spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现
分布式读写分离和分库分表采用sharding-jdbc实现。
sharding-jdbc是当当网推出的一款读写分离实现插件,其他的还有mycat,或者纯粹的Aop代码控制实现。
接下面用spring boot 2.1.4 release 版本实现读写分离。
1. 引入jar包
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>
<!-- sharding-jdbc -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>1.5.4</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency> 2. 添加配置文件
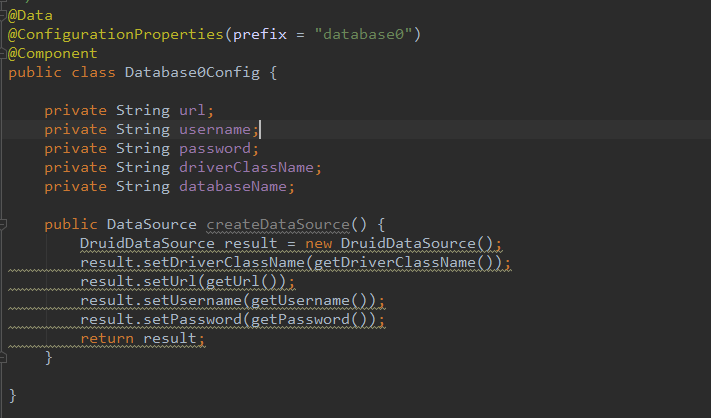
分别添加三份,配置为database0,database1,database2。
3. 添加DataSourceConfig
package com.fintecher.cn.elasticjobdemo.config; import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
import com.fintecher.cn.elasticjobdemo.service.DatabaseShardingAlgorithm;
import com.fintecher.cn.elasticjobdemo.service.TableShardingAlgorithm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration; import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfig { @Autowired
private Database1Config database1Config; @Autowired
private Database2Config database2Config; @Autowired
private DatabaseShardingAlgorithm databaseShardingAlgorithm; @Autowired
private TableShardingAlgorithm tableShardingAlgorithm; @Bean
public DataSource getDataSource() throws SQLException {
return buildDataSource();
} private DataSource buildDataSource() throws SQLException {
//设置从库数据源集合
Map<String, DataSource> slaveDataSourceMap = new HashMap<>();
slaveDataSourceMap.put(database1Config.getDatabaseName(), database1Config.createDataSource());
slaveDataSourceMap.put(database2Config.getDatabaseName(), database2Config.createDataSource()); //设置默认数据库
DataSourceRule dataSourceRule = new DataSourceRule(slaveDataSourceMap, database1Config.getDatabaseName()); //分表设置
TableRule orderTableRules = TableRule.builder("user").actualTables(Arrays.asList("user_0", "user_1")).dataSourceRule(dataSourceRule).build(); //分库分表策略
ShardingRule shardingRule = ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRules))
.databaseShardingStrategy(new DatabaseShardingStrategy("id", databaseShardingAlgorithm))
.tableShardingStrategy(new TableShardingStrategy("name", tableShardingAlgorithm))
.build(); //获取数据源对象
// DataSource dataSource = MasterSlaveDataSourceFactory.createDataSource("masterSlave", database0Config.getDatabaseName()
// , database0Config.createDataSource(), slaveDataSourceMap, MasterSlaveLoadBalanceStrategyType.getDefaultStrategyType()); DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule); return dataSource;
} @Bean
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
} }
4. 分库实现方案
@Component
public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Long> { @Autowired
private Database2Config database2Config; @Autowired
private Database1Config database1Config; @Override
public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Long value = shardingValue.getValue();
