带着新人看java虚拟机05(多线程篇)
上一篇我们主要是把一些基本概念给说了一下以及怎么简单的使用线程池,我们这一节就来看看线程池的实现;
1.线程池基本参数
以Executors.newFixedThreadPool()这种创建方式为例:
大家想象,假如你创建一个线程池,你想这个池子有些什么参数呢?首先这个池子必须要有一个最大值;然后还希望这个池子的线程数量有一个警戒线,到了这个警戒线的位置说明线程池暂时已经满了,如果这个时候还有人过来拿线程,我们就要把这些人抓起来扔到一个地方去让他们排队,告诉他们:请稍等,等我们的线程有空闲的时候再来处理你的事;再然后假如人排队的地方都满了,玛德,好多人,于是线程池就想办法东拼西凑又多搞出来了几个线程去处理了;最后,假如那搞出来的这几个线程还是不够用,并且排队的地方总是满的,于是线程池生气了,就这么多人可以了,如果还有人过来的赶紧让它滚蛋;
这里我们需要知道几个东西:
1这里的警戒线叫做核心线程池大小(corePoolSize);
2.最大值还是叫做线程池线程最大数量(maximumPoolSize)
3.排队的地方叫做队列(BlockingQueue<Runnable> ),这个队列用于保存我们的线程要做的任务,这个队列有好几种类型,我们后面会分析的;
4.还有一个参数是keepAliveTime:线程存活时间,意思就是当池中总共的线程大于核心线程池数目,那就关闭池子中的空闲线程,要保证线程总数维持在核心线程池数目或者之下;

现在我们来理一下逻辑:
池中当前线程数量 <= 核心线程池大小:线程池直接创建线程处理
池中当前线程数量 > 核心线程池数量:将多余的任务放进队列
队列满了,还有任务过来,线程池继续创建线程,直到到达线程池最大数量
还有任务过来,这里会有一个饱和策略,默认是直接丢弃继续过来的任务
2.线程池种类
我们上一节使用的线程池如下所示:
ExecutorService pool = Executors.newFixedThreadPool(3);
pool.execute(new RunnableImpl("玩游戏"));
我们是通过Executors这个类的静态方法创建的一个线程池,于是进入这个类我们看看这个类还有没有创建其他种类线程池的方法,居然还真有。。。
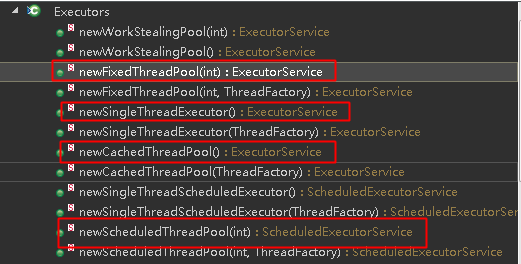
我们先简单说说这四种分别是干嘛用的;
newFixedThreadPool(int):这个线程池就是上面说的那种方式,也是我们重点要看源码的线程池;
newSingThreadExecutor():这个不能说是线程池了,因为里面这里面只有一个线程,而且自带一个队列,只要有任务来了就会把任务保存到队列中,然后这个线程就慢慢的一个一个执行。
newCachedThreadPool():无限线程的线程池
newScheduledThreadPool(int):一个定时的线程池,可以让线程池中的线程延迟指定时间再执行任务;
3.Executors继承结构
我们可以看到实际上实例化的是一个ThreadPoolExecutor对象,这个对象作用是用线程去处理传进去的任务:


我们看一下这个继承结构,
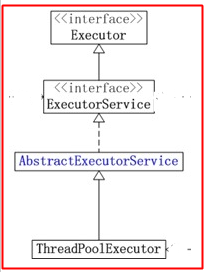
Executor接口:只是定义了execute();这个方法,等待子类去实现;
ExecutorService接口:继承Execute接口,并又声明了shutdown()方法和submit()方法,等待子类去实现
AbstractExecutorService抽象类:初步实现了submit()方法,但是内部调用的execute()方法去执行任务
ThreadPoolExecutor类:这个类是实现了很多的方法,将shutdown()和execute()方法都给实现了;
4.看看execute()方法源码
下面我们主要就是看看execute()方法的内部是怎么实现的,知道了这个的实现原理也就差不多了
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//workCountOf(c)表示当前线程池中线程的数量;这里进行一个判断,当线程池中线程数目小于核心池子数目时,
就调用addWorker()方法将我们的任务添加进去,等下可以看到addWorker()方法内部其实就是创建线程并处理请求,
就类似new Thread(xxx).start()这种方式
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果当前线程数目大于核心线程并且任务放入一个队列成功,内部还会再次进行线程池状态判断,这里的&&用得比较精髓(短路作用),好好体会一下,
假如不是运行状态那就会执行remove方法 删除队列中的任务,如果是运行状态直接进入else if,这里的目的是线程池中已经关闭了,我们添加一个null任务
表示线程池不再处理任务
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//能执行到这里,说明上面两个if中的条件都不满足,条件应该是:当前线程大于核心线程,并且向队列中添加任务失败,换句说说就是对列已经满了,装不下这么多任务
于是我们reject()方法内部就是对这些多余的任务进行处理的一些策略,默认就是直接丢弃
else if (!addWorker(command, false))
reject(command);
}
对于面这三种情况的判断还是很清楚的,我们忽略很多细节,因为我们的目的是要对整个逻辑有个大概的了解,而不是去完全消化这些源码,这很不现实,要想理解透彻只能慢慢的去研究...
