Hive:表1inner join表2结果group by优化
问题背景
最近遇到一个比较棘手的事情:hive sql优化:
lib表(id,h,soj,noj,sp,np) --一个字典表
mitem表(md,mt,soj,noj,sp,np)--一天的数据,包含小时分区的表。
业务:
1)需要先把lib表与mitem表进行关联(关联条件是lib.soj=mitem.soj and lib.noj=mitem.noj),关联后的结果按照soj,md,mt,id,h进行分组;
2)对1)中的结果在分组的时候需要统计差值的平均值记为svalue;
3)对关联后的分区的统计后的数据,进行一次分组排序:按照soj,md,mt分组,按照svalue排序,只保留同一个分组内排序第一的记录。
其中表lib有3亿条记录,mitem表包含记录数50~150亿左右,lib与mitem关联后的记录数在6000亿条记录,之后对这个关联后的结果进行进行分组却执行了6小时后抛出异常问题。
尝试解决方案
瓶颈主要体现在在对第一次关联后的记录包含了6000亿条记录进行分组时,耗费资源,资源不足导致的问题。
尝试过的解决方案:
1)创建索引:《hive:创建索引》
针对该6000亿条记录进行创建索引,耗费了20小时后依然是在stage2失败了,此方案推翻。
2)对mitem数据按照小时粒度进行数据拆分,之后每一个小时的mitem与lib进行关联,结果耗费时间为20多个小时,依然是抛出异常。
3)对mitem数据按照小时粒度进行分区,同时对lib表按照字段soj进行分页(分10页,一页中包含的lib记录数约3000w条)《hive:某张表进行分页》
create table lib_soj as select soj from lib group by soj;--记录数约为8000条记录
create table lib_soj_page as select row_number()over(order by soj)rnum,soj from lib_soj;
create table lib_1_1000 as select t10.* from lib t10 inner join lib_soj_page t11 on t10.soj=t11.soj where t11.rnum between 1 and 1000;--记录数约为3000w条记录。
此时,拿一个小时的select * from mitem where hour='2017102412' 与一个分页中的soj进行关联,数据终于出来了,可是耗费的时间为1小时20分,那么该总体时间为1.33*24*10小时。时间实际上太长了。
4)针对2)、3)的方案我们得知,如果把mitem查分带来的效果实际上是不大,而查分lib的效果特别明显,于是想到如果把lib查分的粒度更细与一天的mitem进行关联是否可行(这里是查分为20份,一份数据约为1500w)。
测试结果,耗时3小时20分,那么总体的时间约为3.33*20小时。如果并行执行多个分页的数据相信时间上会缩短。
但是目前这个方案应该是shuffle时出现了数据偏移问题:
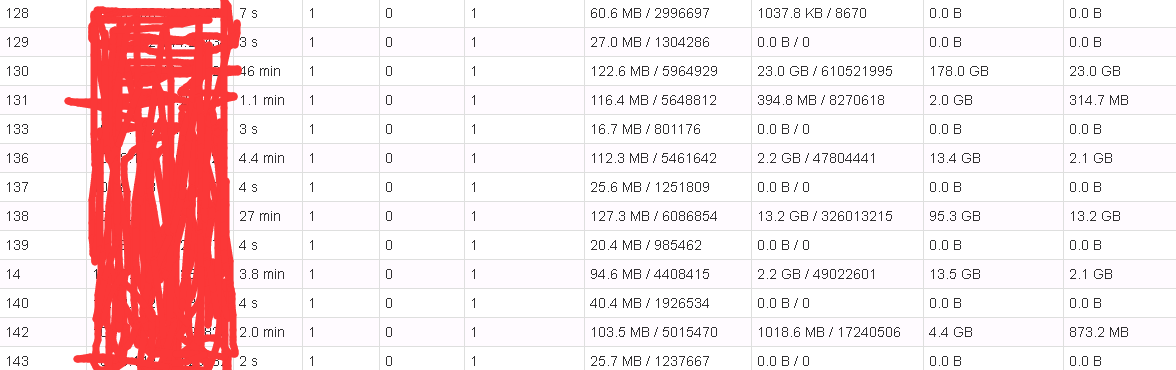
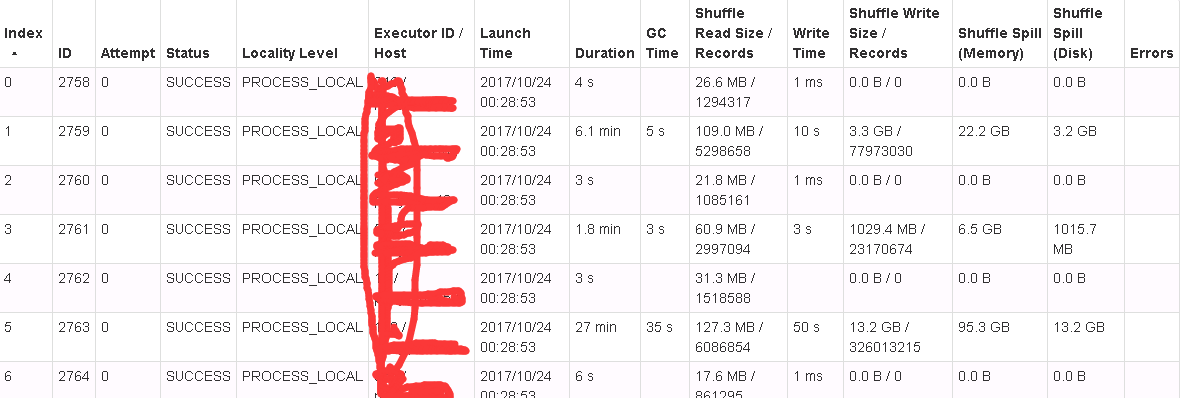
调优:
https://tech.meituan.com/spark-tuning-pro.html
提高shuffle并行度:
http://blog.csdn.net/u013939918/article/details/60956620
。
Hive:表1inner join表2结果group by优化的更多相关文章
- 十几张表的join(千万级/百万级表) 7hours-->5mins
================START============================== 来了一个mail说是job跑得很慢,调查下原因 先来看下sql: SELECT h.order_ ...