if (value <= 20L)
return database1Config.getDatabaseName();
else
return database2Config.getDatabaseName();
} @Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
return null;
} @Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
return null;
} } 5. 分表实现方案
@Component
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<String> { @Override
public String doEqualSharding(Collection<String> tableNames, ShardingValue<String> shardingValue) {
for (String each : tableNames) {
if (each.endsWith("0") && shardingValue.getValue().contains("军")) {
return "user_0";
} else
return "user_1";
}
return null;
} @Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<String> shardingValue) {
return null;
} @Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<String> shardingValue) {
return null;
} }
5. 环境参数配置
#jpa 配置
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=none
##数据库database0配置
database0.url=jdbc:mysql://192.168.3.32:3306/database0?characterEncoding=utf8&useSSL=false
database0.username=root
database0.password=123456
database0.driverClassName=com.mysql.jdbc.Driver
database0.databaseName=database0
##数据库database1地址
database1.url=jdbc:mysql://192.168.3.32:3306/database1?characterEncoding=utf8&useSSL=false
database1.username=root
database1.password=123456
database1.driverClassName=com.mysql.jdbc.Driver
database1.databaseName=database1
##数据库database2地址
database2.url=jdbc:mysql://192.168.3.32:3306/database2?characterEncoding=utf8&useSSL=false
database2.username=root
database2.password=123456
database2.driverClassName=com.mysql.jdbc.Driver
database2.databaseName=database2
6. 测试
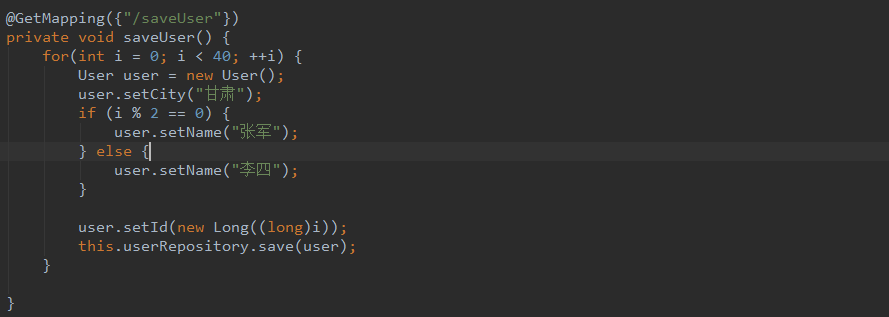
7. 达到的效果
插入40条数据,20条在base1,20条在base2,base1中张军的数据在user_0,李四的数据在user_1
8. 问题总结:
在写代码的过程中自己引包的时候很随便,引入了一些其他的包,如下:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.0.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.11.18.RELEASE</version>
</dependency>
导致在起服务的时候报 :
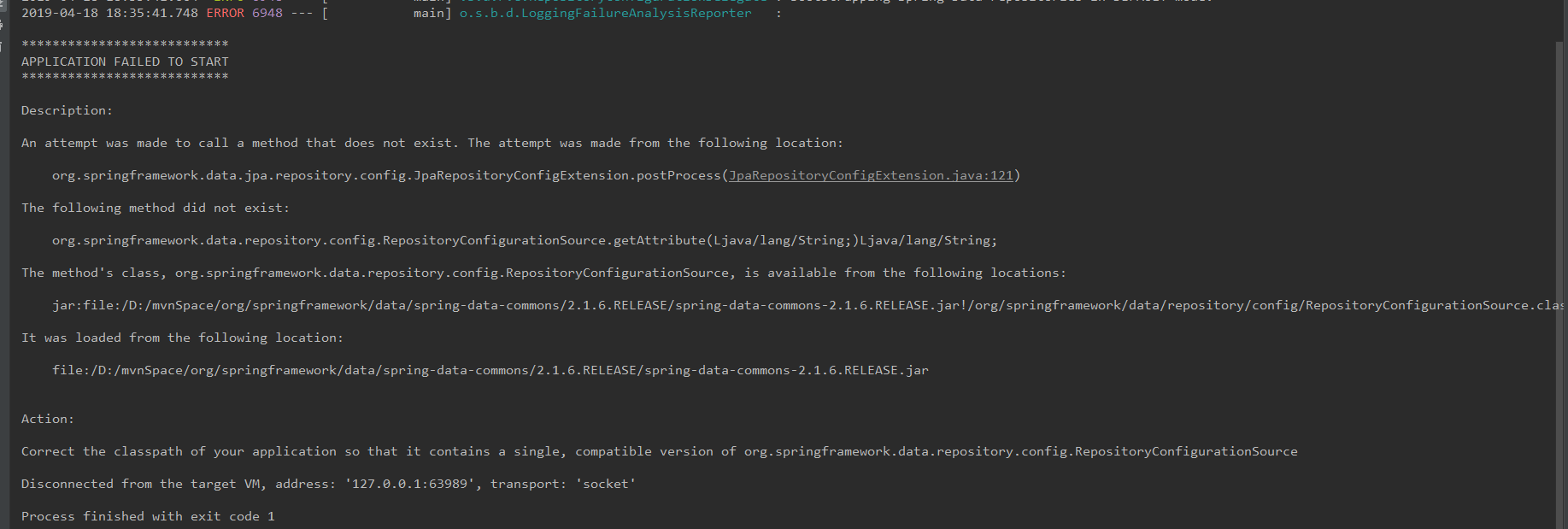
解决方案:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
将上面三个包换成这两个即可。
9. 总结
在使用sharding-jdbc过程中实现了
SingleKeyDatabaseShardingAlgorithm 这个接口,这个接口有三个方法 equal,in ,between ,这三个方法的作用是在比较传送过来的值的时候分别用这三种方案进行比较。 10. 遗留问题,当把数据库分库分表存后,查询怎么获取到所有的数据呢。 11. 参考文档:https://yq.aliyun.com/articles/690021https://www.dalaoyang.cn/article/95?spm=a2c4e.11153940.blogcont690021.12.2057195fd9jYc312. 获取数据解决方案:
1. 广发复制法, 比如主表 Personal表,分别存在于多个数据库,关联表 persona_address, 只存在于主服务数据库,这种方式就是在修改了persona_address表之后将这张表再复制一份到从数据库,这样查询的时候从从数据库关联后再汇总查询。
2. 从数据库实时同步主数据库,从主数据库查询。
spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现的更多相关文章
- mycat+mysql集群:实现读写分离,分库分表
1.mycat文档:https://github.com/MyCATApache/Mycat-doc 官方网站:http://www.mycat.org.cn/ 2.mycat的优点: 配 ...
