Lucene 初步 之 HelloWorld
万恶的源头 HelloWorld
要完成lucene 的配置 需要几个jar包 (如果需要可以留言我私发)
创建索引API分析:
1. Directory: 类代表一个Lucene索引的位置,FSDirectory:它表示一个存储在文件系统中的索引的位置
2. Analyzer 类是一个抽象类, 它有多个实现,在一个文档被入索引库之前,首先需要对文档内容进行分词处理,针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引
3. IndexWriter:是创建索引和维护索引的中心组件, 这个类创建一个新的索引并且添加文档到一个已有的索引中。IndexWriter只负责索引库的更新(删、更新、插入),不负责查询
4. Document:由多个字段(Field)组成,一个Field代表与这个文档相关的元数据。如作者、标题、主题等等,分别做为文档的字段索引和存储。add(Fieldable field)添加一个字段(Field)到Document
Store,Index介绍
|
枚举类型 |
枚举常量 |
说明 |
|
Store |
NO |
不存储属性的值 |
|
YES |
存储属性的值 |
|
|
Index |
NO |
不建立索引 |
|
ANALYZED |
分词后建立索引 |
|
|
NOT_ANALYZED |
不分词,把整个内容作为一个词建立索引 |
说明:Store是影响搜索出的结果中是否有指定属性的原始内容。Index是影响是否可以从这个属性中查询(No),或是查询时可以查其中的某些词(ANALYZED),还是要把整个内容作为一个词进行查询(NOT_ANALYZED)。
搜索原理图分析:
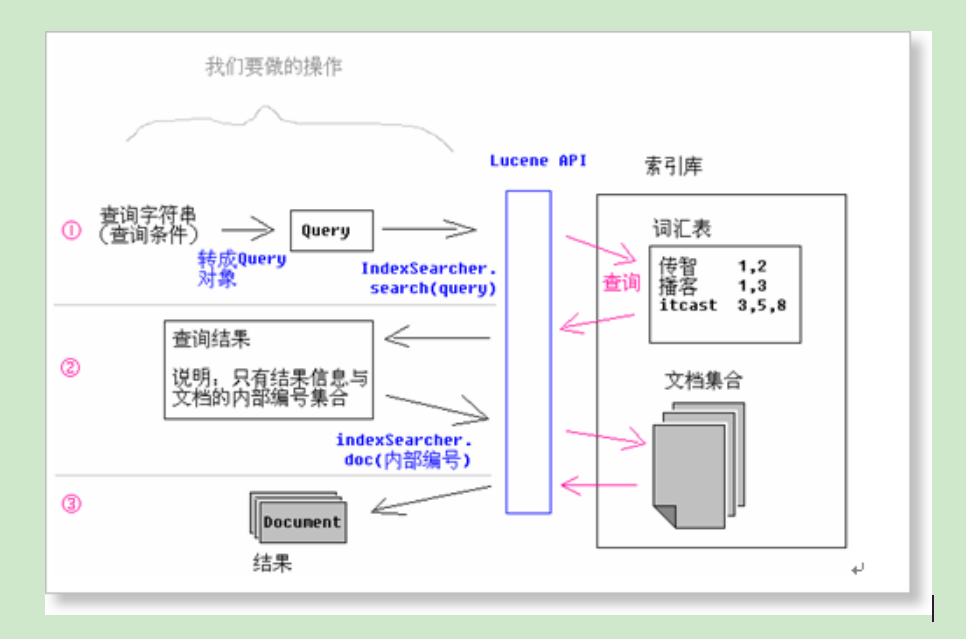
这时我们假设 把商品添加到索引库
public void saveGoods(Goods goods) {
//创建一个indexWrite
IndexWriter indexWriter = null;
//指定索引库的目录
Directory directory = null;
//创建一个分词器
Analyzer analyzer = null;
try {
//不同分词器,分词的效果不同
analyzer = new StandardAnalyzer(Version.LUCENE_30);
//目录可以任意指定,最好和项目同级目录
directory= FSDirectory.open(new File("./indexData"));
//通过分词器和索引创建indexWrite
indexWriter=new IndexWriter(directory,analyzer, IndexWriter.MaxFieldLength.LIMITED);
//把Goods 转化成lucene可以识别的doument
Document doc=new Document();
//Goods 对象中的,每个属性,转化lucene 中的字段
doc.add(new Field("gid",goods.getGid().toString(), Store.YES,Index.NOT_ANALYZED));
doc.add(new Field("gname",goods.getGname(), Store.YES,Index.ANALYZED));
doc.add(new Field("gprice",goods.getGprice().toString(), Store.YES,Index.NOT_ANALYZED));
doc.add(new Field("gremark",goods.getGremark(), Store.YES,Index.ANALYZED));
//把document添加到索引库
indexWriter.addDocument(doc);
//提交
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}finally {
try {
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
商品的实体类
package cn.wh; import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors; //有参构造函数
@AllArgsConstructor
//无参构造函数
@NoArgsConstructor
//封装
@Data
//链式风格访问
@Accessors(chain = true)
public class Goods implements java.io.Serializable {
