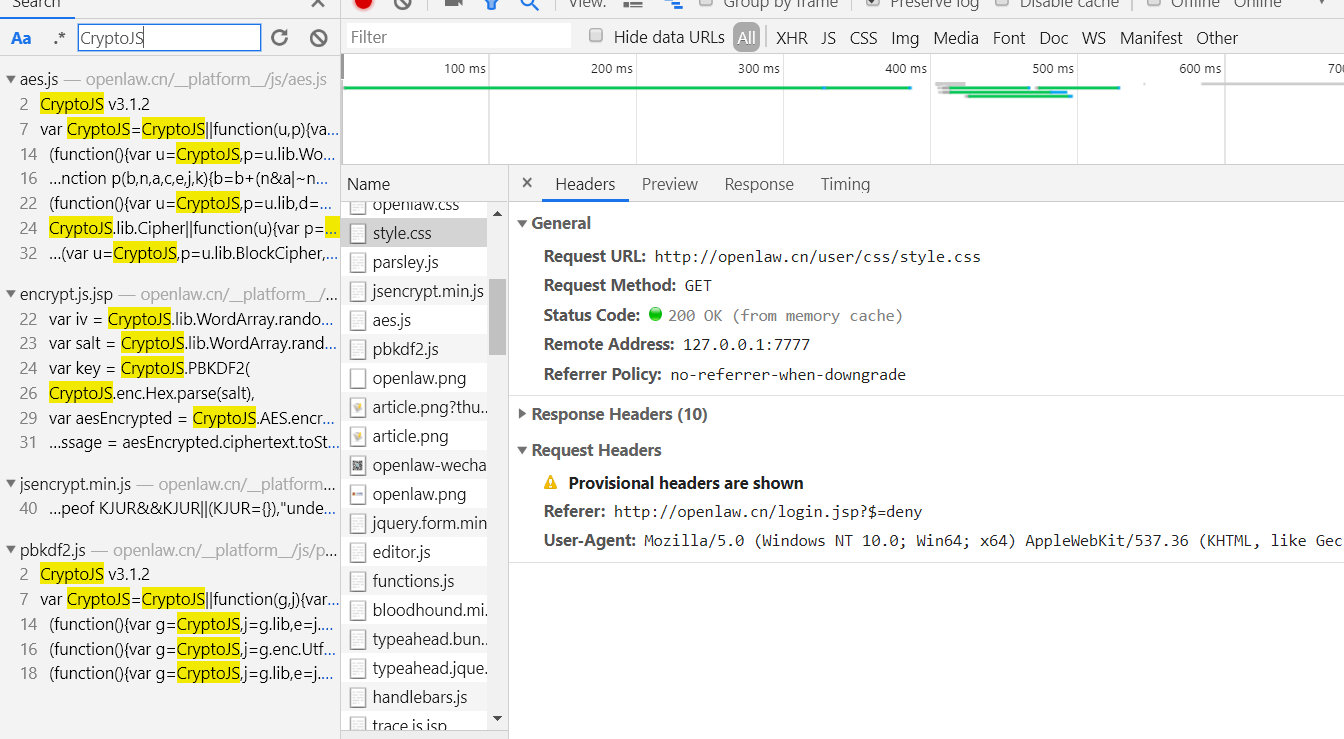
执行
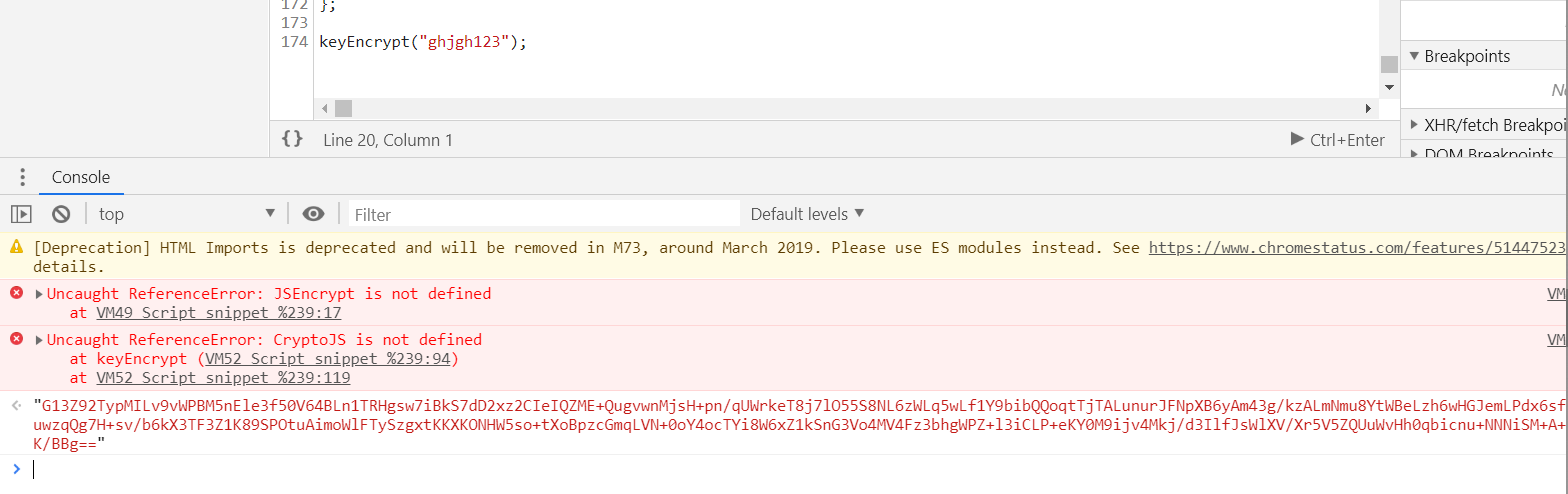
用execjs执行js或者用js2py
node.js或Jscript报navigator is not define,可以用PhantomJS
#运行时环境设置
import execjs
import execjs.runtime_names
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
PhantomJS = execjs.get(execjs.runtime_names.PhantomJS)
print(execjs.get().name)
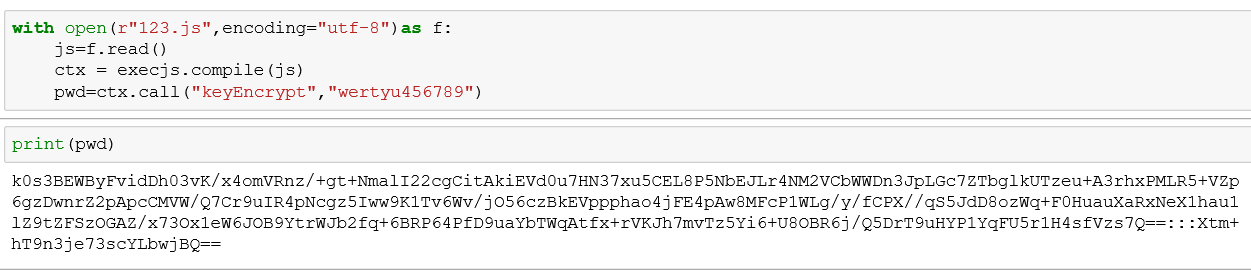
结果如图
pytohn执行
#获取csfr
headers={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding":"gzip,deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Content-Type":"application/x-www-form-urlencoded",
"Host":"openlaw.cn",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/73.0.3683.86Safari/537.36",
}
r=session.get("http://openlaw.cn/login.jsp?",headers=headers1)
tree=etree.HTML(r.text)
csrf=tree.xpath('//input[@name="_csrf"]/@value')[0] #post form data