- Mycat数据库中间件对Mysql读写分离和分库分表配置
Mycat是一个开源的分布式数据库系统,不同于oracle和mysql,Mycat并没有存储引擎,但是Mycat实现了mysql协议,前段用户可以把它当做一个Proxy.其核心功能是分表分库,即将一个 ...
- MyCat读写分离、分库分表
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- Mycat实现读写分离、分库分表
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- sharding demo 读写分离 U (分库分表 & 不分库只分表)
application-sharding.yml sharding: jdbc: datasource: names: ds0,ds1,dsx,dsy ds0: type: com.zaxxer.hi ...
- sharing-jdbc实现读写分离及分库分表
需求: 分库:按业务线business_id将不同业务线的订单存储在不同的数据库上: 分表:按user_id字段将不同用户的订单存储在不同的表上,为方便直接用非分片字段order_id查询,可使用基因 ...
- Mysql之Mycat读写分离及分库分表
## 什么是mycat ```basic 1.一个彻底开源的,面向企业应用开发的大数据库集群 2.支持事务.ACID.可以替代MySQL的加强版数据库 3.一个可以视为MySQL集群的企业级数据库,用 ...
- Ameba读写分离_mycat分库分表_redis缓存
1 数据库的读写分离 1.1 Amoeba实现读写分离 1.1.1 定义 Amoeba是一个以MySQL为底层数据存储,并对应用提供MySQL协议接口的proxy 优点: 配置读写分离时较为简单.配置 ...
- mysql主从读写分离,分库分表
1.分表 当项目上线后,数据将会几何级的增长,当数据很多的时候,读取性能将会下降,更新表数据的时候也需要更新索引,所以我们需要分表,当数据量再大的时候就需要分库了. a.水平拆分:数据分成多个表 b. ...
随机推荐
- C#高级编程笔记之第二章:核心C#
变量的初始化和作用域 C#的预定义数据类型 流控制 枚举 名称空间 预处理命令 C#编程的推荐规则和约定 变量的初始化和作用域 初始化 C#有两个方法可以一确保变量在使用前进行了初始化: 变量是字段, ...
- js基础进阶--关于Array.prototype.slice.call(arguments) 的思考
欢迎访问我的个人博客:http://www.xiaolongwu.cn Array.prototype.slice.call(arguments)的作用为:强制转化arguments为数组格式,一般出 ...
- selenium webdriver (python)的基本用法一
阅在线 AIP 文档:http://selenium.googlecode.com/git/docs/api/py/index.html目录一.selenium+python 环境搭建........ ...
- linux netlink通信机制
一.什么是Netlink通信机制 Netlink套接字是用以实现用户进程与内核进程通信的一种特殊的进程间通信(IPC) ,也是网络应用程序与内核通信的最常用的接口. Netlink 是一种特殊的 s ...
- capwap学习笔记——初识capwap(二)(转)
2.5.1 AC发现机制 WTP使用AC发现机制来得知哪些AC是可用的,决定最佳的AC来建立CAPWAP连接. WTP的发现过程是可选的.如果在WTP上静态配置了AC,那么WTP并不需要完成AC的发现 ...
- spring-security doc logout
18.5.3 Logging Out Adding CSRF will update the LogoutFilter to only use HTTP POST. This ensures that ...
- mime.go
package manager import ( "mime" "path" ) //初始化数据 func init() { if mi ...
- lease.go
package ) type:]...) :]...) )*time.Second) ) go func() { select { case <-stop ...
- 【bzoj 2916】[Poi1997]Monochromatic Triangles
题目描述 空间中有n个点,任意3个点不共线.每两个点用红线或者蓝线连接,如果一个三角形的三边颜色相同,那么称为同色三角形.给你一组数据,计算同色三角形的总数. 输入 第 ...
- BZOJ_3083_遥远的国度_树链剖分+线段树
BZOJ_3083_遥远的国度_树链剖分 Description 描述 zcwwzdjn在追杀十分sb的zhx,而zhx逃入了一个遥远的国度.当zcwwzdjn准备进入遥远的国度继续追杀时,守护神Ra ...