pyspider 文档介绍
一 代码区结构
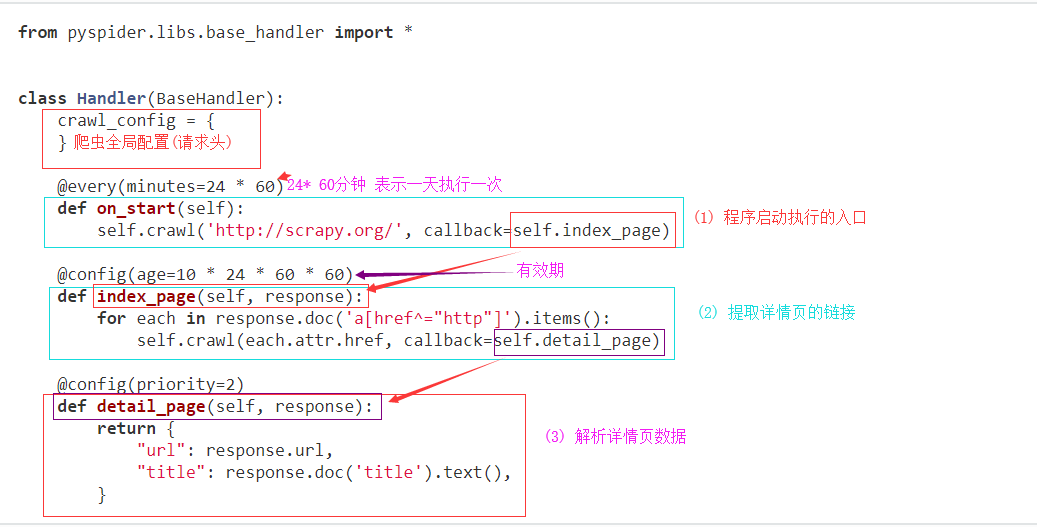
def on_start(self)是脚本的入口点。单击run仪表板上的按钮时将调用它。self.crawl(url, callback=self.index_page)*是这里最重要的API。它将添加一个要爬网的新任务。大多数选项将通过self.crawl参数进行spicified 。def index_page(self, response)得到一个Response*对象。response.doc*是一个pyquery对象,它具有类似jQuery的API来选择要提取的元素。def detail_page(self, response)返回一个dict对象作为结果。结果将resultdb默认捕获。您可以覆盖on_result(self, result)方法来自行管理结果。
您可能想知道的更多内容:
@every(minutes=24*60, seconds=0)*是告诉调度程序on_start应该每天调用方法的帮助程序。@config(age=10 * 24 * 60 * 60)*指定页面类型的默认age参数(when )。参数*可以通过(最高优先级)和(最低优先级)指定。self.crawlindex_pagecallback=self.index_pageageself.crawl(url, age=10*24*60*60)crawl_configage=10 * 24 * 60 * 60* tell scheduler会在10天内抓取该请求。pyspider默认情况下不会抓取同一个URL两次(永远丢弃),即使你修改了代码,对于第一次运行项目并修改它并第二次运行它的初学者来说很常见,它不会再次爬行(阅读itag解决方案)@config(priority=2)*标记应首先抓取详细信息页面。
二 配置启动文件
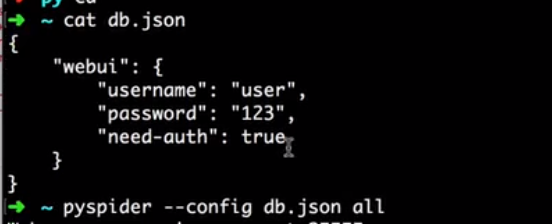
新建 '''db.json''' 配置文件,文件中
{
"taskdb": "mysql+taskdb://username:password@host:port/taskdb",
"projectdb": "mysql+projectdb://username:password@host:port/projectdb",
"resultdb": "mysql+resultdb://username:password@host:port/resultdb",
"message_queue": "amqp://username:password@host:port/%2F",
"webui": {
"username": "some_name",
"password": "some_passwd",
"need-auth": true
}
}
启动配置
pyspider --config db.json all
三 使用PhantomJS(自动执行js文件加载页面)
当连接PhantomJS的pyspider时,您可以通过添加参数fetch_type='js'来启用此功能self.crawl.