post_url="http://openlaw.cn/login"
with open(r"C:\Users\37576\Desktop\123.js",encoding="utf-8")as f:
js=f.read()
ctx = execjs.compile(js)
pwd=ctx.call("keyEncrypt","XXXXXXXX")#密码
data={
"_csrf":csrf,
"username":"#########",#账户
"password":pwd,
"_spring_security_remember_me":"true",
}
res=session.post(post_url,data=data,headers=headers)
tree=etree.HTML(res.text)
lala=tree.xpath('//div[@class="bbp-user-section"]//text()')
登陆成功

页面
url="http://openlaw.cn/guidance/16444eba67afe97881fa6521d333ef10"
headers1={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding":"gzip,deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Host":"openlaw.cn",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/73.0.3683.86Safari/537.36",
}
a=session.get(url,headers=headers1)
是混淆的js

抓包
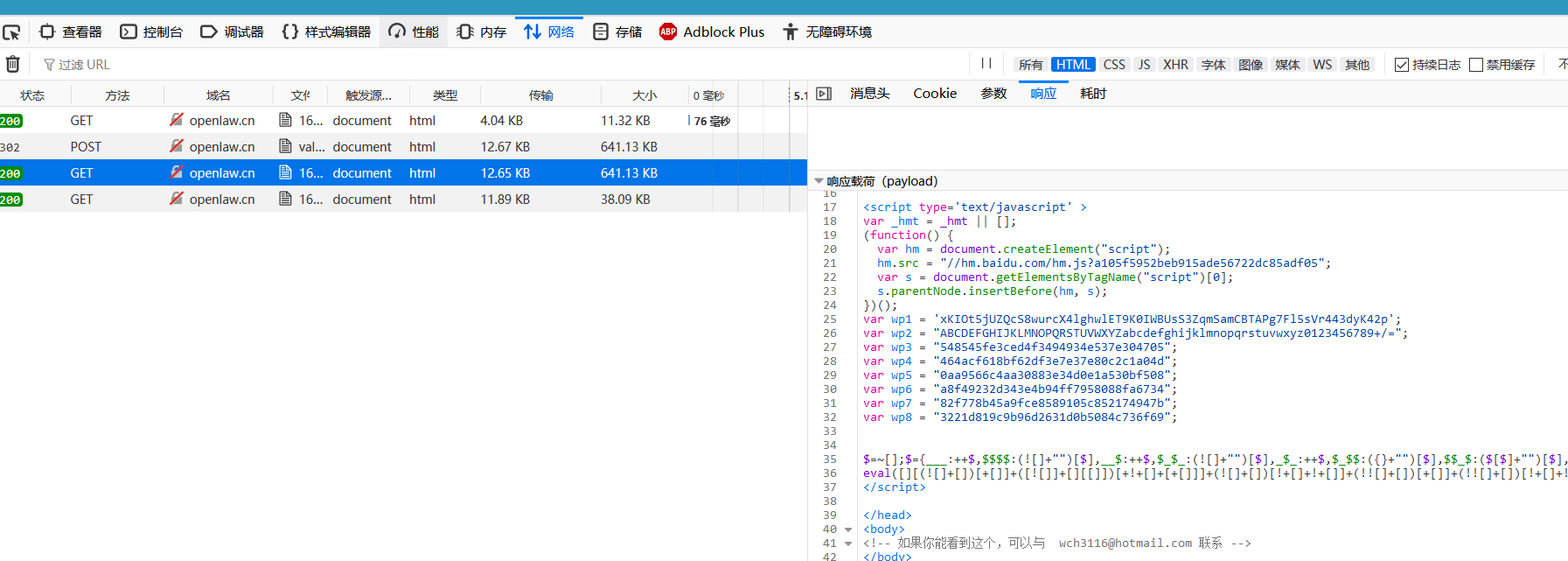
有二条请求
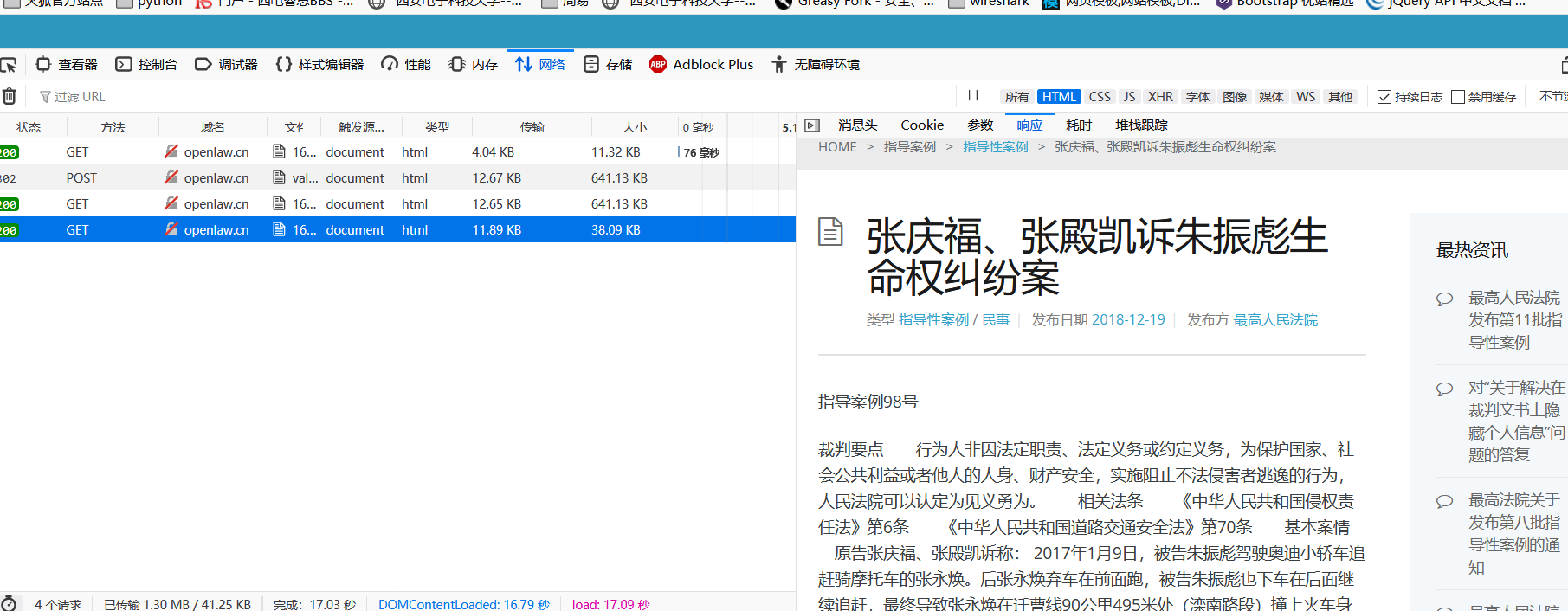