我们来看看最重要的addWorker()这个方法,这个方法就是线程池将我们传进来的new Runnable(xxx)进行处理,其实内部就是用new Thread(xxxx).start()处理,只是出于线程池中会进行很多的条件判断以及将Runnable()做进一步的封装,我们了解就好,代码如下:
private boolean addWorker(Runnable firstTask, boolean core) {
//这里删除很多的条件判断的代码
..........
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock;
//注意下面这两行,其实就是将我们传进来的Runnable()进行封装成Worker,在Worker构造器里面会new Thread()并且保存起来
这样做的一个好处就是直接将一个线程和一个Runnable进行绑定,我们随时可以从Worker中获取线程然后调用start()方法就ok了
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
mainLock.lock();
try {
//此处删除一些
.........
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//由于会有很多个Worker,于是我们会创建HashSet<Worker> workers = new HashSet<Worker>(),用于保存所有的worker,后续直接遍历处理很方便
而且我们所说的线程池的本质就是这个workers,也就是一个HashSet
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//下面这个if语句中就是一个无限循环的去执行线程的start()方法
if (workerAdded) {
t.start();
workerStarted = true;
}
}
}return workerStarted;
}
说出来你可能不信,我有点没看懂这里,因为最后的那个start()方法总感觉有点问题,但是说不上来,你们觉得这个start()方法之后,CPU来运行这个线程会执行哪个run()方法?是我们传进去的类的run()方法?还是worker的run()方法呢?
我们看看下面这两行代码,Worker构造器中的新建线程的代码就不截图了,我们把下面这几行代码变化一下:
Worker w = new Worker(firstTask);
final Thread t = w.thread;
........
t.start()
变化后:
Worker w = new Worker(firstTask);//firstTask是我们传进去的实现了Runnable接口的类,但是Worker也实现了Runnable接口
final Thread t = getThreadFactory().newThread(w);
t.start()
看到没有,其实调用的是Worker的run()方法,然后在Worker的run()方法的内部又会进行很多处理,最后再去调用我们传进去的那个run()方法。 5.总结
其实个人感觉深入到这里就差不多了,基本上就理解了线程池的流程,当然有兴趣的小伙伴可以继续深入看看Worker中的run()方法是怎么执行的,其实比较容易,
主要是由很多对线程池很多状态啊,线程数量等判断可能会干扰我们的理解,如果后续有需要我们再慢慢深入,哈哈哈!
这一篇其实没说多少内容,就是让大家对线程池到底是个什么鬼有个最粗略的认识,其实本质就是一个HashSet<Worker>,然后把我们创建的Runnable()实例先给封装成
Worker对象,其中Worker也是实现了Runnable接口,有点类似装饰者模式,哈哈!再之后就是将WOrker存到那个集合中,并且就调用start()方法调用worker
的run()方法,然后最后可能就是调用我们传进去的那个run()方法了
带着新人看java虚拟机05(多线程篇)的更多相关文章
- 带着新人看java虚拟机06(多线程篇)
其实多线程还有很多的东西要说,我们慢慢来,可能会有一些东西没说到,那就没办法了,只能说尽量吧! 1.synchronized关键字 说到多线程肯定离不开这个关键字,为什么呢?因为多线程之间虽然有各自的 ...
- 带着新人看java虚拟机04(多线程篇)
我记得最开始接触多进程,多线程这一块的时候我不是怎么理解,为什么要有多线程啊?多线程到底是个什么鬼啊?我一个程序好好的就可以运行为什么要用到多线程啊?反正我是十分费解,即使过了很长时间我还是不是很懂, ...
