MYSQL 企业常用架构与调优经验分享
一、选择Percona Server、MariaDB还是MYSQL
mysql应用源码:http://www.jinhusns.com/Products/Download/?type=xcj
1、Mysql三种存储引擎
MySQL提供了两种存储引擎:MyISAM和 InnoDB,MySQL4和5使用默认的MyISAM存储引擎。从MYSQL5.5开始,MySQL已将默认存储引擎从MyISAM更改为InnoDB。
MyISAM没有提供事务支持,而InnoDB提供了事务支持。
XtraDB是InnoDB存储引擎的增强版本,被设计用来更好的使用更新计算机硬件系统的性能,同时还包含有一些在高性能环境下的新特性。
2、Percona Server分支
Percona Server由领先的MySQL咨询公司Percona发布。
Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB。是最接近官方MySQL Enterprise发行版的版本。
Percona提供了高性能XtraDB引擎,还提供PXC高可用解决方案,并且附带了percona-toolkit等DBA管理工具箱,
3、MariaDB
MariaDB由MySQL的创始人开发,MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
MariaDB提供了MySQL提供的标准存储引擎,即MyISAM和InnoDB,10.0.9版起使用XtraDB(名称代号为Aria)来代替MySQL的InnoDB。
4、如何选择
综合多年使用经验和性能对比,首选Percona分支,其次是MariaDB,如果你不想冒一点风险,那就选择MYSQL官方版本。
二、常用的MYSQL调优策略
1、硬件层相关优化
修改服务器BIOS设置
选择Performance Per Watt Optimized(DAPC)模式,发挥CPU最大性能。
Memory Frequency(内存频率)选择Maximum Performance(最佳性能)
内存设置菜单中,启用Node Interleaving,避免NUMA问题
2、磁盘I/O相关
使用SSD硬盘
如果是磁盘阵列存储,建议阵列卡同时配备CACHE及BBU模块,可明显提升IOPS。
raid级别尽量选择raid10,而不是raid5.
3、文件系统层优化
使用deadline/noop这两种I/O调度器,千万别用cfq
使用xfs文件系统,千万别用ext3;ext4勉强可用,但业务量很大的话,则一定要用xfs;
文件系统mount参数中增加:noatime, nodiratime, nobarrier几个选项(nobarrier是xfs文件系统特有的);
4、内核参数优化
修改vm.swappiness参数,降低swap使用率。RHEL7/centos7以上则慎重设置为0,可能发生OOM
调整vm.dirty_background_ratio、vm.dirty_ratio内核参数,以确保能持续将脏数据刷新到磁盘,避免瞬间I/O写。产生等待。
调整net.ipv4.tcp_tw_recycle、net.ipv4.tcp_tw_reuse都设置为1,减少TIME_WAIT,提高TCP效率。
5、Mysql参数优化建议
建议设置default-storage-engine=InnoDB,强烈建议不要再使用MyISAM引擎。
调整innodb_buffer_pool_size的大小,如果是单实例且绝大多数是InnoDB引擎表的话,可考虑设置为物理内存的50% -70%左右。
设置innodb_file_per_table = 1,使用独立表空间。
调整innodb_data_file_path = ibdata1:1G:autoextend,不要用默认的10M,在高并发场景下,性能会有很大提升。
设置innodb_log_file_size=256M,设置innodb_log_files_in_group=2,基本可以满足大多数应用场景。
调整max_connection(最大连接数)、max_connection_error(最大错误数)设置,根据业务量大小进行设置。
另外,open_files_limit、innodb_open_files、table_open_cache、table_definition_cache可以设置大约为max_connection的10倍左右大小。