第一条加cookie,第二条正常,需要知道怎么加的cookie
jjencodeDemo:http://utf-8.jp/public/jjencode.html
],_$_:++$,$_$$:({}+"")[$],$$_$:($[$]+"")[$],_$$:++$,$$$_:(!""+"")[$],$__:++$,$_$:++$,$$__:({}+"")[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+"")[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+"")[$.__$])+((!$)+"")[$._$$]+($.__=$.$_[$.$$_])+($.$=(!""+"")[$.__$])+($._=(!""+"")[$._$_])+$.$_[$.$_$]+$.__+$._$+$.$;$.$$=$.$+(!""+"")[
jsfunk:http://www.jsfuck.com/
+[]+!+[]+!+[]]+(!![]+[])[+!+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+([![]]+[][[]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+!+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]
代码执行一下或者找工具解密
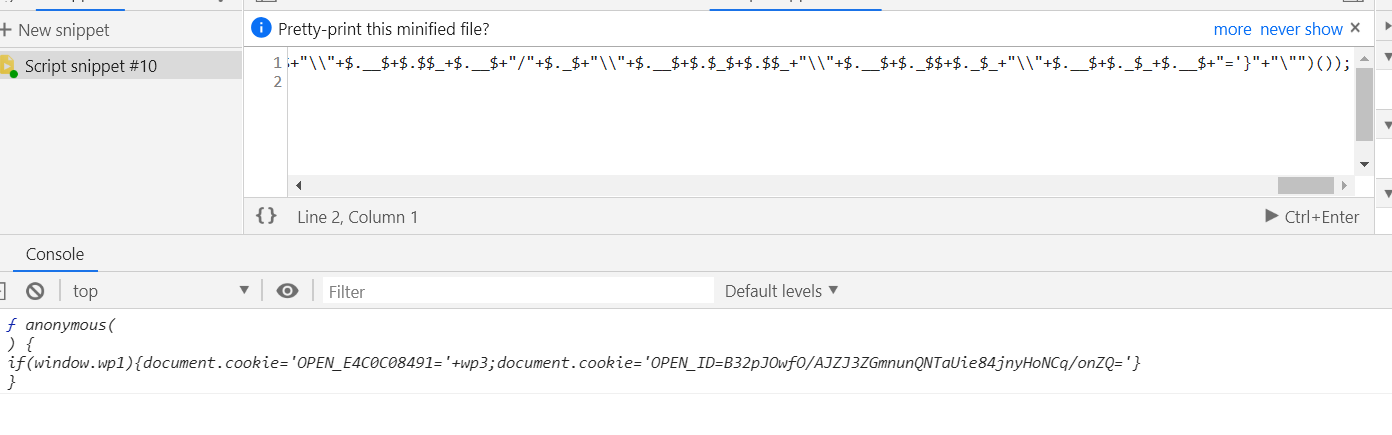
(function anonymous() {
if (window.wp1) {
document.cookie = 'OPEN_E4C0C08491=' + wp3;