// Fields
private Integer gid;
private String gname;
private Double gprice;
private String gremark; }
这时我们执行会产生一个索引的库
这时我们再创建一个查询的方式 (根据商品名查询)
public List<Goods> query(String gname){
List<Goods> goodsList=new ArrayList<Goods>();
// 创建查询工具类
IndexSearcher indexSearcher=null;
// 指定Lucenen索引库目录
Directory directory=null;
// 创建一个分词器
Analyzer analyzer=null;
try {
// 指定查询的目录
directory=FSDirectory.open(new File("./indexData"));
// 指定查询的分词器: 钓鱼岛中国的---> 钓鱼 钓鱼岛 中国
analyzer=new StandardAnalyzer(Version.LUCENE_30);
// QueryParser:查询解析器,用来解析查询的字符串,和分词
/*
* Version.LUCENE_30:版本号
* gname: 要查询的 字段名 Term:key,后面可以到多个字段中查找
* analyzer:指定对关键字的分词器
* */
QueryParser parse=new QueryParser(Version.LUCENE_30,"gname",analyzer);
// 解析要查询的关键字:返回的是Query类型
Query query=parse.parse(gname);
indexSearcher=new IndexSearcher(directory);
// indexSearch做查询操作: n 用户期望查询结果数,后面做分页使用
TopDocs topDocs=indexSearcher.search(query,10);
/*
* TopDocs:
* totalHits: 实际查询到的结果数
* scoreDocs[]: 存储了所有符合条件的document 编号
* */
System.out.println("实际的结果数为:" + topDocs.totalHits);
// 存储的是document在lucenen中的逻辑编号
ScoreDoc[] docs=topDocs.scoreDocs; //[0]=0 [1]=1
/*
* ScoreDoc:
* doc: 文档逻辑编号
* score: 当前文档得分
*
* */
for(int i=0;i<docs.length;i++){
System.out.println("文档的编号:" + docs[i].doc);
System.out.println("此文档的得分:" + docs[i].score);
// 通过文档的编号获取真正的文档
Document doc=indexSearcher.doc(docs[i].doc);
// 把Document类型转化我们自己识别的类型
Goods goods=new Goods();
goods.setGid(Integer.parseInt(doc.get("gid")));
goods.setGname(doc.get("gname"));
goods.setGprice(Double.parseDouble(doc.get("gprice")));
goods.setGremark(doc.get("gremark"));
goodsList.add(goods);
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
return goodsList;
}
最后测试
可以根据hello 查询出来东西

这时 lucence 提供了一个jar 包 这个jar包是可以看见索引文件中的元素模样
在cmd 输入 java -jar XXXX jar包的名 (如果要这个jar 包 可以留言 我私法)
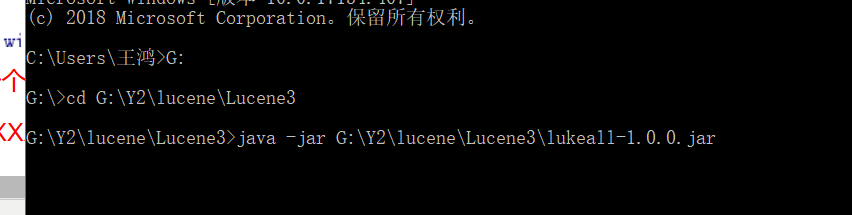
打开一个客户端 这时 在path中输入索引文件夹的位置
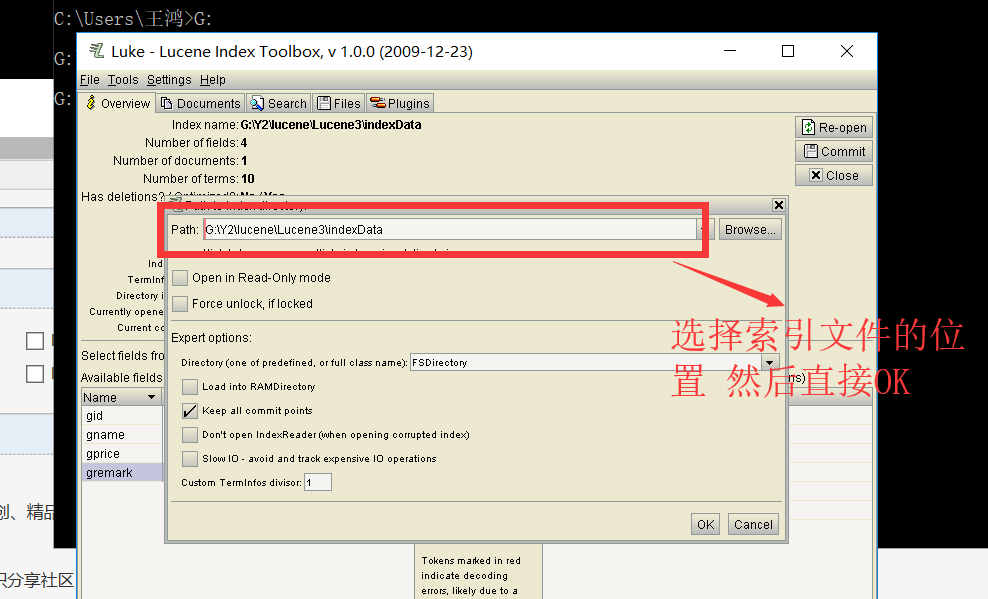
就能看见每个分词的效果就大小和索引
Lucene 初步 之 HelloWorld的更多相关文章
- Lucene初步搜索
Lucene在创立索引后,要进行搜索查询 搜索大概需要5部, 1,读取索引. 2,查询索引. 3,匹配数据. 4,封装匹配结果. 5,获取需要的值. 语言表达能力不好,大概就是分着几部吧. /** * ...