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://www.twitch.tv/directory/game/Dota%202',
fetch_type='js', callback=self.index_page)
页面执行js代码
滑动滑动条,加载整个数据
class Handler(BaseHandler):
def on_start(self):
self.crawl('http://www.pinterest.com/categories/popular/',
fetch_type='js', js_script="""
function() {
window.scrollTo(0,document.body.scrollHeight);
}
""", callback=self.index_page)
四 pypider 爬虫结构
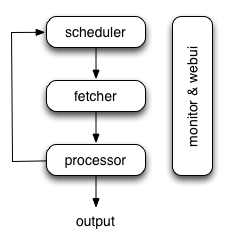
调度器:
调度程序从处理器的newtask_queue接收任务。确定任务是新任务还是需要重新爬网。根据优先级对任务进行排序,并将其提供给具有流量控制的提取器(令牌桶算法)。处理定期任务,丢失任务和失败的任务,然后重试。
提取器
Fetcher负责获取网页,然后将结果发送给处理器。对于灵活的,fetcher支持数据URI和由JavaScript呈现的页面(通过phantomjs)。可以通过API通过脚本控制获取方法,标头,cookie,代理,etag等。
处理器
处理器负责运行用户编写的脚本来解析和提取信息。您的脚本在无限制的环境中运行。虽然我们有各种工具(如PyQuery)可供您提取信息和链接,但您可以使用任何想要处理响应的内容。
执行流程
on_start当您按下RunWebUI上的按钮时,每个脚本都有一个名为callback的回调。将新任务on_start作为项目条目提交给Scheduler。
- Scheduler将此
on_start任务调度为数据URI作为Fetcher的常规任务。
- Fetcher发出请求并对其做出响应(对于数据URI,这是一个虚假的请求和响应,但与其他正常任务没有区别),然后提供给处理器。
- 处理器调用该
on_start方法并生成一些新的URL以进行爬网。处理器向Scheduler发送一条消息,告知此任务已完成,新任务通过消息队列发送到Scheduler(on_start在大多数情况下,这里没有结果。如果有结果,则处理器将它们发送给result_queue)。
- 调度程序接收新任务,在数据库中查找,确定任务是新的还是需要重新爬网,如果是,则将它们放入任务队列。按顺序发送任务。
- 这个过程重复(从第3步开始)并且在WWW死亡之前不会停止;-)。调度程序将检查定期任务以爬网最新数据。
五 self.crawl API
@config(age=10 * 24 * 60 * 60) 任务有效期
priority=1 优先级
exetime=time.time()+30*60 任务执行时间
auto_recrawl = True 自动爬取
params={'a': 123, 'b': 'c'} GET请求参数
method='POST' 请求方式 默认为GET
data={'a': 123, 'b': 'c'} post方式提交数据
{field: {filename: 'content'}} 分段执行文件
User-Agent ='Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36 '
cookies=' '
timeout=' '
allow_redirects=True 默认为false
fetch_type='js' 启用JavaScript fetcher
js_script=''' function() { window.scrollTo(0,document.body.scrollHeight); return 123; } ''' 在页面加载之前或之后运行的JavaScript
load_images 默认False
使用示例
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
age=5*60*60, auto_recrawl=True)
#get请求携带参数
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback,
params={'a': 123, 'b': 'c'})
self.crawl('http://httpbin.org/get?a=123&b=c', callback=self.callback)
#post请求携带参数
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback,
method='POST', data={'a': 123, 'b': 'c'})
#加在页面加载之前或之后运行的JavaScript
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
fetch_type='js', js_script='''
function() {
window.scrollTo(0,document.body.scrollHeight);
return 123;
}
''')
五 全局请求参数
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': 'GoogleBot',
}
'proxy': 'localhost:8080'
} ...
六 response 对象
Response.url 返回最终的url
Response.text返回最终的文本
Response.content 响应内容,以字节为单位。
Response.doc
一个PyQuery响应的内容的对象。链接默认为绝对链接。
请参阅PyQuery的文档:https://pythonhosted.org/pyquery/
Response.etree 一个LXML响应的内容的对象。
Response.json 响应的JSON编码内容(如果有)。
pyspider 文档介绍的更多相关文章
- spring-data-solr官方学习文档介绍
spring-data-solr文档介绍如下: 通过http://www.springframework.org/schema/data/solr/spring-solr-1.0.xsd(spring ...