document.cookie = 'OPEN_ID=B32pJOwfO/AJZJ3ZGmnunQNTaUie84jnyHoNCq/onZQ='
}
}
)
加cookie的部分
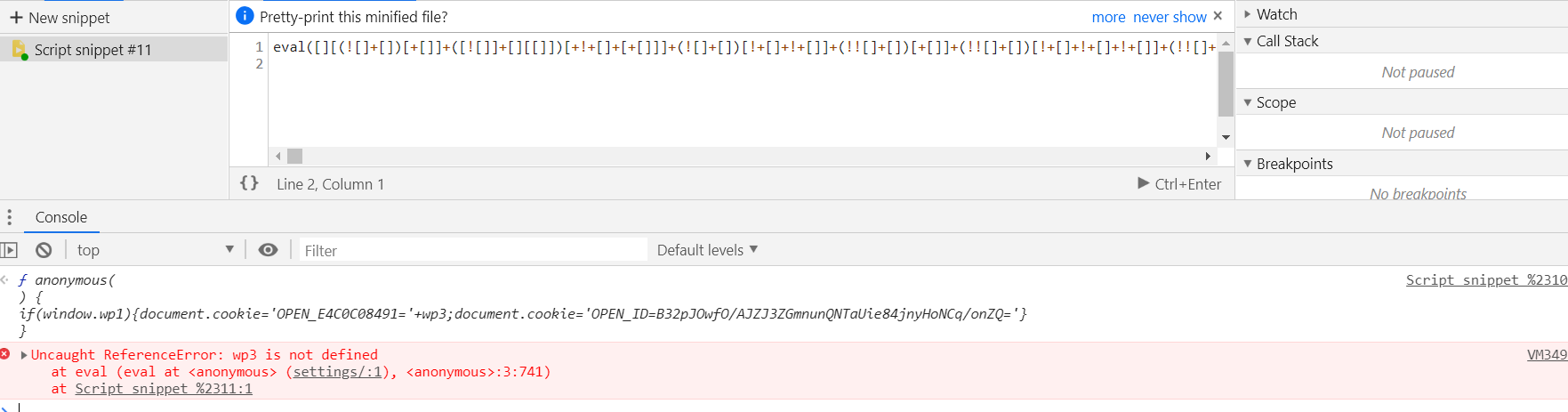
js:
var wp1 = 'xKIOt5jUZQcS8wurcX4lghwlET9K0IWBUsS3ZqmSamCBTAPg7Fl5sVr443dyK42p';
var wp2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
var wp3 = "548545fe3ced4f3494934e537e304705";
var wp4 = "464acf618bf62df3e7e37e80c2c1a04d";
var wp5 = "0aa9566c4aa30883e34d0e1a530bf508";
var wp6 = "a8f49232d343e4b94ff7958088fa6734";
var wp7 = "82f778b45a9fce8589105c852174947b";
var wp8 = "3221d819c9b96d2631d0b5084c736f69";
if (window.wp1) {
document.cookie = 'OPEN_E4C0C08491=' + wp3;
document.cookie = 'OPEN_ID=B32pJOwfO/AJZJ3ZGmnunQNTaUie84jnyHoNCq/onZQ='
} var getGlobal = function() {
if (typeof self !== '') {
return self
}
;if (typeof window !== '') {
return window
}
;if (typeof global !== '') {
return global
}
;throw new Error('unable to locate global object')