- python开发mysql:单表查询&多表查询
一 单表查询,以下是表内容 一 having 过滤 1.1 having和where select * from emp where id > 15; 解析过程;from > where ...
- Hive:有表A与表B进行inner join,如果A分组内包含有数据,使用A,否则使用B分组下的数据
tommyduan_fingerlib 指纹库 栅格小区级别数据tommyduan_mr_grid_cell_result_all 统计 栅格小区级别数据业务:以tommyduan_mr_grid_c ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Hive中小表与大表关联(join)的性能分析【转】
Hive中小表与大表关联(join)的性能分析 [转自:http://blog.sina.com.cn/s/blog_6ff05a2c01016j7n.html] 经常看到一些Hive优化的建议中说当 ...
- sql-多表查询JOIN与分组GROUP BY
一.内部连接:两个表的关系是平等的,可以从两个表中获取数据.用ON表示连接条件 SELECT A.a,B.b FROM At AS A INNER JOINT Bt AS B ON A.m=B.n ...
- hive regex insert join group cli
1.insert Insert时,from子句既能够放在select子句后,也能够放在insert子句前,以下两句是等价的 hive> FROM invites a INSERT OVERWRI ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
随机推荐
- 如何写对kubernetes的模板文件
kubernetes的模板配置文件随着版本更迭也会有相应的调整,正确配置模板关键字的方式是参考版本发布的doc,如下图 在docs\api-reference下面有不同功能的API目录,如下图 各个A ...
- Linux最佳的云存储服务分析
什么样的云服务才适合作为 Linux 下的存储服务?兄弟连www.itxdl.cn来帮大家分析一下! 大量的免费空间.毕竟,个人用户无法支付每月的巨额款项. 原生的 Linux 客户端.以便你能够方便 ...
- Gauge----自动化测试工具
* Gauge是一个自动化测试工具,主要是通过.spec 文件指定执行的步骤,然后由Java代码去测试 安装: * 安装插件 Gauge--install-all *在IDEA中安装Gauge插件 基 ...
- vuex的学习笔记
什么是Vuex? vuex是一个专门为vue.js设计的集中式状态管理架构.状态?我把它理解为在data中的属性需要共享给其他vue组件使用的部分,就叫做状态.简单的说就是data中需要共用的属性. ...
- 【Linux】 环境变量与shell配置&执行
■ 变量与环境变量 shell环境通常存在很多变量,变量可以通过echo $VAR或${VAR}的方式查看.set命令可以查看当前环境中的所有变量(包括一般的自定义变量和环境变量) 变量的设置通过简单 ...
- 手把手 git建立仓库,远程推拉及常用git命令和部分Linux命令集锦
方法一:直接在GitHub上建立一个项目,然后git clone (git address name): 此时已经建立好了一个git仓库: cd 文件夹 > 添加文件进去 >git add ...
- 转载:解决微信OAuth2.0网页授权回调域名只能设置一个的问题
项目地址:https://github.com/HADB/GetWeixinCode 说明:微信项目很多,但是回调域名有限,经常使用,做个笔记. 解决微信OAuth2.0网页授权只能设置一个回调域名的 ...
- Dynamics 365 for CRM:CRM与ADFS安装到同一台服务器,需修改ADFS服务端口号
CRM与ADFS安装到同一台服务器时,出现PluginRegistrationTool 及 CRM Outlook Client连接不上,需要修改ADFS的服务端口号,由默认的808修改为809: P ...
- 第六周PTA作业
第一题: #include<stdio.h> int main () { float a,b; scanf("%f %f\n",&a,&b); floa ...
- 《高级软件测试》web测试实践--12月30日记录
考完数学,我们正式开始web测试实践的作业,今天,我们主要进行了方案的选择和人员的分工.任务计划和安排如上图所示. 任务进展:完成题目选择和人员分工: 遇到问题:暂无: 下一步任务:完成软件评测.用户 ...