- Docx组件读写Word文档介绍
Docx介绍 官方原文:DocX is a .NET library that allows developers to manipulate Word 2007/2010/2013 files, i ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- esdoc 自动生成接口文档介绍
原文地址:https://www.xingkongbj.com/blog/esdoc/creat-esdoc.html 官网 ESDoc:https://esdoc.org/ JSDoc:http:/ ...
- 【2】PRD文档介绍
首先,我想说,题主是一个不严肃的人(严肃脸),所以每次干个啥事之前我都喜欢唠唠嗑,说说废话,沟通沟通感情,曾经以为自己将会成为一个幻想中的产品经理那般大展身手,作为非计算机专业出身的应届生,后来才发现 ...
- PySide_Qt文档介绍
http://qt-project.org/wiki/PySideDocumentation/
- EasyUI文档学习心得
概述 jQuery EasyUI 是一组基于jQuery 的UI 插件集合,它可以让开发者在几乎完全不需要CSS以及复杂的JS代码情况下完成美观且功能强大的Web界面. 本文主要说明一些如何利用Eas ...
- [中文版] 可视化 CSS References 文档
本文分享了我将可视化 CSS References 文档翻译成中文版的介绍,翻译工作还在陆续进行中,供学习 CSS 参考. 1. 可视化 CSS References 文档介绍 许多 CSS 的文档都 ...
- LINUX 内核文档地址
Linux的man很强大,该手册分成很多section,使用man时可以指定不同的section来浏览,各个section意义如下: 1 - commands2 - system calls3 - l ...
随机推荐
- Mybatis配置文件SqlMapConfig.xml中的标签
SqlMapConfig.xml配置文件中的属性 1 配置内容 properties(属性) settings(全局配置参数) typeAliases(类型别名) typeHandlers(类型处理器 ...
- Tiny4412中断介绍
通过几天裸板驱动开发,今天对ARM的中断做一些简单总结,前面我们已经了解了ARM的7种异常模式,中断是异常模式的一种,在ARM中异常事件发生将会触发中断,但是,所有的中断都不能直接访问cpu,而是都统 ...
- Jmeter性能测试 如何利用SQLserver造出大批的数据
作为一个测试人员,需要做性能测试时候,如果没有实际数据,或者实际数据不适合做压测,就要自己着手造数据了. 以下面的接口测试为例,简单介绍下需要的数据: 这是一个会员注册接口,入参比较多,你可以选用全部 ...
- Android UI性能优化实战 识别绘制中的性能问题
转载请标明出处: http://blog.csdn.net/lmj623565791/article/details/45556391: 本文出自:[张鸿洋的博客] 1.概述 2015年初google ...
- 8. 使用ueditor添加文章
ueditor是一个很好用的html编辑器,不仅提供了格式化编辑文本的功能,还提供了自动上传图片的功能,现在就使用该编辑器来实现博客文章的编辑功能.1. 使用ueditor过程中会请求一个后台js文件 ...
- python获取日期加减之后的日期
python语言中的datetime模块可以利用其中的方法获取不同的日期,比如获取当前日期.明天.昨天.上个月.下个月和明年.下面利用几个实例说明这些日期的获取方法,操作如下: 第一步,利用d ...
- TestNG exception
以下内容引自: https://howtodoinjava.com/testng/testng-expected-exception-and-expected-message-tutorial/ Ho ...
- BZOJ_2788_[Poi2012]Festival_差分约束+tarjan+floyed
BZOJ_2788_[Poi2012]Festival_差分约束+tarjan+floyed Description 有n个正整数X1,X2,...,Xn,再给出m1+m2个限制条件,限制分为两类: ...
- Android 画文字图
画图 private Bitmap getbitmap(String content) { Bitmap bitmap = Bitmap.createBitmap(400, 400, Bitmap.C ...
- 电梯调度二——曹玉松&&蔡迎盈
电梯初步版本 经过去实际大楼的调查和一周的学习,初步完成了电梯的制作,但是这个版本的电梯功能并不是很全面,而且界面有待于改善,现在做出了测试版本,稍后进一步跟进新的版本,现在的版本初步完成的是电 ...