};
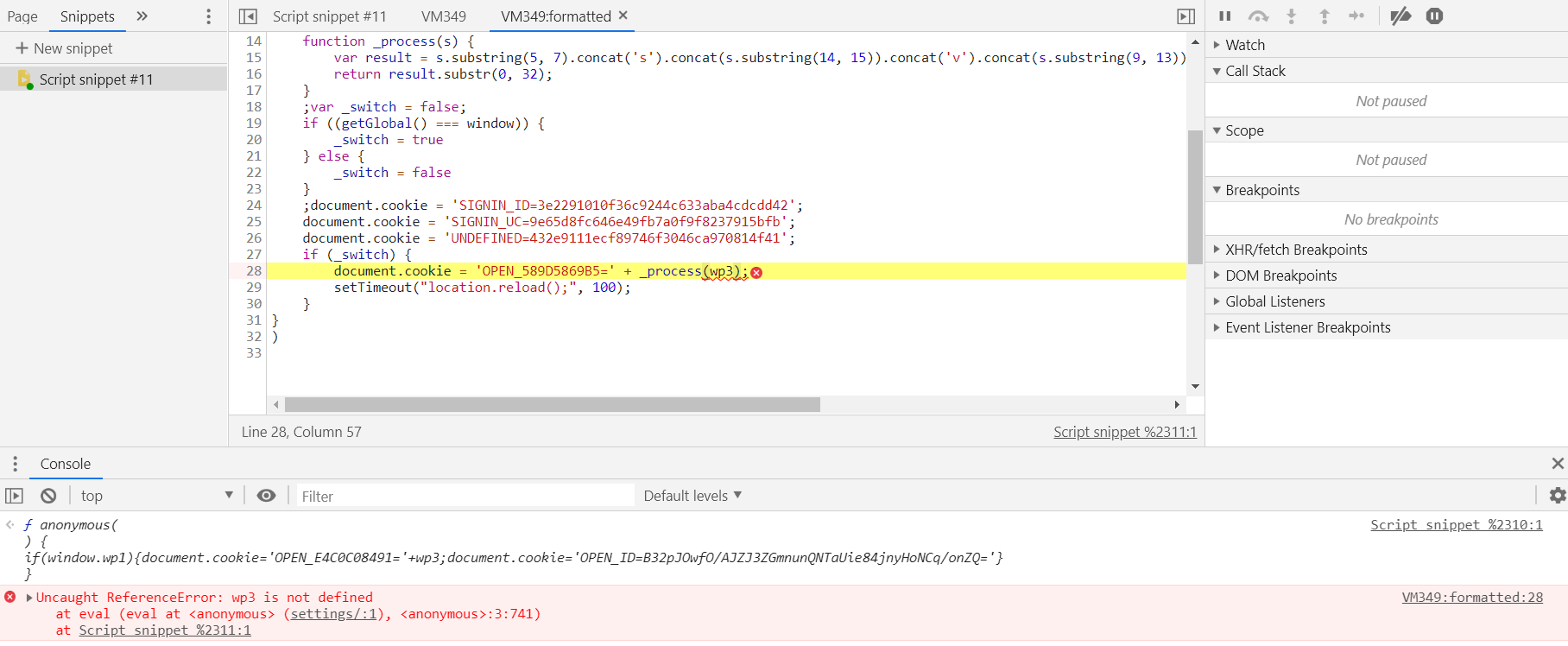
function _process(s) {
var result = s.substring(5, 7).concat('s').concat(s.substring(14, 15)).concat('v').concat(s.substring(9, 13)).concat('g').concat(s.substring(5)).concat('l').concat(s.substring(11, 19));
return result.substr(0, 32);
}
;var _switch = false;
if ((getGlobal() === window)) {
_switch = true
} else {
_switch = false
};
document.cookie = 'SIGNIN_ID=3e2291010f36c9244c633aba4cdcdd42';
document.cookie = 'SIGNIN_UC=9e65d8fc646e49fb7a0f9f8237915bfb';
document.cookie = 'UNDEFINED=432e9111ecf89746f3046ca970814f41';
if (_switch) {
document.cookie = 'OPEN_589D5869B5=' + _process(wp3);
setTimeout("location.reload();", 100);
}
。。。很多参数不知道哪里来的搞不定了,用selenium
#配置chorme
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options,executable_path = 'D:\python\chromedriver.exe')
from time import sleep
#登陆
driver.get("http://openlaw.cn/login.jsp?logout")
driver.find_element_by_id("username").send_keys("XXXXXXXXX")
driver.find_element_by_id("password").send_keys("XXXXXXXXX")
sleep(2)
driver.find_element_by_id("submit").click()
#页面数据
driver.get("http://openlaw.cn/guidance/167ce490ba94c3ed26baab5689fdd620")
sleep(2)
title=driver.find_element_by_xpath('//h1[@class="entry-title"]').text
guid=driver.find_element_by_xpath('//div[@class="annotator-wrapper"]/p').text
content=driver.find_element_by_xpath('//div[@class="annotator-wrapper"]/p[2]').text
page_detail={"title":title,"content":guid+"\n"+content.replace("\u3000"," ")}
结果

js反爬-从入门到精通webdriver的更多相关文章
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- js反爬学习(一)谷歌镜像
1. url:https://ac.scmor.com/ 2. target:如下链接 3. 过程分析: 3.1 打开chrome调试,进行元素分析.随便定位一个“现在访问” 3.2 链接不是直接挂在 ...