key_buffer_size建议调小,32M左右即可,另外建议关闭query cache。
mp_table_size和max_heap_table_size设置不要过大,另外sort_buffer_size、join_buffer_size、read_buffer_size、read_rnd_buffer_size等设置也不要过大。
三、 MYSQL常见的应用架构分享
1、主从复制解决方案
这是MySQL自身提供的一种高可用解决方案,数据同步方法采用的是MySQL replication技术。MySQL replication就是从服务器到主服务器拉取二进制日志文件,然后再将日志文件解析成相应的SQL在从服务器上重新执行一遍主服务器的操作,通过这种方式保证数据的一致性。
为了达到更高的可用性,在实际的应用环境中,一般都是采用MySQL replication技术配合高可用集群软件keepalived来实现自动failover,这种方式可以实现95.000%的SLA。

2、MMM/MHA高可用解决方案
MMM提供了MySQL主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件。在MMM高可用方案中,典型的应用是双主多从架构,通过MySQL replication技术可以实现两个服务器互为主从,且在任何时候只有一个节点可以被写入,避免了多点写入的数据冲突。同时,当可写的主节点故障时,MMM套件可以立刻监控到,然后将服务自动切换到另一个主节点,继续提供服务,从而实现MySQL的高可用。
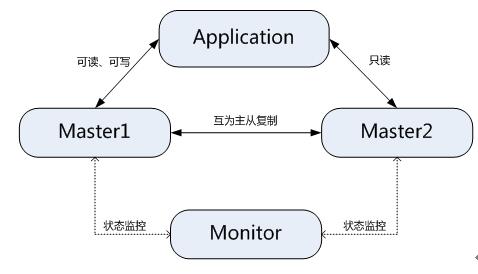
3、Heartbeat/SAN高可用解决方案
在这个方案中,处理failover的方式是高可用集群软件Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。在数据共享方面,通过SAN(Storage Area Network)存储来共享数据,这种方案可以实现99.990%的SLA。
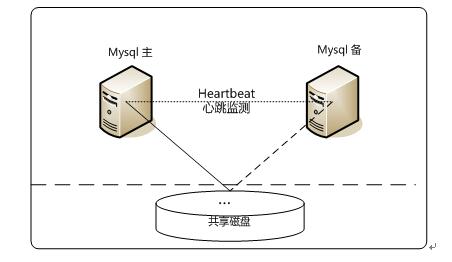
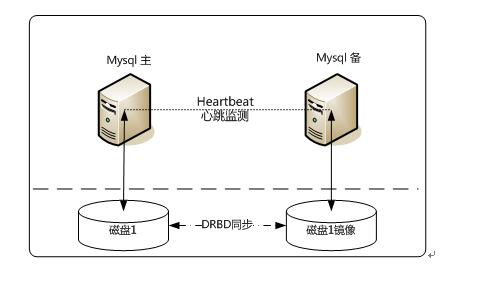
4、Heartbeat/DRBD高可用解决方案
此方案处理failover的方式上依旧采用Heartbeat,不同的是,在数据共享方面,采用了基于块级别的数据同步软件DRBD来实现。
DRBD是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。和SAN网络不同,它并不共享存储,而是通过服务器之间的网络复制数据。
四、MYSQL经典应用架构
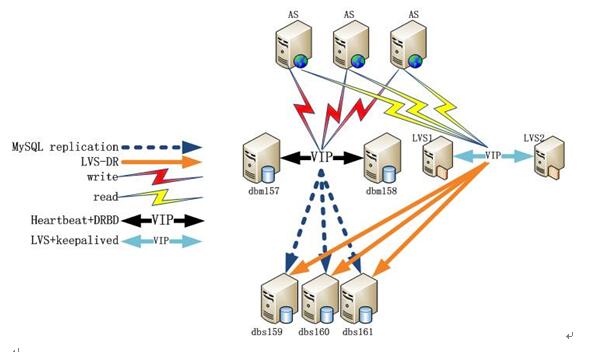
其中:
Dbm157是mysql主,dbm158是mysql主的备机,dbs159/160/161是mysql从。
MySQL写操作一般采用基于heartbeat+DRBD+MySQL搭建高可用集群的方案。通过heartbeat实现对mysql主进行状态监测,而DRBD实现dbm157数据同步到dbm158。
读操作普遍采用基于LVS+Keepalived搭建高可用高扩展集群的方案。前端AS应用通过提高的读VIP连接LVS,LVS有keepliaved做成高可用模式,实现互备。
最后,mysql主的从节点dbs159/160/161通过mysql主从复制功能同步mysql主的数据,通过lvs功能提供给前端AS应用进行读操作,并实现负载均衡。
本文转载自:http://ixdba.blog.51cto.com/2895551/1751377
MYSQL 企业常用架构与调优经验分享的更多相关文章
- MYSQL企业常用架构与调优经验分享
一.选择Percona Server.MariaDB还是MYSQL mysql应用源码:http://www.jinhusns.com/Products/Download/?type=xcj 1.M ...
- jvm调优经验分享
当Java程序申请内存,超出VM可分配内纯的时候,VM首先可能会GC,假设GC完还是不够,或者申请的直接超够VM可能有的,就会抛出内 存溢出异常.从VM规范中我们能够得到,一下几种异常. java.l ...