- 带着新人看java虚拟机03
分享一篇博客:https://blog.csdn.net/yfqnihao/article/details/8289363,本篇有部分参考这篇博客!!! 还是继续说一下java虚拟机,为什么呢?因为我 ...
- 带着新人看java虚拟机02
上一节是把大概的流程给过了一遍,但是还有很多地方没有说到,后续的慢慢会涉及到,敬请期待! 这次我们说说垃圾收集器,又名gc,顾名思义,就是收集垃圾的容器,那什么是垃圾呢?在我们这里指的就是堆中那些没人 ...
- 带着新人看java虚拟机01
1.前言(基于JDK1.7) 最近想把一些java基础的东西整理一下,但是又不知道从哪里开始!想了好久,还是从最基本的jvm开始吧!这一节就简单过一遍基础知识,后面慢慢深入... 水平有限,我自己也是 ...
- 带着新人看java虚拟机07(多线程篇)
这一篇说一下比较枯燥的东西,为什么说枯燥呢,因为我写这都感觉很无聊,无非就是几个阻塞线程的方法和唤醒线程的方法... 1.线程中断 首先我们说一说怎么使得一个正在运行中的线程进入阻塞状态,这也叫做线程 ...
- Java虚拟机05.1(各种环境下jvm的参数如何调整?)
cmd下 eclipse下 tomcat下 cmd下指定jvm参数 在cmd下执行Java程序可以通过如下方式之地需要配置的Java 虚拟机参数: 这里只是指定了对初始为2M,新生代为1M,堆最大值为 ...
- Java基础之多线程篇(线程创建与终止、互斥、通信、本地变量)
线程创建与终止 线程创建 Thread类与Runnable接口的关系 public interface Runnable { public abstract void run(); } public ...
- 深入理解java虚拟机系列初篇(一):为什么要学习JVM?
前言 本来想着关于写JVM这个专栏,直接写知识点干货的,但是想着还是有必要开篇讲一下为什么要学习JVM,这样的话让一些学习者心里有点底的感觉比较好... 原因一:面试 不得不说,随着互联网门槛越来越高 ...
随机推荐
- mysql 给表添加唯一约束、联合唯一约束,指定唯一约束的名字
表结构 FIELD TYPE COLLATION NULL KEY DEFAULT Extra PRIVILEGES ...
- 谈谈书本《c#物联网程序设计基础》中的技术瑕疵,如果你将要读本书,请进来看看!
今天去书店看到一本名为<c#物联网程序设计基础>的书,对物联网感兴趣的我抓起来就看,书中的项目都是上位机开发项目,较简单,如果物联网开发只是这样,看起来我做物联网开发也是绰绰有余.这边书我 ...
- 第七章 mysql 事务索引以及触发器,视图等等,很重要又难一点点的部分
[索引] 帮助快速查询 MyISAM ,InnoDB支持btree索引 Memory 支持 btree和hash索引 存储引擎支持 每个表至少16个索引 总索引长度至少256字节 创建索引的优 ...
- 最好的营销是“调情”
每一个精彩的营销案例都应该像一个精彩的故事,而故事最精彩的讲述方式就是设置一个开放的结局,把解读和诠释的权利留给读者和观众.宣讲.洗脑式的营销时代已经终结,就像单相思的深情表白永远不如两情相悦的彼此挑 ...
- Collection、List、Set集合概括
1.Collection是一个接口,定义了集合相关的操作方法,其有两个子接口List和Set. 2.List和Set的区别 List是有序的可重复集合,Set是无序的不可重复集合. 3.集合持有 ...
- Java并发之乐观锁悲观锁
定义 乐观锁和悲观锁这两种锁机制,是在多用户环境并发控制的两种所机制. 悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作.[1]常见实现如独占锁.乐观锁:假设不会发生并发冲突,只在提交操作 ...
- PAT1122: Hamiltonian Cycle
1122. Hamiltonian Cycle (25) 时间限制 300 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The ...
- redis两种持久化方法对比分析
1.前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能, ...
- Java 领域从传统行业向互联网转型你必须知道的事儿
我为什么要写这篇文章 武林中,"天下武功出少林"指各门各派的武功都与少林武学有一定的渊源,技术也是相同的道理,对于Java领域的应用而言,传统行业与互联网行业的技术都来自J2SE和 ...
- Python模块操作
Exceptions 模块 该模块定义了以下标准异常: • Exception 是所有异常的基类. 强烈建议(但不是必须)自定义的异常异常也继承这个类. • SystemExit(Exception) ...