- JS反爬绕过思路之--谷歌学术镜像网链接抓取
首先,从问题出发: http://ac.scmor.com/ 在谷歌学术镜像网收集着多个谷歌镜像的链接.我们目标就是要把这些链接拿到手. F12查看源码可以发现,对应的a标签并不是我们想要的链接,而是 ...
- 爬虫入门到放弃系列07:js混淆、eval加密、字体加密三大反爬技术
前言 如果再说IP请求次数检测.验证码这种最常见的反爬虫技术,可能大家听得耳朵都出茧子了.当然,也有的同学写了了几天的爬虫,觉得爬虫太简单.没有啥挑战性.所以特地找了三个有一定难度的网站,希望可以有兴 ...
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- 26、ASP.NET MVC入门到精通——后台管理区域及分离、Js压缩、css、jquery扩展
本系列目录:ASP.NET MVC4入门到精通系列目录汇总 有好一段时间没更新博文了,最近在忙两件事:1.看书,学习中...2.为公司年会节目做准备,由于许久没有练习双截棍了,难免生疏,所以现在临时抱 ...
- Python爬虫入门教程 61-100 写个爬虫碰到反爬了,动手破坏它!
python3爬虫遇到了反爬 当你兴冲冲的打开一个网页,发现里面的资源好棒,能批量下载就好了,然后感谢写个爬虫down一下,结果,一顿操作之后,发现网站竟然有反爬措施,尴尬了. 接下来的几篇文章,我们 ...
- python爬虫破解带有RSA.js的RSA加密数据的反爬机制
前言 同上一篇的aes加密一样,也是偶然发现这个rsa加密的,目标网站我就不说了,保密. 当我发现这个网站是ajax加载时: 我已经习以为常,正在进行爬取时,发现返回为空,我开始用findler抓包, ...
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
随机推荐
- Machine Learning学习资源
引申:非原创,转载来自:https://blog.csdn.net/ptkin/article/details/50995140
- Numpy 基础运算1
# -*- encoding:utf-8 -*- # Copyright (c) 2015 Shiye Inc. # All rights reserved. # # Author: ldq < ...
- 关于VB里判断逻辑的说明
如上图,当进行连续判断的时候,即使第一个已经不符合条件了,后面的依然会计算.这点一定要记住,除非你所有的函数都有必要执行,否则会导致效率降低. 减代码不一定能提高效率,对于IIF和连续判断写法,貌似很 ...
- Base64简单原理
Base64要求把每三个8bit的字节转换为四个6bit的字节(即3*8 = 4*6 = 24) 1.例如我们有一个中文字符“中国(gb2312)”,转为十进制为:中-->54992,国--&g ...
- 漏测BUG借鉴
2. websocket: 用户频繁刷新,后台每次请求新的排队,内存溢出 1. websocket: 北京中心连接正常,外地中心,连接超时,应考虑到外地延迟问题
- android中Imageview的布局和使用
布局: <ImageView android:id="@+id/imt_photo" android:layout_width="fill_parent" ...
- C语言面试题分类->字符串处理
1.strlen:计算字符串长度(不包含'\0') 实现想法:遍历字符串,直到'\0'结束 #include<stdio.h> #include<stdlib.h> #incl ...
- Redis sortedset实现元素自动过期
这里的自动过期,Redis并没有提供相应的api,但是可以使用一下方法来实现. 需求背景: 给用户返回的文章要求七日内不能重复:文章是存放在java list里边:(这一块就是从db将文章拿出来,然后 ...
- FFmpeg 学习(五):FFmpeg 编解码 API 分析
在上一篇文章 FFmpeg学习(四):FFmpeg API 介绍与通用 API 分析 中,我们简单的讲解了一下FFmpeg 的API基本概念,并分析了一下通用API,本文我们将分析 FFmpeg 在编 ...
- 使用Nginx做图片服务器时候,配置之后图片访问一直是 404问题解决
我的错误配置是: 服务器文件根地址: 想通过浏览器输入这个地址访问到图片: 但是会发现文件找不到会一直404,原因是根路径配置错误,来看下root路径原理: root 配置的意思是,会在root配置的 ...