- 【叶问】 MySQL常用的sql调优手段或工具有哪些
MySQL常用的sql调优手段或工具有哪些1.根据执行计划优化 通常使用desc或explain,另外可以添加format=json来输出更详细的json格式的执行计划,主要注意点如下: ...
- MySQL企业常用集群图解
mysql集群架构图片 1.mysql企业常用集群架构 在中小型互联网的企业中.mysql的集群一般就是上图的架构.WEB节点读取数据库的时候读取dbproxy服务器.dbproxy服务器通过对S ...
- MGR架构~ 整体性能架构的调优
一 简介:MGR集群架构的调优二 过程:本文将从各个角度来具体阐述下三 硬件 1 硬件选择相同配置的服务器,磁盘,内存,cpu性能越高越好四 网络 1 0丢包和最好万兆网卡五 MGR本身 ...
- JVM性能调优经验总结
本文转载自JVM性能调优经验总结 说明 调优是一个循序渐进的过程,必然需要经历多次迭代,最终才能换取一个较好的折中方案. 在JVM调优这个领域,没有任何一种调优方案是适用于所有应用场景的,同时,切勿极 ...
- 性能调优案例分享:Mysql的cpu过高
性能调优案例分享:Mysql的cpu过高 问题:一个系统,Mysql数据库,数据量变大之后.mysql的cpu占用率很高,一个测试端访问服务器时mysql的cpu占用率为15% ,6个测试端连服务 ...
- GC浅析之三-性能调优经验总结
性能调优经验总结 问题的出现: 在日常环境下,以某server 为例,该机器的每秒的访问量均值在368左右,最大访问量在913.对外提供服务的表现为每两三个小时就有秒级别的时间客户端请求超时,在访问量 ...
- MySQL慢查询查找和调优测试
MySQL慢查询查找和调优测试,接下来详细介绍,需要了解的朋友可以参考下.本文参考自:http://www.jbxue.com/db/4376.html 编辑 my.cnf或者my.ini文件,去除 ...
随机推荐
- DBA思考系列——凛冬将至,丧钟为谁而鸣!
诸多迹象昭示着凛冬将至,大萧条终于正式在全国各地拉开了序幕,很多80后的国人没有经历过苦日子,也没有经历过真正的金融危机.这场经济危机必将摧毁一些无视经济能力,盲目购房,盲目消费的家庭或个人.个人对经 ...
- php操作Memcache的一个类库
###php操作Memcache的一个类库 代码如下: <?php /** * Created by PhpStorm. * User: alisleepy * Date: 2019-03-14 ...
- Html 解决数字和字母不换行
在html页面中,如果是数字或者字母显示的话,默认是不换行的.一般显示成这种: 解决方法确实也很简单,设置td或者div为: style="word-break:break-all;&quo ...
- 浏览器和服务器实现跨域(CORS)判定的原理
前端对Cross-Origin Resource Sharing 问题(CORS,中文又称'跨域')应该很熟悉了.众所周知出于安全的考虑,浏览器有个同源策略,对于不同源的站点之间的相互请求会做限制(跨 ...
- laravel学习笔记二
代码编写提示工具
- python之面相对象程序设计
一 面向对象的程序设计的由来 面向对象设计的由来见概述:http://www.cnblogs.com/linhaifeng/articles/6428835.html 面向对象的程序设计:路飞学院版 ...
- Linux 实例常用内核网络参数介绍与常见问题处理
本文总结了常见的 Linux 内核参数及相关问题.修改内核参数前,您需要: 从实际需要出发,最好有相关数据的支撑,不建议随意调整内核参数. 了解参数的具体作用,且注意同类型或版本环境的内核参数可能有所 ...
- SQLi “百度杯”CTF比赛 九月场
试一下1=1 发下username为空,说明哪里出问题了,是没有注入吗?还是被过滤了?试一下#号的url编码%23 编码后,返回的结果是对的,证明是的,有注入 1=2就返回空了 看了wp,就觉得自己的 ...
- 理解koa-router 路由一般使用
阅读目录 一:理解koa-router一般的路由 二:理解koa-router命名路由 三:理解koa-router多个中间件使用 四:理解koa-router嵌套路由 五:分割路由文件 回到顶部 一 ...
- MongoDB install
下载地址1:https://www.mongodb.org/dl/linux下载地址2:https://www.mongodb.com/download-center/community关于Mongo ...