- Lucene之删除索引
1.前言 之前的博客<Lucene全文检索之HelloWorld>已经简单介绍了Lucene的索引生成和检索.本文着重介绍Lucene的索引删除. 2.应用场景: 索引建立完成后,因为有些 ...
- Socket网络通信编程(二)
1.Netty初步 2.HelloWorld 3.Netty核心技术之(TCP拆包和粘包问题) 4.Netty核心技术之(编解码技术) 5.Netty的UDP实现 6.Netty的WebSocket实 ...
- 搜索引擎系列 ---lucene简介 创建索引和搜索初步
一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎 :Lucene得名于Doug妻子 ...
- lucene简介 创建索引和搜索初步
lucene简介 创建索引和搜索初步 一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引 ...
- Lucene索引的初步创建
从百度上知道的,Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的 ...
- Lucene学习之初步了解
全文搜索 比如,我们一个文件夹中,或者一个磁盘中有很多的文件,记事本.world.Excel.pdf,我们想根据其中的关键词搜索包含的文件.例如,我们输入Lucene,所有内容含有Lucene的文件就 ...
- SpringMVC初步——HelloWorld的实现
开通博客园好几个月了,今天开始要用博客园记录自己的学习过程! 目录: 导包: 1. 配置web.xml文件的springDispatcherServlet 在xml中 alt+/ 找到springdi ...
- Lucene 搜索的初步探究
搜索应用程序和 Lucene 之间的关系 一般的搜索引擎都会采用这样的 Lucene 采用的是一种称为反向索引(inverted index)的机制.反向索引就是说我们维护了一个词 / 短语表,对于这 ...
随机推荐
- Android开发:带动画的分享效果
这几天做了个带动画的分享页面.如今把它分享出来,假设你认为实用,请直接使用,避免反复造轮子 先看下效果图 认为仅仅是看效果图不明显.那么用手机扫描以下的二维码下载安装包:
- JavaScript闭包和this绑定
本文最主要讲讲JavaScript闭包和this绑定相关的我的小发现,鉴于这方面的基础知识已经有很多很好的文章讲过了,所以基本的就不讲了,推荐看看[酷壳](http://coolshell.cn/)上 ...
- tools-eclipse-002-常用插件
1.spring 查看eclipse版本 下载对应版本插件包Spring Tool Sute 地址:http://spring.io/tools/sts/all 离线包只列举了最新的,如图, 如果ec ...
- 汇智课堂 Node.js相关课程
Node.js入门 Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台, 用来方便地搭建快速的 易于扩展的网络应用· Node.js 借助事件驱动, 非阻塞I/O 模型 ...
- jQuery异步加载数据并添加事件示例
当时项目是通过树形栏进行权限控制的,管理员可以对从数据库去的数据动态生成树形栏进行增删改查操作,可是用$(".XX").click();方法是不行的. 1.之前用的是jq1.4.3 ...
- 马尔可夫随机场(Markov random fields) 概率无向图模型 马尔科夫网(Markov network)
上面两篇博客,解释了概率有向图(贝叶斯网),和用其解释条件独立.本篇将研究马尔可夫随机场(Markov random fields),也叫无向图模型,或称为马尔科夫网(Markov network) ...
- linxu系统压缩解压命令
使用cat命令进行文件的纵向合并 两种文件的纵向合并方法 归档文件和归档技术 归档的目的 什么是归档 tar命令的功能 tar命令的常用选项 使用tar命令创建.查看及抽取归档文件 使用tar命令创建 ...
- hihocoder1479 三等分
地址:http://hihocoder.com/problemset/problem/1479 题目: 三等分 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi最近 ...
- 基于Python操作redis介绍
(注:本文部分内容摘自互联网,由于作者水平有限,不足之处,还望留言指正.) 毕业前的最后一个学期(2016.03),龙哥结婚了.可是总有些人喜欢嘲笑别人,调侃我.当时我就理直气壮的告诉他们,等龙哥孩子 ...
- springbcloud5----高可用
package com.itmuch.cloud; import org.springframework.boot.SpringApplication; import org.springframew ...